Scalability Benchmarks
Runtime Fabric is a core Kubernetes (K8s) software and works alike in all K8s environments which comply with Runtime Fabric hardware and software requirements.
Scale Limits
The following scale limits are benchmarked on Amazon Elastic Kubernetes Service (Amazon EKS) cluster.
| Limitation | Description | Enforced by Runtime Fabric |
|---|---|---|
Deployments per Runtime Fabric |
The maximum number of deployments being managed by Runtime Fabric at any instance should not exceed 8000 for optimal performance. |
Recommended |
Horizontal Pod Autoscaling (HPA) |
With Runtime Fabric on Amazon EKS, occasional traffic failures of approximately 0.09% may occur when scaling replicas from 1 to 8. These errors are specific to the pod scaling window, so you may experience traffic failure during scaling operations. |
Runtime Fabric functionality and management of application deployments is not affected by the following:
-
Size of individual applications
-
Size of worker nodes
-
Number of pods running per work node
Because Runtime Fabric is K8s based and uses cloud-native orchestration principals, it works according to the specified configuration of deployments.
Benchmarked Metrics
Review the following benchmarked metrics to understand various management metrics when compared between a nearly empty cluster and a cluster running 8000 deployments. The cluster configuration used is Runtime Fabric on AWS EKS cluster:
| Configuration | Description |
|---|---|
VPC and node groups |
Default configuration done from eksctl. 3 subnets (one subnet per node group), NAT Gateway. |
AWS NLB |
Equipped via helm chart at nginx creation. |
Node Auto Scaler |
Recommended 3 GB (Memory)/200m vCore (req==limit) |
Workers |
m5.4x large, worker node group |
Monitoring |
Fixed, 1 Node, Prometheus, monitoring node group, m5.2x large |
Ingress |
Fixed, 2 Nodes, Nginx, ingress node group, m5.4xlarge |
Runtime Fabric Restart Latency
The following graphic shows how long the Runtime Fabric agent takes to restart if invoked by the customers or cluster upgrade:
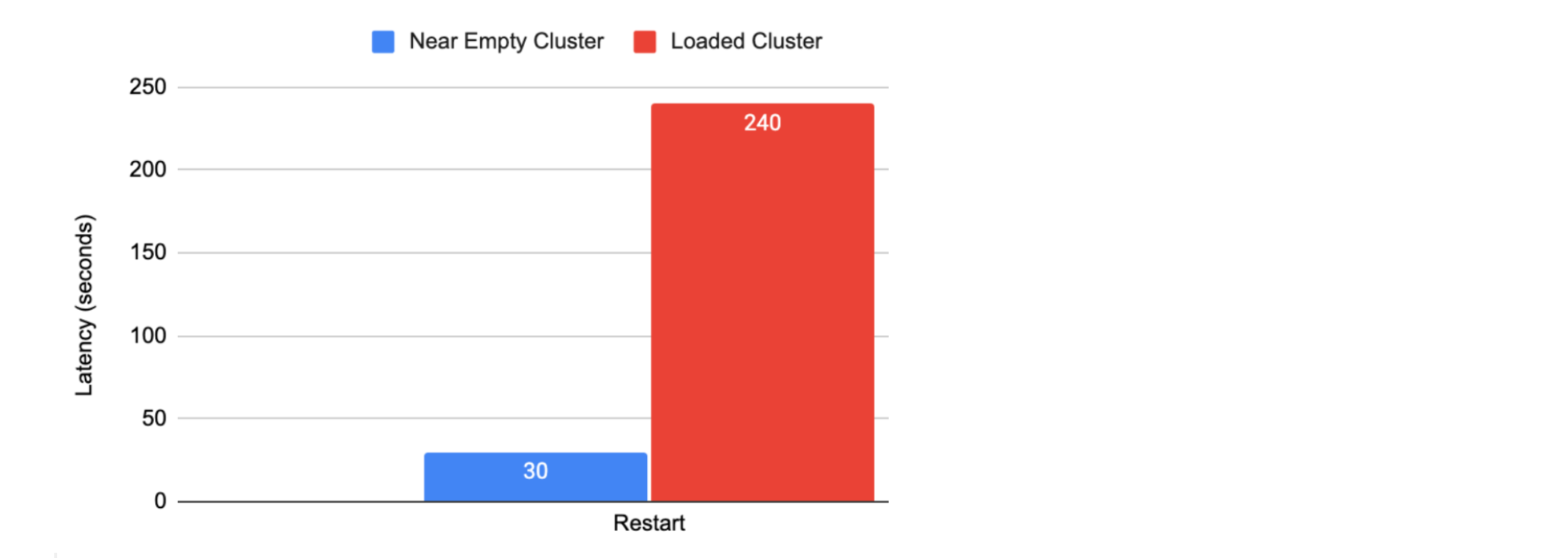
Runtime Fabric takes approximately 190 seconds to create the apps irrespective of deployment volume. The following table shows how long it takes for a Mule app to start, stop, or delete:
| App Operations | Near Empty Cluster | Loaded |
|---|---|---|
Start Latency |
~110 seconds |
158 seconds |
Stop Latency |
~10 seconds |
20 seconds |
Delete Latency |
~9 seconds |
~28 seconds |
The following table shows how long a node cordon operation takes to restart if there is a bad node:
| Node Operation | Empty Cluster | Loaded Cluster |
|---|---|---|
Cordon |
~2 seconds |
~2 seconds |
Drain process |
~4 seconds |
~35 seconds |
Considerations
Review the following scale considerations:
-
Runtime Fabric agent requires more than default memory and CPU to manage clusters with large-scale deployments, you can modify such values using the information in the following table. For a cluster with 8000 deployments, use at least:
Cluster Recommendations Default 200 Node/8000 App Resource Settings Agent Resources
Memory 200Mi request, 500Mi limit. CPU 100m request, 1vCore limit.
1000Mi (Memory)/1vCore (request == limit)
Daemon Resources
Memory 200Mi request, 300Mi limit. CPU 150m request, 200m limit.
1200Mi (Memory)/500m (request == limit)
-
The default resource allocation supports up to 2K apps / 75 nodes.
-
The performance of large-scale deployment orchestration through Runtime Fabric is inversely proportional to the volume of deployments.
-
RTFCTL clusters are supported only for certain benchmarks.
-
Using Helm enables you to manage any cluster that requires customized resources for Runtime Fabric agent due to the size of the cluster.
-
When scaling up Runtime Fabric agent resource limit, consider increasing the request accordingly.
-
Try not to run a container unbounded by removing the limit completely. For OpenShift operators, removing the limit sets the agent to the default limit setting.
-
resource-cacheandmule-clusterip-serviceservices can be scaled horizontally because they are stateless.