Batch Component Reference
Mule batch components manage bulk processing of records with minimal adjustments to default component settings. They are highly configurable to meet specific processing and performance requirements.
A Batch Job component must contain at least one Batch Step component. Optionally, each Batch Step component can contain a single Batch Aggregator component. The Mule flow in the following figure shows batch components.
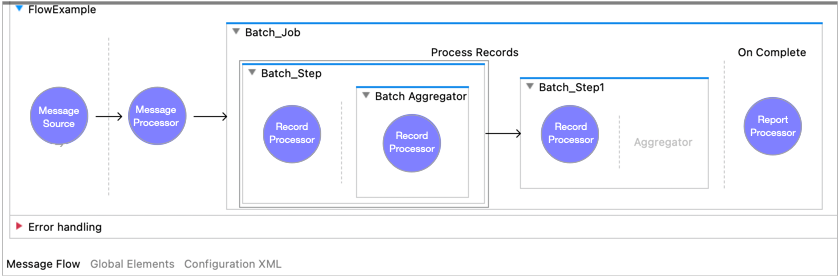
The Batch Job component splits the payload of the Mule message into records. Within the Batch Step and Batch Aggregator components, these records are available with the keyword payload, and Mule variables are also accessible through the vars keyword. However, Mule attributes are not accessible from within these components. Both components return null on attributes.
This reference assumes that you are familiar with the batch processing phases of a batch job instance.
Batch Job Component (<batch:job />)
This component prepares its input for processing and outputs a report with results of that processing. Preparation takes place during the Load and Dispatch phase of a batch job instance, and the report is available in the On Complete phase.
Batch Job Properties
The Batch Job component provides a number of configurable properties that determine how batch processing takes place. It also provides a way of storing the input payload in a target variable for use by subsequent components in the flow, which can be useful because the Batch Job component consumes the message payload.
Anypoint Studio provides the following fields in the General tab:
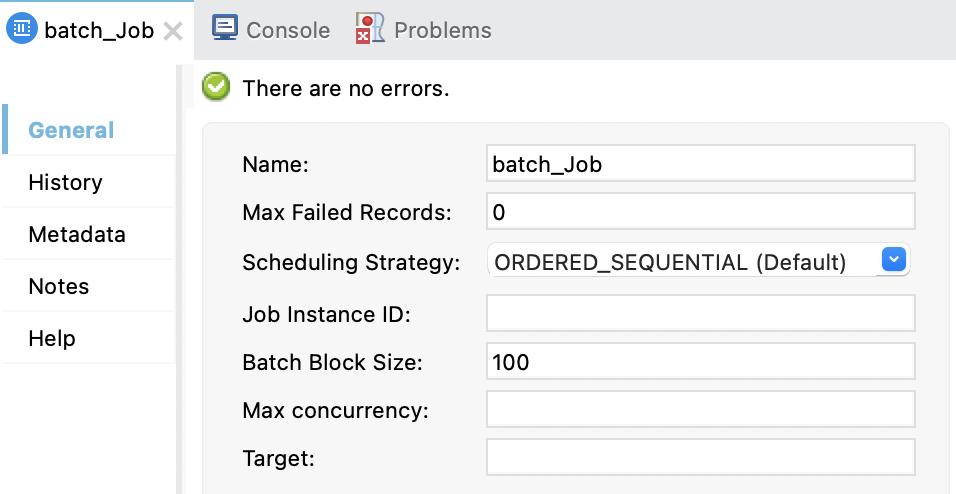
The following table describes each field and includes the XML attribute for the field.
| Field Name | XML | Description |
|---|---|---|
Name |
|
Configurable name for a Batch Job component. The default name appends |
Max Failed Records |
|
Maximum number of records that can fail within a batch job instance before the execution of that instance stops. The default is INFO ... DefaultBatchEngine: instance '6d85c380-f332-11ec-bb5f-147ddaaf4f97' of job 'Batch_Job_in_Mule_Flow' has reached the max allowed number of failed records. Record will be added to failed list and the instance will be removed from execution pool. ... INFO ... DefaultBatchEngine: instance 6d85c380-f332-11ec-bb5f-147ddaaf4f97 of job Batch_Job_in_Mule_Flow has been stopped. Instance status is FAILED_PROCESS_RECORDS Note that parallel processing within a batch job instance makes it possible for the number of errors to exceed the configured maximum because it is possible for multiple records fail at the same time. |
Scheduling Strategy |
|
When a Batch Job component triggers repeatedly, more than one batch job instance can be ready to execute at the same time. The instances can run sequentially based on their creation timestamp (the default) or according to a round-robin algorithm that attempts to maximize the use of available resources. This setting is appropriate only for jobs that have no side effects or dependencies on other records because the order of processing is not guaranteed.
