DataWeave の出力形式とライタープロパティ
|
DataWeave 2.1 は Mule 4.1 と互換性があります。 Mule 4.1 の標準サポートは 2020 年 11 月 2 日に終了しました。このバージョンの Mule は、拡張サポートが終了する 2022 年 11 月 2 日にそのすべてのサポートが終了します。 このバージョンの Mule を使用する CloudHub には新しいアプリケーションをデプロイできなくなります。許可されるのはアプリケーションへのインプレース更新のみになります。 標準サポートが適用されている最新バージョンの Mule 4 にアップグレードすることをお勧めします。これにより、最新の修正とセキュリティ機能強化を備えたアプリケーションが実行されます。 |
DataWeave では、JSON、XML など、多くの種別のデータ形式を読み書きできます。DataWeave では、以下の形式 (または MIME タイプ) が入力および出力としてサポートされます。
| Mime Type (MIME タイプ) | サポートされる形式 |
|---|---|
|
CSV |
|
DataWeave (DataWeave 式のテスト用) |
|
|
|
フラットファイル、Cobol コピーブック、固定幅 |
|
|
|
JSON |
|
バイナリ用。 |
|
YAML データ形式用。 |
|
|
|
|
|
|
|
テキスト形式用。 |
MIME タイプの設定
Mule アプリケーションを流れる入力および出力データで MIME タイプを指定できます。
DataWeave 変換の場合、出力データで MIME タイプを指定できます。たとえば、Transform コンポーネントまたは Write 操作内の式の output ヘッダーディレクティブを output application/json または output application/csv に設定できます。この例では、File Write 操作を使用して MIME タイプを設定し、形式固有のライター (CSV ライター) がペイロードを CSV 形式で出力するようにします。
<file:write doc:name="Write" config-ref="File_Config" path="my_transform">
<file:content ><![CDATA[#[output application/csv --- payload]]]></file:content>
</file:write>入力データの場合、Mule ソースの形式固有のリーダー (新規ファイルリスナなど)、Mule 操作 (Read、HTTP Request 操作など)、および DataWeave 式では、Mule イベントの入力ペイロード、属性、および変数に関連付けられるメタデータから MIME タイプが推定されます。MIME タイプをメタデータから推定できない場合 (およびそのメタデータが静的でない場合)、Mule ソースおよび操作では、リーダーの MIME タイプを指定することができます。たとえば、新規ファイルリスナの MIME タイプを CSV ファイルの入力用の outputMimeType='application/csv' に設定できます。この設定では、ファイル形式に関する情報が CSV リーダーに提供されます。
<file:listener doc:name="On New File"
config-ref="File_Config"
outputMimeType='application/csv'>
</file:listener>形式間の変換を実行するのにリーダー設定は使用されません。リーダー設定は、リーダーが入力の形式を解釈できるようサポートするのみです。
また、ソース、操作、またはコンポーネントの形式固有のリーダーまたはライターで使用する、リーダーとライターの特別なプロパティを設定することもできます。「リーダーとライターのプロパティの使用」を参照してください。
リーダーとライターのプロパティの使用
場合によって、形式固有のプロパティを使用して、形式の各側面を変更または指定することが必要になることがあります。たとえば、separator (または区切り文字) など、CSV ファイルで使用する、CSV の入力および出力プロパティを指定できます。Cobol コピーブックでは、schemaPath プロパティを使用して、スキーマファイルへのパスを指定する必要があります。
Mule アプリケーション内の特定のコンポーネントの MIME タイプ (outputMimeType) 属性にリーダープロパティを追加できます。Listeners および Read 操作ではこの設定が受け入れられます。たとえば、この新規ファイルリスナの例では、CSV 入力ファイルの , 区切り文字を識別します。
<file:listener doc:name="On New File" config-ref="File_Config" outputMimeType='application/csv; separator=","'>
<scheduling-strategy >
<fixed-frequency frequency="45" timeUnit="SECONDS"/>
</scheduling-strategy>
<file:matcher filenamePattern="comma_separated.csv" />
</file:listener>上記の outputMimeType 設定は、ライターではなく CSV リーダーが comma_separated.csv 入力ファイルの形式と区切り文字を解釈するのに役立ちます。
出力形式を指定するには、File Write 操作で使用する CSV または JSON ライターなど、ライターの MIME タイプと任意のライタープロパティを提供できます。たとえば、CSV 出力のペイロードで、入力で使用する他の区切り文字ではなくパイプ (|) 区切り文字を記述しなければならない場合があります。これを行うには、プロパティとその値を DataWeave 式の output ディレクティブに追加します。たとえば、次の Write 操作ではパイプを separator として指定しています。
<file:write doc:name="Write" config-ref="File_Config" path="my_transform">
<file:content ><![CDATA[#[output application/csv separator="|" --- payload]]]></file:content>
</file:write>以下のセクションで、サポートされる各形式で使用可能な形式固有のリーダープロパティとライタープロパティについて説明します。
Cobol コピーブック
MIME タイプ: application/flatfile
Cobol コピーブックは、Cobol データファイルのレコードと項目のレイアウトを記述するフラットファイルの種別です。
Transform コンポーネントは、Cobol コピーブック形式を処理するための設定を提供します。たとえば、Cobol 定義を Transform コンポーネントにインポートしてコピーブック変換で使用できます。
コピーブック定義のインポート
コピーブック定義をインポートすると、Transform コンポーネントは、schemaPath プロパティで参照できるフラットファイルスキーマに定義を変換します。
コピーブック定義をインポートする方法
-
Studio で Transform コンポーネントの入力ペイロードを右クリックし、[Set Metadata (メタデータを設定)] を選択して [Set Metadata Type (メタデータ型を設定)] ダイアログを開きます。
コピーブック定義をインポートする前に、メタデータ型を定義する必要があります。
-
コピーブックメタデータの名前を入力します (例:
