Runtime Fabric アーキテクチャ
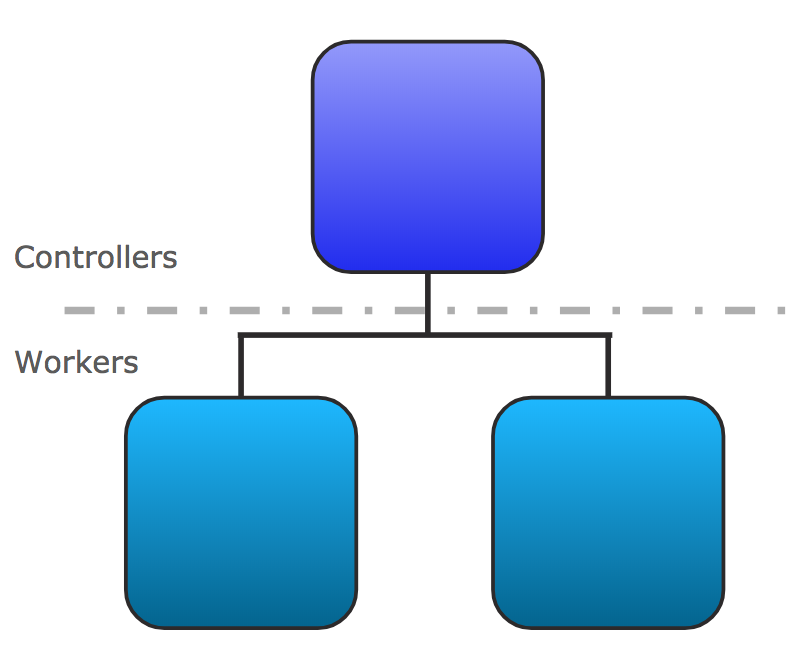
Anypoint Runtime Fabric は、クラスターを形成する一連の VM で構成されます。各 VM サービスは、コントローラーノードまたはワーカーノードのいずれかとして機能します。
-
コントローラー: オーケストレーションサービス、分散型データベース、負荷分散、および Anypoint Platform からクラスターを管理できるサービスを含む、Runtime Fabric の運用専用の VM。
-
ワーカー: Mule アプリケーションと API ゲートウェイの実行専用の VM。Mule アプリケーションと API プロキシはワーカーで動作します。
この責務の分離により、Mule アプリケーションの数に基づいてワーカーノードを拡張できます。また、デプロイメントの頻度、アプリケーションの状態の変化、およびインバウンドトラフィックの量に基づいて、コントローラーノードを拡張することもできます。ハードウェア障害が発生した場合にリソースを使用可能にしてアプリケーションを再スケジュールおよび再デプロイするため、ワーカーノードの数を多めにプロビジョニングすることをお勧めします。
デフォルトでは、Runtime Fabric を運用するサービスは、システム内で障害が 1 か所に集中することを防ぐためにコントローラーノード全体にデプロイされます。
Anypoint Runtime Fabric は、Mule Runtime で適切に動作するように調整された一連のテクノロジー (Docker や Kubernetes など) を使用します。Mule を Runtime Fabric にデプロイしたり管理したりするために、これらのテクノロジーに関する知識は必要ありません。