|
Job Instance ID |
|
Optional expression that provides a recognizable, unique name for the batch instance. To make the name unique, you must use a DataWeave expression, for example, |
Batch Block Size |
|
Number of records to process per record block. The default is |
Max Concurrency |
|
Property that sets the maximum level of parallelism to allow when processing record blocks within the component. The default is twice the number of cores available in the CPUs. The capacity of the system running the Mule instance also limits concurrency. Like the |
Target |
|
To use the payload received by a batch job instance in a component that is located after the Batch Job component, you can provide a unique value for the |
Batch Job History (<batch:history />)
A batch job history configuration enables you to address a No space left on device error by adjusting the amount of time that historical data for batch job instances persist in a temporary Mule directory. This error can occur if the frequency or number of records to process is too high for the available disk space or for a CloudHub worker of a given size to handle.
By default, the history of batch job instances persists for 7 days. A monitoring process automatically removes that history when the period expires.
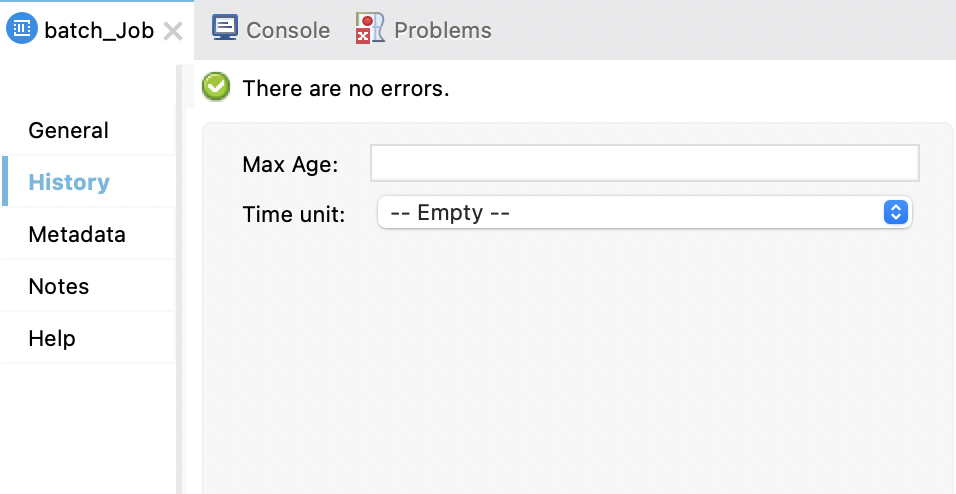
The following table describes each field and includes the XML attribute for the field.
| Name | XML | Description |
|---|---|---|
Max Age |
|
Maximum age of job instances before they expire, for example: |
Time Unit |
|
The unit of time to apply to the |
Note that these fields are attributes to the <batch:expiration/> element, which is embedded within <batch:history/>:
<batch:job ...>
<batch:history >
<batch:expiration maxAge="10" ageUnit="MINUTES" />
</batch:history>
<batch:process-records>
<batch:step />
</batch:process-records>
<batch:job />The XML example is edited to focus on settings in the batch history fields.
Batch Step Component (<batch:step/>)
The Batch Step component runs during the Process phase of a batch job instance, not during the Load and Dispatch or On Complete phases.
A minimum of one Batch Step component is required within a Batch Job component. In addition to changing the name of a Batch Step component, you can configure filters that determine which records the component accepts for processing within the component. Any processors that you add to the component act on records that the Batch Job component accepts.