copybook)。 -
[Type (型)] ドロップダウンメニューから [Copybook (コピーブック)] 型を選択します。
-
コピーブック定義ファイルをインポートします。
-
[Select (選択)] をクリックします。
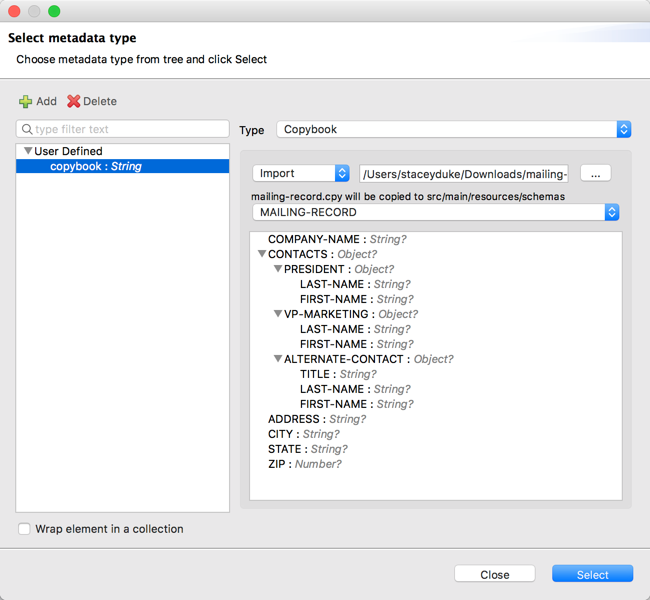 Figure 1. コピーブック定義ファイルのインポート
Figure 1. コピーブック定義ファイルのインポート
たとえば、次のようなコピーブック定義ファイル (mailing-record.cpy) があるとします。
01 MAILING-RECORD.
05 COMPANY-NAME PIC X(30).
05 CONTACTS.
10 PRESIDENT.
15 LAST-NAME PIC X(15).
15 FIRST-NAME PIC X(8).
10 VP-MARKETING.
15 LAST-NAME PIC X(15).
15 FIRST-NAME PIC X(8).
10 ALTERNATE-CONTACT.
15 TITLE PIC X(10).
15 LAST-NAME PIC X(15).
15 FIRST-NAME PIC X(8).
05 ADDRESS PIC X(15).
05 CITY PIC X(15).
05 STATE PIC XX.
05 ZIP PIC 9(5).
注意: コピーブック定義は常に 01 エントリから始まる必要があります。コピーブック内の 01 定義ごとに個別のレコードタイプが生成されます (コピーブックを使用できるようにするには 1 つ以上の 01 定義が存在する必要があります。定義がない場合は、任意の名前を使用して、コピーブックの開始位置に定義を追加します)。コピーブックファイルに複数の 01 定義がある場合、変換で使用する定義をドロップダウンリストから選択できます。
注意: COBOL 形式では、各行の列 7 ~ 72 のみを使用するように定義する必要があります。列 1 ~ 5 と列 72 より後のデータは、インポートプロセスで無視されます。列 6 は、行継続マーカーです。
スキーマをインポートすると、Transform コンポーネントは、Muke プロジェクトの src/main/resources/schema フォルダに保存しているフラットファイルスキーマにコピーブックファイルを変換します。フラットファイル形式では、上記のコピーブック定義は次のようになります。
form: COPYBOOK
id: 'MAILING-RECORD'
values:
- { name: 'COMPANY-NAME', type: String, length: 30 }
- name: 'CONTACTS'
values:
- name: 'PRESIDENT'
values:
- { name: 'LAST-NAME', type: String, length: 15 }
- { name: 'FIRST-NAME', type: String, length: 8 }
- name: 'VP-MARKETING'
values:
- { name: 'LAST-NAME', type: String, length: 15 }
- { name: 'FIRST-NAME', type: String, length: 8 }
- name: 'ALTERNATE-CONTACT'
values:
- { name: 'TITLE', type: String, length: 10 }
- { name: 'LAST-NAME', type: String, length: 15 }
- { name: 'FIRST-NAME', type: String, length: 8 }
- { name: 'ADDRESS', type: String, length: 15 }
- { name: 'CITY', type: String, length: 15 }
- { name: 'STATE', type: String, length: 2 }
- { name: 'ZIP', type: Integer, length: 5, format: { justify: ZEROES, sign: UNSIGNED } }