Runtime Fabric の管理には、あらゆる規模のシステムをサポートするために必要な運用レベルおよびインフラストラクチャレベルの経験が必要です。予期せぬ障害に備えて、ベストプラクティスに従い、制御された環境で演習シナリオを実行することをお勧めします。
| Anypoint Runtime Fabric での Mule が提供していないアプリケーションやゲートウェイのデプロイメントはサポートされていません。 |
開発設定と本番設定
Anypoint Runtime Fabric は、開発設定と本番設定をサポートしています。これらのサポート対象設定で、最小限必要なノードとリソースを指定します。
開発設定
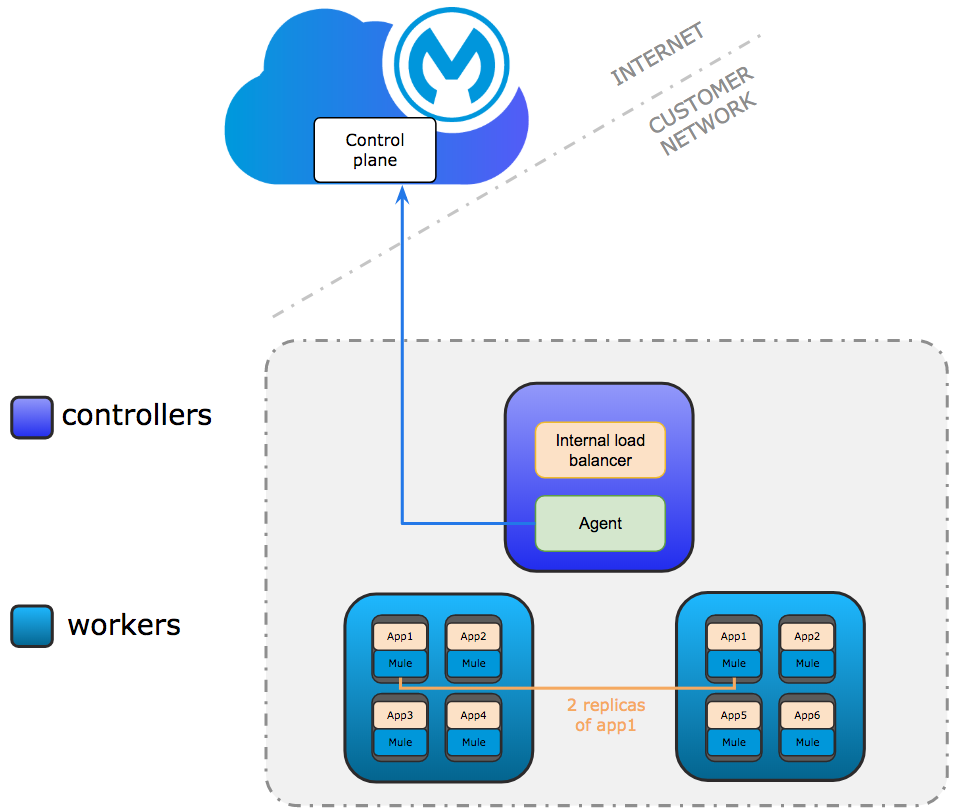
開発設定はテストのみを目的としています。少なくとも 1 つのコントローラーと 2 つのワーカーノードが必要です。コントローラーノードは、Anypoint Platform への接続に使用される内部ロードバランサーとエージェントを実行します。エージェントと Anypoint Platform 間の通信は常にアウトバウンドです。アプリケーションの複数のレプリカを複数のワーカーで実行できます。
本番設定
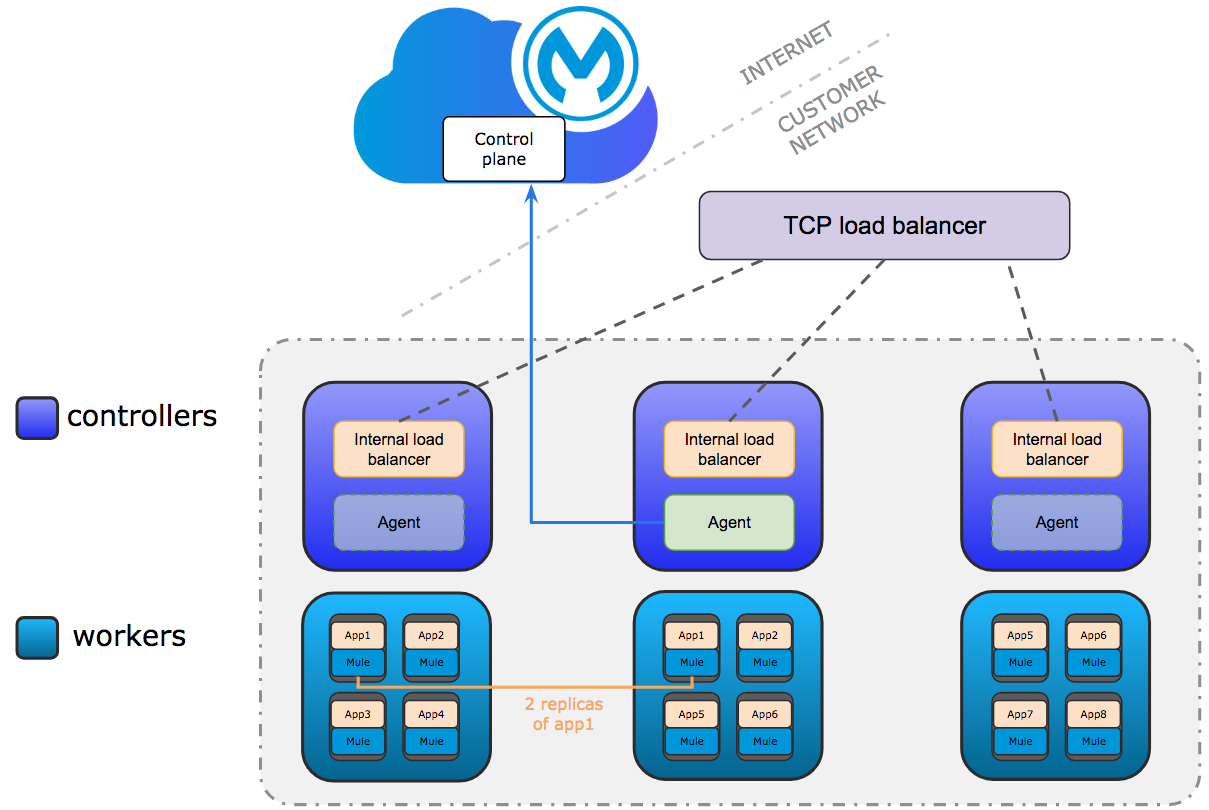
コントローラーのみが、Anypoint Platform への接続に使用される内部ロードバランサーとエージェントを実行します。
エージェントは任意のコントローラーで実行できます。エージェントの通信は常にアウトバウンドです。
最小要件は、3 つのコントローラーと 3 つのワーカーノードです。3 つのコントローラーにより、1 つのコントローラーが失われた場合のフォールトトレランスが可能になります。2 つのコントローラーが失われた場合のフォールトトレランスを可能にするには、合計 5 つのコントローラーを設定する必要があります。