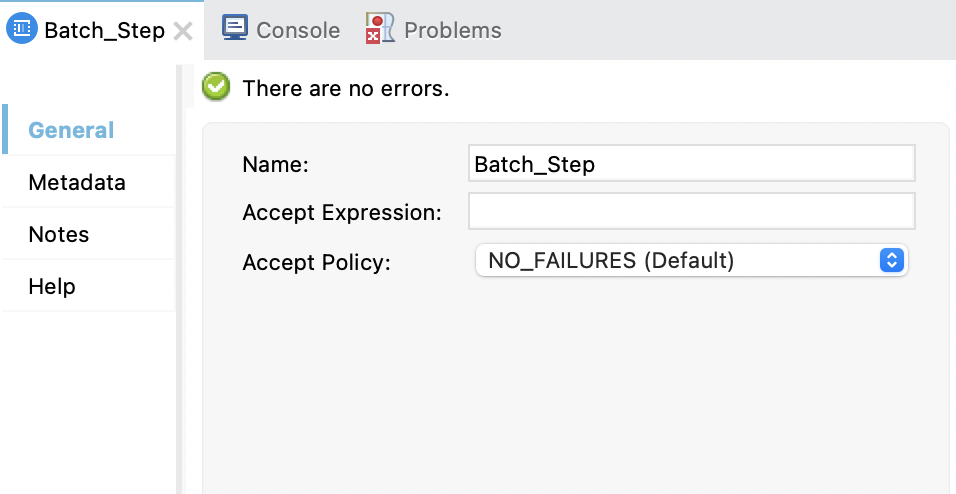
The following table describes each field and includes the XML attribute for the field.
| Field Name | XML | Description |
|---|---|---|
Name |
|
Configurable name for a Batch Step component. The default is |
Accept Expression |
|
Optional DataWeave expression for a filter that determines whether to process a record in the component. If both the
|
Accept Policy |
|
Accepts a record for processing only if the policy evaluates to
|
Batch Aggregator Component (<batch:aggregator />)
The Batch Aggregator component is an optional component that acts on an array of records. Aggregation takes place during the Process phase of a batch job instance.
There is no default configuration for the Batch Aggregator component. If you use this component, you must indicate whether to stream records (streaming) or pull records from the queue into separate arrays of a fixed size (size), but not both. The settings are mutually exclusive. Random access to streamed records is not possible.
The Batch Aggregator component accepts one or more processors for the message payload. However, it is common to use a scope within the aggregator, such as For Each scope, to iterate over each record so that the child processors within the scope can act on each record individually.
The Batch Aggregator component also provides a way preserve the MIME type of records (preserveMimeTypes), which is needed when accessing part of a record that you are aggregating as a fixed size (size). See Preserving the MIME types of the Aggregated Records. To learn about record processing within this component, see batch aggregation information in Process Phase.
Note that some connectors, such as Anypoint Connector for Salesforce (Salesforce Connector) and Anypoint Connector for NetSuite (NetSuite Connector), provide operations that can handle record-level errors without causing the batch aggregation process to fail.
When using Batch Aggregators, consider the following limitations:
-
When using a Batch Aggregator component, do not attempt to process Guava data types, such as
ImmutableMap. Instead, use a JavaMapto avoid serialization issues. -
The Batch Aggregator component does not support job-instance-wide transactions. Within a Batch Step component, you can define a transaction that processes each record in a separate transaction. However, any transaction started by a Batch Step component ends before the Batch Aggregator component starts processing. Components cannot share a transaction because a transaction cannot cross the boundary between the components.
The following table describes each field and includes the XML element for the field.
| Field Name | XML | Description |
|---|---|---|
Display Name |
|
Configurable name for the component. Example: |
Aggregator Size |
|
Size of each array of records to process. There is no default size. The processor within the component must accept an array as input. The component continues pulling records from the batch stepping queue into arrays of the configured size until none are left. If the queue contains fewer records than the configured size, the component pulls those records into a smaller array for processing. You must set the Size ( When using this configuration, the component does not wait for the Batch Step component to finish processing all records in an instance or batch. Once the set number of records is available in the stepping queue, the Batch Aggregator component pulls those records into an array and processes them. |
Streaming |
|
When Processors can gain sequential access to the array of streamed records. Random access to the streamed records is not allowed because the aggregator does not preserve the processed records. There is no default. You must set the Size ( |
Preserve Mime Types |
|
Defaults to |
When deciding whether to stream aggregated records, consider the following:
-
SaaS providers often have restrictions on accepting streaming input.
-
Batch streaming is often useful in batch processing when writing to a file such as CSV, JSON, or XML.
-
Batch streaming affects the performance of your application because the array of records is stored in RAM, which can slow the pace of transaction processing. Though performance slows, the trade-off of streaming data can warrant its use.
-
Streaming prevents random access to records because a streaming commit is a one-read, forward-only iterator. However, you can perform random access operations when streaming if you use a component like For Each. For Each provides a separate array of records, which is accessible through its
recordsvariable.