コピーブックをインポートしたら、schemaPath プロパティを使用して output ディレクティブを介して関連付けられているフラットファイルを参照できます。例: output application/flatfile schemaPath="src/main/resources/schemas/mailing-record.ffd"
サポートされるコピーブック機能
すべてのコピーブック機能が DataWeave の Cobol コピーブック形式でサポートされるとは限りません。一般に、この形式では次を含む最も一般的な使用方法と簡単なパターンがサポートされます。
-
DISPLAY、BINARY (COMP)、および PACKED-DECIMAL (COMP-3) の USAGE
-
以下のみで構成される数値の PICTURE 句
-
「9」- 1 つ以上の数字位置
-
「S」- 1 つの省略可能な符号文字位置 (先頭または末尾)
-
「V」- 1 つの省略可能な小数点
-
「P」- 1 つ以上の 10 進数位取り位置
-
-
「X」文字位置のみで構成される英数字値の PICTURE 句
-
PICTURE 句での「9」、「P」、および「X」文字の反復数 (5 桁数値の場合の
9(5) など) -
スキーマの controlVal プロパティが含まれる OCCURS DEPENDING ON。含まれる構造内で制御値がネストされている場合、生成されたスキーマを手動で変更して、「container.value」の値のフルパスを指定する必要があります。
サポートされないコピーブック機能
サポートされないコピーブック機能を次に示します。
-
英数字で編集された PICTURE 句
-
挿入または置換を含む、数値で編集された PICTURE 句
-
特殊なレベル番号:
-
レベル 66 - 項目またはグループの代替名
-
レベル 77 - 独立データ項目
-
レベル 88 - 条件名 (値の列挙に相当)
-
-
COMP-1、COMP-2、または COMP-5 の USAGE
-
REDEFINES 句 (レコードデータの同じ部分の異なるビューを提供するために使用)
-
VALUE 句 (リテラルまたは別のデータ項目からデータ項目または条件名の値を定義するために使用)
-
SYNC 句 (レコード内で値を一致させるために使用)
コピーブックのインポートに関する一般的な問題
コピーブックのインポートに関する最も一般的な問題は、入力行領域の Cobol 標準に従っていないことです。コピーブックのインポート解析では、各行の列 1 ~ 6 の内容が無視され、列 7 に「*」 (アスタリスク) が含まれているすべての行が無視されます。また、各行の列 72 を超える部分はすべて無視されます。つまり、実際のすべてのデータ定義が入力行の列 8 から 72 の間に存在する必要があります。
タブ位置に関する定義された標準はないため、入力内のタブは展開されません。コピーブックの入力列を数える場合、各タブ文字は 1 個のスペース文字として処理されます。
コピーブックを処理するときにインデントは無視され、レベル番号のみが有意として処理されます。これは通常は問題ではありませんが、Cobol コンパイラで受け入れられないにも関わらずコピーブックのインポートが受け入れられる可能性があります。
コピーブックのインポートの結果として警告とエラーの両方が報告される場合があります。一般に、警告は、有意であるかどうかに関係なく、機能がサポートまたは認識されないことを伝えます。エラーは、生成されたスキーマ (ある場合) がコピーブックの完全に正確な表現ではないことを意味する問題の通知です。報告されたすべての警告またはエラーを確認し、適切な処理を決定する必要があります。スキーマを生成されたとおりに単に受け入れたり、入力のコピーブックを変更したり、生成されたスキーマを変更したりすることができます。
リーダープロパティ (Cobol コピーブック)
コピーブック種別の入力を定義する場合、データの解析方法をカスタマイズするために Mule プロジェクトの XML 定義に追加できるいくつかの省略可能なパラメータがあります。
| パラメータ | 型 | デフォルト | 説明 |
|---|---|---|---|
|