Mule アプリケーションはワーカーで実行されます。アプリケーションの複数のレプリカを複数のワーカーで実行できます。
スケーリングの考慮事項
-
最低限必要なコントローラーノードの数
-
本番環境: 3
-
本番以外の環境: 1
-
-
サポートされるコントローラーノードの最大数は 5 です。
| フォールトトレランスを確保するには、奇数のコントローラーノードが必要です。 |
+ 次のような状況では、コントローラーノードの数をスケールすることを検討してください。
-
コントローラーノードのハードウェア障害の影響を軽減するためにフォールトトレランスが必要である。
-
Runtime Fabric で実行されているアプリケーションで本番トラフィックが処理されている。
-
コントローラーノードに必要な CPU/メモリ
-
デフォルト (必要最低限) は、それぞれ 2 コア、8 GB メモリです。コントローラーノードのサイズを変更する場合、内部ロードバランサーに必要なリソース量を検討する必要があります。詳細は、「内部ロードバランサー」のリソースの割り当てを参照してください。
-
-
必要なワーカーノードの数。サポートされるワーカーノードの最大数は 16 です。
-
本番環境: 3
-
本番以外の環境: 2
-
-
| フォールトトレランスを確保したり、アップグレードの適用時にアプリケーションのダウンタイムを回避したりできるように、ワーカーノードを 1 つ余分にプロビジョニングします。 |
-
ワーカーノードに必要な CPU/メモリ
-
