Rate Limiting: SLA-Based Policy
Policy name |
Rate-limiting SLA |
Summary |
Monitors access to an API by defining the maximum number of requests processed within a timespan, based on SLAs |
Category |
Quality of Service |
First Omni Gateway version available |
v1.2.0 |
Returned Status Codes |
401 - Request blocked due to invalid client credentials (client ID or client secret) provided |
429 - Quota exceeded; requests blocked until the current window finishes |
Summary
The Rate-Limiting Service Level Agreement (SLA) policy enables you to control incoming traffic to an API by limiting the number of requests that the API can receive within a given timespan. When the limit is reached before the time expires, the policy rejects all requests, thereby avoiding any additional load on the backend API.
To apply the Rate-Limiting SLA policy to an API, you must first create a contract between the API and a registered client application. The number of requests that an API can receive within a given time is defined in the contracts section in API Manager.
Each request must be identified by a client ID and an optional client secret (depending on the policy configuration). To review how to obtain the client credentials of a registered client application, see Obtaining Client Credentials of a Registered Application.
|
A Rate-Limiting SLA policy applied to an Omni Gateway API is scoped to replicas, not the gateway. |
Configuring Policy Parameters
Managed Omni Gateway and Omni Gateway Connected Mode
When you apply the policy from the UI, the following parameters are displayed:
| Parameter | Description | Example |
|---|---|---|
Client ID Expression |
A DataWeave expression that resolves the Client Application’s ID for a Contract of the API |
Only one rate-limiting algorithm is created per ID:
|
Client Secret Expression |
A DataWeave expression that resolves the Client application’s client secret for a contract of the API |
This is an optional value.
Example: |
Distributed |
When enabled, the quota is shared among Omni Replicas |
Checked or unchecked |
Expose Headers |
Defines whether to expose the x-ratelimit headers, as part of the response |
Checked or unchecked |
Block on unknown quota |
For policies using distributed rate limiting, block requests if the policy can’t retrieve the quota from shared storage. If not enabled and the quota can’t be retrieved, no rate limiting is applied. |
Checked or unchecked |
| If you enable the distributed rate limiting, the policy resizes time windows under 10 seconds linearly. For example, if you configure a maximum of 10 requests per 5 seconds, the policy resizes that window to a maximum of 20 requests per 10 seconds. |
Enable Shared Storage
Distributed Rate-Limiting requires Shared Storage to be enabled. For more information about Shared Storage, refer to Configuring Shared Storage for Omni Gateway in Connected Mode.
How This Policy Works
The Rate-Limiting SLA policy monitors the number of requests made in the current window (the available quota), allowing the requests to reach the backend only if the available quota is greater than zero.
Because each client defines a separate available quota for their window, the client application must define an SLA with the API (a contract). Therefore, to verify whether the request is within the SLA limit, you must define a way to obtain the client ID from the request, and optionally the client Secret.
After a contract is created between a client application and an API, API gateway automatically manages these contracts by monitoring your API Manager configurations. Additionally, API gateway implements high-availability strategies in case of unexpected downtime in the Anypoint Platform management plane.