string (文字列) |
入力の解析で使用するスキーマファイルのローカルディスク内の場所 |
|
|
string (文字列) |
スキーマファイルで複数のセグメントが定義されている場合、使用する構造をこの項目で選択します。 |
|
|
string (文字列) |
nulls |
入力データ内で欠落値を表す方法 * |
|
string (文字列) |
strict |
予想される、行/レコード間の分離
|
|
boolean (ブール) |
false |
必須値が (レコードの終端を超えても) ない場合にエラーをスローする必要があるかどうか |
|
boolean (ブール) |
false |
EBCDIC の同じ表示文字とは対照的に、EBCDIC でエンコードされていない文字で「strict」ゾーンの 10 進形式を使用する必要があるかどうか |
|
boolean (ブール) |
false |
DEPENDING ON COBOL コピーブック値が常に最大のスペースを使用するのではなく、実際に使用される長さに値を切り捨てる必要があるかどうか |
種別 Binary または Packed のスキーマでは、改行を検出できないため、recordParsing を lenient に設定すると、長いレコードのみを処理でき、短いレコードは処理できません。このスキーマは特定の 1 バイト文字エンコードでのみ機能します (つまり、UTF-8 などの複数バイト形式では機能しません)。
ライタープロパティ (Cobol コピーブック)
コピーブック種別の出力を定義する場合、データの書き込み方法をカスタマイズするために DataWeave 出力ディレクティブに追加できるいくつかの省略可能なパラメータがあります。
| パラメータ | 型 | デフォルト | 説明 |
|---|---|---|---|
|
string (文字列) |
使用するスキーマファイルが配置されているパス |
|
|
string (文字列) |
スキーマファイルで複数の形式が定義されている場合、使用する形式を示します |
|
|
string (文字列) |
UTF-8 |
出力文字エンコード |
|
string (文字列) |
nulls |
指定したマップから欠落している省略可能な値を表す方法 * |
|
string (文字列) |
システムの標準の Java 行終端 |
各行/レコードの終端。Mule Runtime バージョン 4.0.4 以前では、これは、複数のレコードがある場合の区切り文字としてのみ使用されます。使用可能な値: |
|
boolean (ブール) |
|
末尾の文字を切り捨てることで、項目の長さを超える文字列値を切り取ります。 |
|
boolean (ブール) |
false |
必須値が (レコードの終端を超えても) ない場合にエラーをスローする必要があるかどうか |
|
boolean (ブール) |
false |
EBCDIC の同じ表示文字とは対照的に、EBCDIC でエンコードされていない文字で「strict」ゾーンの 10 進形式を使用する必要があるかどうか |
|
boolean (ブール) |
false |
DEPENDING ON COBOL コピーブック値が常に最大のスペースを使用するのではなく、実際に使用される長さに値を切り捨てる必要があるかどうか |
output application/flatfile schemaPath="src/main/resources/schemas/QBReqRsp.esl", structureIdent="QBResponse"CSV
MIME タイプ: application/csv
CSV コンテンツは DataWeave 内でオブジェクトのリストとしてモデル化され、各レコードはオブジェクトになり、レコード内の各項目はプロパティになります。次に例を示します。
%dw 2.0
output application/csv
---
[
{
"Name":"Mariano",
"Last Name":"De achaval"
},
{
"Name":"Leandro",
"Last Name":"Shokida"
}
]Name,Last Name
Mariano,De achaval