デフォルト (必要最低限) は、それぞれ 2 コア、15 GB メモリです。Runtime Fabric で実行する Mule およびトークナイザーの数や、デプロイするためにどのようなライセンスを付与するのかを検討する必要があります。オーバーヘッドのためにワーカーノードあたり約 0.5 コアを計画します。
-
ネットワークアーキテクチャ
次の図は、Runtime Fabric の一般的なネットワークアーキテクチャを示しています。
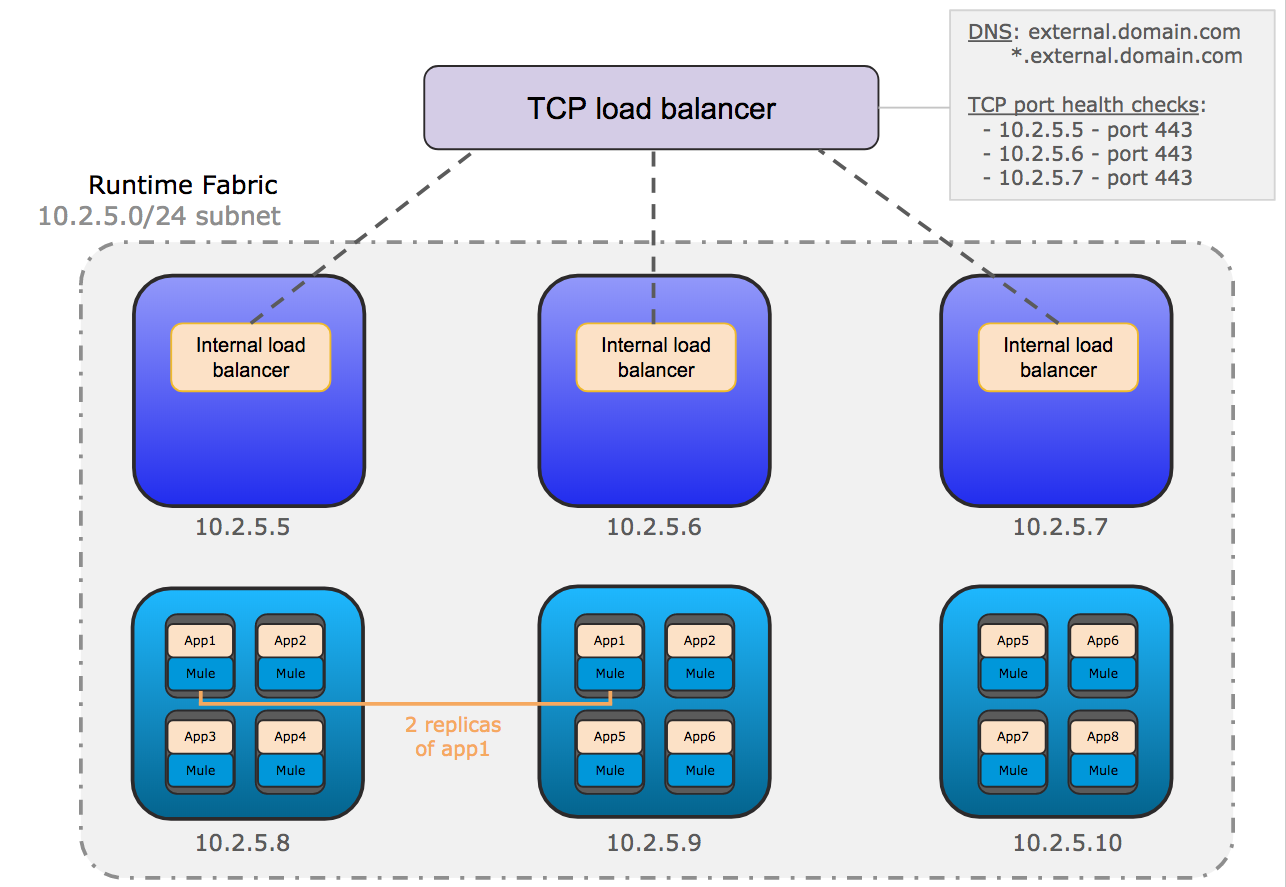
この図は、コントローラーで実行される内部ロードバランサー間で要求を負荷分散するために使用される、TCP ロードバランサーを示しています。また、ワーカーで実行される Mule アプリケーションの各レプリカに要求を分散する内部ロードバランサーも示しています。
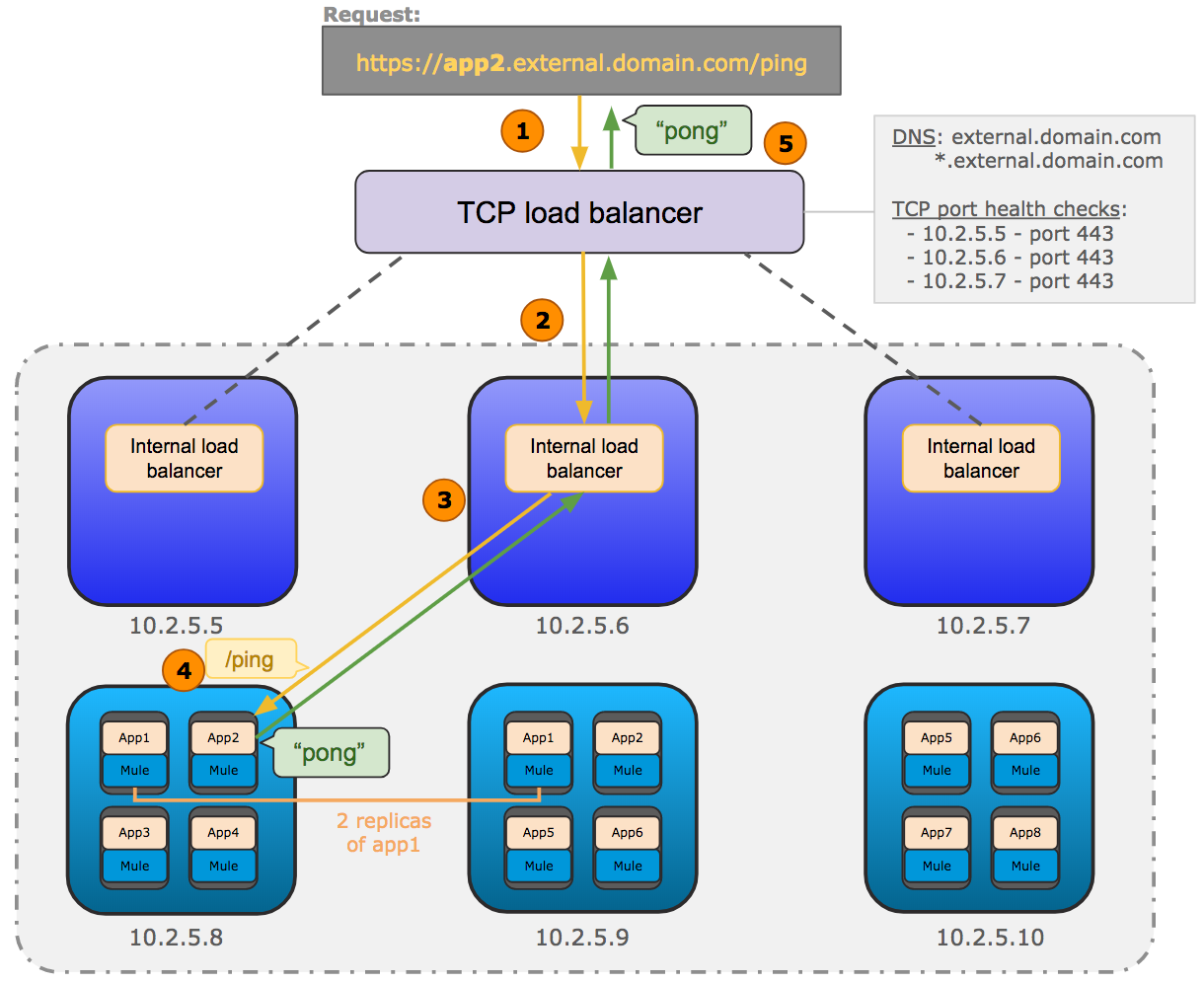
-
受信 HTTP 要求は外部 TCP ロードバランサーに転送されます。
-
TCP ロードバランサーは、Runtime Fabric で使用可能な内部ロードバランサーに要求を転送します。
-
内部ロードバランサーは要求を復号化し、上の図の Mule アプリケーション (app2) の使用可能なレプリカに転送します。
-
アプリケーションはリクエスターに返送される応答を送信します。
インストーラーのライフサイクル
Runtime Fabric を確実に運用するには、ドキュメント化されたシステム要件に基づいてインフラストラクチャを割り当てることが重要です。最小要件が満たされていない場合、インストールプロセスは失敗します。