To understand how the Rate-Limiting SLA policy works, consider an example in which the configuration of an SLA of 3 requests every 10 seconds for the client with ID “ID#1” allows or restricts the request, based on the quota available in that window:
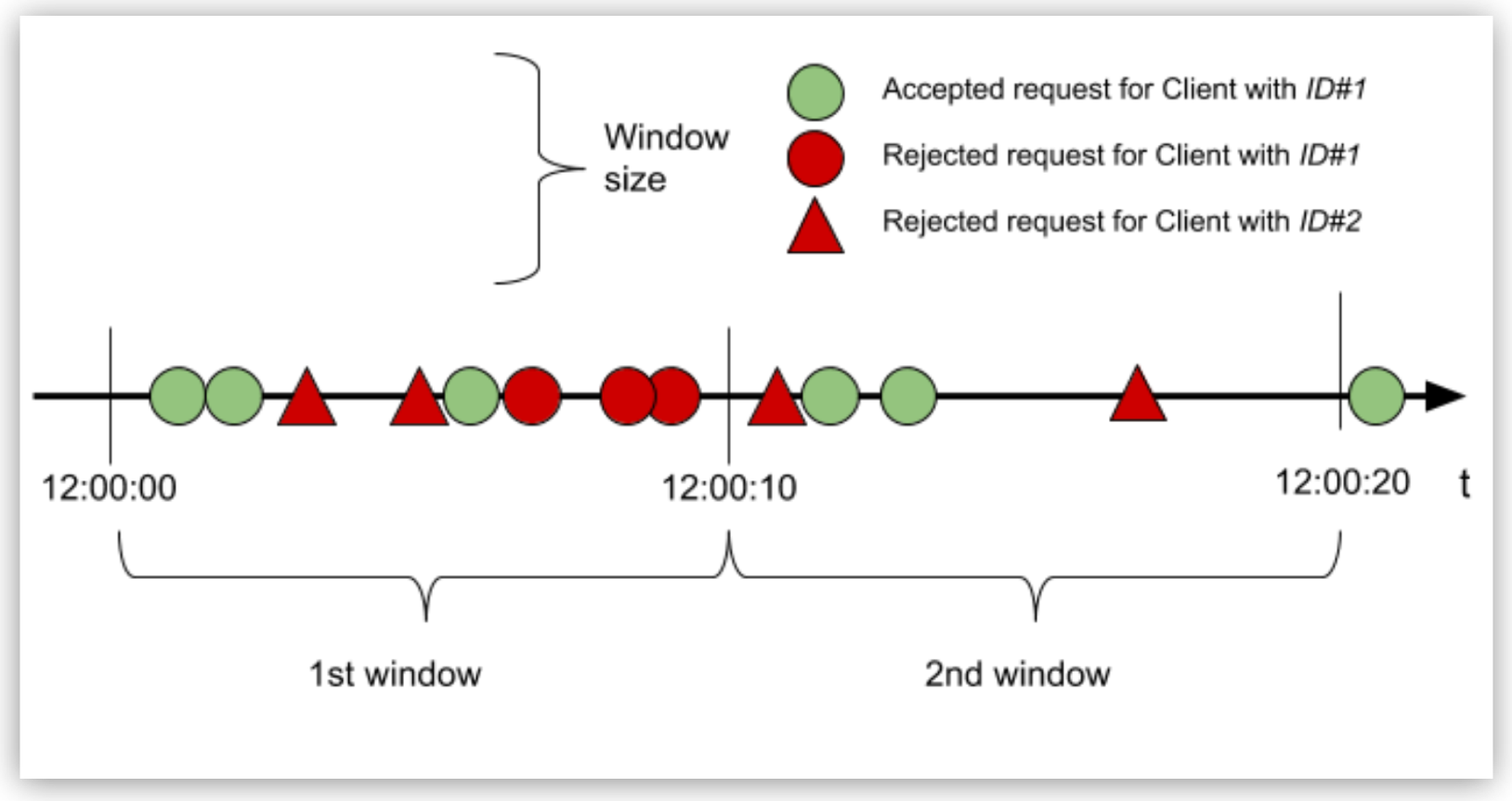
In the example:
-
Requests of client with ID “ID#1”:
In the first window, because the quota is reached with the third request, all subsequent requests are rejected until the window closes. In the second window, only two of the three requests are processed. Because the time elapses in this window, the remaining quota is unused.
An accepted request passes through the API to the backend. Conversely, a rejected request displays a 429 status for HTTP (or 400, or 500 if the API is WSDL) and does not reach the backend.
-
Requests of Client with ID “ID#2”:
Because the client has no contract defined for the API, every request is rejected , and therefore no request is allowed.
An API might have several contracts, each with its own SLA. The Rate-Limiting SLA policy independently monitors the quota (and windows) available for each client by creating one rate-limiting algorithm per contract. With the first request to the API, algorithms are created using the lazy creation strategy.
FAQ
When does the window start?
The window starts with the first request after the policy is successfully applied.
What type of window does the algorithm use?
It uses a fixed window.
What happens when the quota is exhausted?
The algorithm is created on demand, when the first request is received. This event fixes the time window. Each request consumes the request quota from the current window until the time expires.
When the request quota is exhausted, the Rate-Limiting SLA policy rejects the request. When the time window closes, the request quota is reset and a new window of the same fixed size starts.
What happens if I define multiple limits within an SLA ?
The policy creates one algorithm for each Limit with the request quota per time window configuration. Therefore, when multiple limits are configured, every algorithm must have its own available quota within the current window for the request to be accepted.
What does each response header mean?
Each response header has information about the current state of the request:
-
X-Ratelimit-Remaining: The amount of available quota
-
X-Ratelimit-Limit: The maximum available requests per window
-
X-Ratelimit-Reset: The remaining time, in milliseconds, until a new window starts
By default, the X-RateLimit headers are disabled in the response. You can enable these headers by selecting Expose Headers when you configure the policy.
|
When on distributed mode, the X-Ratelimit-Remaining header is not perfectly synchronized with all the replicas. With multiple replicas on distributed mode, the X-Ratelimit-Remaining header is an estimation of how much quota the replica has available for itself. It does not represent the actual value of the remaining quota available for the API. The following describes a valid scenario:
This does not mean that the quota will be surpassed. |
When should I use Rate Limiting instead of Rate-Limiting SLA or Spike Control?
Use Rate Limiting and Rate-Limiting SLA policies for accountability and to enforce a hard limit to a group (using the identifier in Rate Limiting) or to a client application (using Rate Limiting-SLA). If you want to protect your backend, use the Spike Control policy instead.