Leandro,Shokidaリーダープロパティ (CSV)
CSV では、項目の分離、引用符の切り替え、または引用符のエスケープを行うインジケータとして任意の特殊文字を割り当てることができます。入力内で使用されている特殊文字を把握して、DataWeave でその特殊文字を正しく解釈できるようにします。
CSV 種別の入力を定義する場合、データの解析方法をカスタマイズするために Mule プロジェクトの XML 定義に追加できるいくつかの省略可能なパラメータがあります。
| パラメータ | 型 | デフォルト | 説明 |
|---|---|---|---|
|
char (文字) |
|
項目間を分離する文字 |
|
char (文字) |
|
項目値を区切る文字 |
|
char (文字) |
|
項目値内の区切り文字または引用符をエスケープするために使用する文字 |
|
number (数値) |
|
本文が開始される行番号。 |
|
boolean (ブール) |
|
空の行を無視するかどうかを定義します |
|
boolean (ブール) |
|
出力の 1 行目に項目名が含まれるかどうかを示します |
|
number (数値) |
|
ヘッダーが配置されている行番号 |
|
boolean (ブール) |
|
入力 CSV をストリーミングするために使用します。(エントリを順次アクセスする場合のみ使用します)。 |
-
header=true の場合、入力内の項目に任意の場所で名前 (payload.userName など) を使用してアクセスできます。 -
header=false の場合、インデックスを使用して項目にアクセスする必要があります。インデックスは、最初にエントリを参照し、次に項目を参照します (payload[107][2] など)。
ライタープロパティ (CSV)
CSV 種別の出力を定義する場合、データの解析方法をカスタマイズするために出力ディレクティブに追加できるいくつかの省略可能なパラメータがあります。
| パラメータ | 型 | デフォルト | 説明 |
|---|---|---|---|
|
char (文字) |
, |
項目間を分離する文字 |
|
string (文字列) |
出力で使用する文字セット |
|
|
char (文字) |
" |
項目値を区切る文字 |
|
char (文字) |
\ |
項目値内の区切り文字または引用符をエスケープするために使用する文字 |
|
string (文字列) |
システムの行末のデフォルト |
使用する行区切り文字。例: "\r\n" |
|
boolean (ブール) |
true |
出力の 1 行目に項目名が含まれるかどうかを示します |
|
boolean (ブール) |
false |
ヘッダー値を引用符で囲む必要があることを示します |
|
boolean (ブール) |
false |
特殊文字が含まれているかどうかに関係なく各値を引用符で囲む必要があるかどうかを示します |
このすべてのパラメータは省略可能です。たとえば、CSV 出力ディレクティブは次のようになります。
output application/csv separator=";", header=false, quoteValues=true
DataWeave
MIME タイプ: application/dw
DataWeave 形式はすべての変換の正規形式です。これを使用すると、入力データが新しい形式に変換される前に入力データがどのように解釈されるかを容易に理解できます。
この例は、XML 入力が DataWeave 形式でどのように表現されるかを示しています。
<employees>
<employee>
<firstname>Mariano</firstname>
<lastname>DeAchaval</lastname>
</employee>
<employee>
<firstname>Leandro</firstname>
<lastname>Shokida</lastname>
</employee>
</employees>{
employees: {
employee: {
firstname: "Mariano",
lastname: "DeAchaval"
},
employee: {
firstname: "Leandro",