AWS および Azure プロビジョニングスクリプトのデフォルトの動作では、最小要件によって定義された一連の仮想マシンとディスクが作成されます。また、必要なネットワークポートが設定されたプライベートネットワークも作成されます。これは、プライマリネットワーク内に統合する前に Runtime Fabric を評価する場合に最適です。デフォルトの動作に互換性があるかどうかを判断するには、ネットワーク管理者にお問い合わせください。組織の要件に合わせてプロビジョニングスクリプトの変更が必要な場合があります。
Anypoint Runtime Fabric の実行に必要なディスクは、次のために使用されます。
-
各コントローラー VM は、etcd 分散型データベースを実行するために 3000 IOPS 以上で最小 60 GiB の専用ディスクを必要とする。
-
このディスクは、
etcd デバイスと呼ばれます。
-
-
各コントローラーおよびワーカー VM は、Docker オーバーレイおよびその他の内部サービスに 1000 IOPS 以上で最小 100 GiB (開発の場合) または 250 GiB (本番の場合) の専用ディスクを必要とする。
-
このディスクは、
docker デバイスと呼ばれます。
-
| インストールを開始する前に、「Anypoint Runtime Fabric のシステム要件の確認」を参照してください。 |
インストール中、インストールパッケージはインストールのリーダーとして機能するコントローラー VM にダウンロードされます。
Anypoint Runtime Fabric は、複数の仮想マシンにわたるクラスターとして実行するように設定されています。各 VM は、次の 2 つのロールのいずれかとして機能します。
-
コントローラー VM は Runtime Fabric サービスの運用と実行専用。内部ロードバランサーもこれらの VM 内で実行されます。
-
ワーカー VM は Mule アプリケーションの実行専用。
