LLM Proxy Overview
LLM Proxy provides a unified access layer for multiple Large Language Model (LLM) providers. LLM Proxies are deployed to Omni Gateway to enable governance, intelligent routing, and cost management for AI applications.
LLM Proxy is supported on Managed Omni Gateway and Self-Managed Omni Gateway running in Connected Mode.
By creating a proxy, the user defines a singular LLM service that can receive requests for multiple providers. This simplifies the developer experience. You can add new models to the service seamlessly without changing the endpoint.
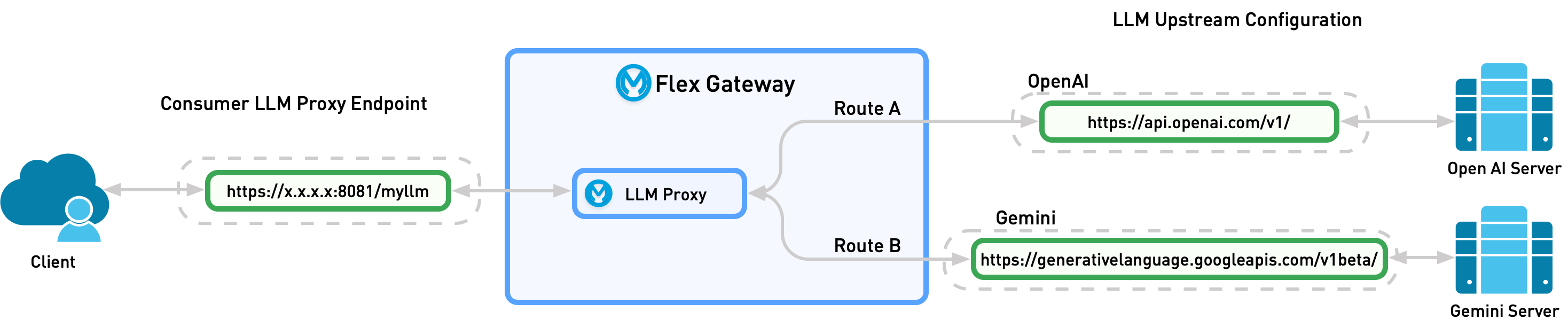
Depending on configuration, the proxy then sends the request to the model defined by the user or dynamically sends the request to the provider that best matches the request:
-
Model-Based Routing: Static routing. The user specifies what model the LLM Proxy should send the request to.
-
Semantic Routing: Dynamic routing. The LLM Proxy chooses which model to send the request to based on the request content.
Supported LLM Providers
LLM Proxy supports these LLM Providers and API endpoints:
| LLM Provider | Model | /chat/completions |
/responses |
|---|---|---|---|
OpenAI and Azure OpenAI |
gpt-5.2 |
Yes |
Yes |
gpt-5.2-pro |
Yes |
Yes |
|
gpt-5-mini |
Yes |
Yes |
|
gpt-5.2-codex |
Yes |
Yes |
|
gpt-5-nano |
Yes |
Yes |
|
gpt-5 |
Yes |
Yes |
|
gpt-4.1 |
Yes |
Yes |
|
gpt-4o-mini |
Yes |
Yes |
|
Gemini |
gemini-3-flash-preview |
Yes |
Yes |
gemini-2.5-flash |
Yes |
Yes |
|
gemini-2.5-flash-preview-09-2025 |
Yes |
Yes |
|
gemini-2.5-flash-lite |
Yes |
Yes |
|
Bedrock (Anthropic Claude models) |
Claude Sonnet 4.6 |
Yes |
Yes |
Claude Opus 4.6 |
Yes |
Yes |
|
Claude Opus 4.5 |
Yes |
Yes |
|
Claude Haiku 4.5 |
Yes |
Yes |
|
Claude Sonnet 4.5 |
Yes |
Yes |
|
Claude Opus 4 |
Yes |
Yes |
|
Claude Sonnet 4 |
Yes |
Yes |
|
Claude Sonnet 3.7 |
Yes |
Yes |
|
Claude Sonnet 3.5 |
Yes |
Yes |
|
Claude Haiku 3.5 |
Yes |
Yes |
|
NVIDIA Nemotron |
Nemotron 3 Nano 30B A3B |
Yes |
Yes |
Nemotron 3 Super 120B A12B |
Yes |
Yes |
|
Llama Nemotron Ultra 253B |
Yes |
Yes |
Model-Based Routing
Model-based routing is static routing. In the request, the user specifies what model the LLM Proxy should send the request to. By specifying a target model, LLM Proxy can override the model version provided by the user.
Semantic Routing
Semantic routing is dynamic routing where the LLM Proxy chooses which model to send the request to. For Sematic Routing, the user creates prompt topics for each route. When a request is sent to the LLM Proxy, a semantic service compares the request to the define topic utterances and sends the request to the route that best matches it.