lastname: "Shokida"
}
}
} as Object {encoding: "UTF-8", mimeType: "text/xml"}Excel
MIME タイプ: application/xlsx
.xlsx ファイルのみがサポートされます (Excel 2007)。.xls ファイルは Mule Runtime ではサポートされません。
Excel ワークブックは一連のシートです。DataWeave では、これはオブジェクトにマップされ、各シートがキーになります。Excel シートごとに 1 つのテーブルのみが許可されます。テーブルは行の配列として表現されます。行はオブジェクトであり、そのキーが列、値がセルの内容になります。
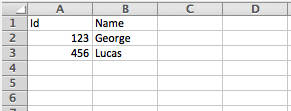
output application/xlsx header=true
---
{
Sheet1: [
{
Id: 123,
Name: George
},
{
Id: 456,
Name: Lucas
}
]
}リーダープロパティ (Excel)
Excel 種別の入力を定義する場合、データの解析方法をカスタマイズするために Mule プロジェクトの XML 定義に追加できるいくつかの省略可能なパラメータがあります。
| パラメータ | 型 | デフォルト | 説明 |
|---|---|---|---|
|
boolean (ブール) |
true |
Excel にヘッダーを含めるかどうかを定義します。false に設定すると、列名が使用されます。(A、B、C、…)。 |
|
boolean (ブール) |
true |
空の行を無視するかどうかを定義します |
|
string (文字列) |
A1 |
テーブルの最初のセルの位置 |
ライタープロパティ (Excel)
Excel 種別の出力を定義する場合、データの解析方法をカスタマイズするために出力ディレクティブに追加できるいくつかの省略可能なパラメータがあります。
| パラメータ | 型 | デフォルト | 説明 |
|---|---|---|---|
|
boolean (ブール) |
true |
Excel にヘッダーを含めるかどうかを定義します。ヘッダーがない場合、列名が使用されます。(A、B、C、…)。 |
|
boolean (ブール) |
true |
空の行を無視するかどうかを定義します |
|
string (文字列) |
A1 |
テーブルの最初のセルの位置 |
このすべてのパラメータは省略可能です。Excel の DataWeave 出力ディレクティブは次のようになります。
output application/xlsx header=true
固定幅
MIME タイプ: application/flatfile
固定幅の種別は技術的にはフラットファイル形式の種別とみなされますが、このオプションを選択すると、Transform コンポーネントでは、この形式のニーズに合わせて適切に調整された設定が提供されます。
リーダープロパティ (固定幅)
固定幅種別の入力を定義する場合、データの解析方法をカスタマイズするために Mule プロジェクトの XML 定義に追加できるいくつかの省略可能なパラメータがあります。
| パラメータ | 型 | デフォルト | 説明 |
|---|---|---|---|
|
string (文字列) |
入力の解析で使用するスキーマファイルのローカルディスク内の場所。このスキーマの拡張子は |
|
|
string (文字列) |
spaces |
入力データ内で欠落値を表す方法
|
|
string (文字列) |
strict |
予想される、行/レコード間の分離
|
ライタープロパティ (固定幅)
固定幅種別の出力を定義する場合、データの書き込み方法をカスタマイズするために出力ディレクティブに追加できるいくつかの省略可能なパラメータがあります。
| パラメータ | 型 | デフォルト | 説明 |
|---|---|---|---|
|
string (文字列) |
使用するスキーマファイルが配置されているパス |
|
|
string (文字列) |
UTF-8 |
出力文字エンコード |
|
string (文字列) |