1 つのコントローラー VM がインストール中にリーダーとして機能します。この VM は、インストーラーをダウンロードし、ポート 32009 で他の各 VM にアクセスできるようにします。他の VM はリーダーからインストーラーファイルをコピーしてインストールを実行し、リーダーに参加してクラスターを形成します。
インストール中、一連のプリフライトチェックが実行され、定義されている Runtime Fabric の最小ハードウェア、オペレーティングシステム、およびネットワーク要件が検証されます。これらの要件が満たされていない場合、インストーラーは失敗します。
インストールプロセスは、次の手順の組み合わせです。
-
AWS および Azure の場合、システム要件に従ってインフラストラクチャをプロビジョニングする。
-
VM 全体で Runtime Fabric をインストールする。
-
Anypoint 組織で Runtime Fabric をアクティブ化する。
-
組織の Mule Enterprise ライセンスをインストールする。
これらの手順を完了するには、インストールの開始時に各 VM の環境変数を指定します。Mule ライセンスをアクティブ化して追加するには、リーダーに追加の変数が必要です。スクリプトが各 VM で実行され、次のアクションが実行されます。
-
各専用ディスクをフォーマットしてマウントする
-
各ディスクのマウントエントリを
/etc/fstab に追加する -
iptable ルールを追加する
-
必要なカーネルモジュールを有効にする
-
インストールを開始する
インストールのリーダーとして機能するコントローラー VM で、次のアクションが実行されます。
-
インストール後にアクティベーションスクリプトを実行する
-
登録後に Mule ライセンス挿入スクリプトを実行する