spaces |
指定したマップから欠落している省略可能な値を表す方法
|
|
string (文字列) |
システムの標準の Java 行終端 |
各行/レコードの終端。Mule Runtime バージョン 4.0.4 以前では、これは、複数のレコードがある場合の区切り文字としてのみ使用されます。使用可能な値: |
|
boolean (ブール) |
|
末尾の文字を切り捨てることで、項目の長さを超える文字列値を切り取ります。 |
このすべてのパラメータは省略可能です。Excel の DataWeave 出力ディレクティブは次のようになります。
output application/flatfile schemaPath="src/main/resources/schemas/payment.ffd", encoding="UTF-8"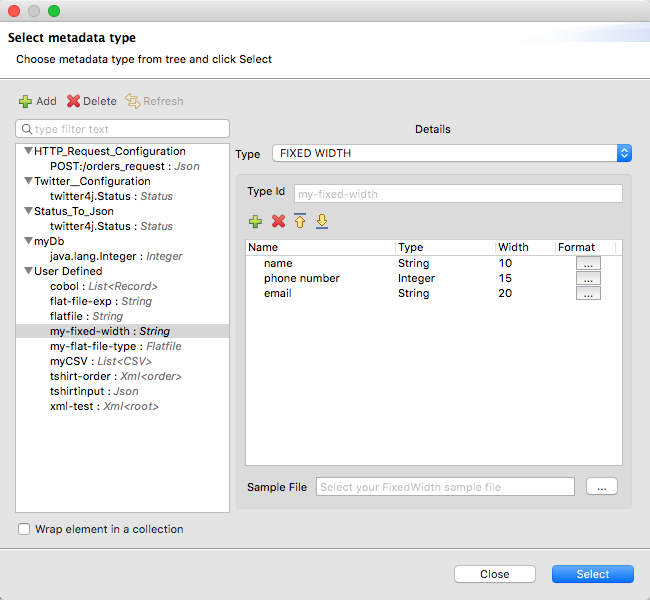
フラットファイル
MIME タイプ: application/flatfile
リーダープロパティ (フラットファイル)
フラットファイル種別の入力を定義する場合、データの解析方法をカスタマイズするために Mule プロジェクトの XML 定義に追加できるいくつかの省略可能なパラメータがあります。
| パラメータ | 型 | デフォルト | 説明 |
|---|---|---|---|
|
string (文字列) |
入力の解析で使用するスキーマファイルのローカルディスク内の場所。このスキーマの拡張子は |
|
|
string (文字列) |
スキーマファイルでは複数の異なる構造が定義されている場合があります。使用する構造をこの項目で選択します。スキーマで 1 つの構造のみが定義されている場合も、その構造をこの項目で明示的に選択する必要があります。 |
|
|
string (文字列) |
spaces |
入力データ内で欠落値を表す方法
|
|
string (文字列) |
strict |
予想される、行/レコード間の分離
|
種別 Binary または Packed のスキーマでは、改行を検出できないため、recordParsing を lenient に設定すると、長いレコードのみを処理でき、短いレコードは処理できません。現在、このスキーマも特定の 1 バイト文字エンコードでのみ機能します (つまり、UTF-8 などの複数バイト形式では機能しません)。
ライタープロパティ (フラットファイル)
フラットファイル種別の出力を定義する場合、データの書き込み方法をカスタマイズするために出力ディレクティブに追加できるいくつかの省略可能なパラメータがあります。
| パラメータ | 型 | デフォルト | 説明 |
|---|---|---|---|
|
string (文字列) |
使用するスキーマファイルが配置されているパス |
|
|
string (文字列) |
スキーマファイルで複数の形式が定義されている場合、使用する形式を示します |
|
|
string (文字列) |
UTF-8 |
出力文字エンコード |
|
string (文字列) |
spaces |
指定したマップから欠落している省略可能な値を表す方法
|
|
string (文字列) |
システムの標準の Java 行終端 |
各行/レコードの終端。Mule Runtime バージョン 4.0.4 以前では、これは、複数のレコードがある場合の区切り文字としてのみ使用されます。使用可能な値: |
|
boolean (ブール) |
|
末尾の文字を切り捨てることで、項目の長さを超える文字列値を切り取ります。 |
%dw 2.0
output application/flatfile schemaPath="src/main/resources/test-data/QBReqRsp.esl", structureIdent="QBResponse"
---
payloadマルチパート (フォームデータ)
形式: multipart/form-data
DataWeave ではマルチパートサブタイプ (特に form-data) がサポートされます。この形式では、各パートの形式に関係なく、1 つのペイロード内で複数の異なるデータパートを処理できます。パートの開始と終了を区別するには、境界を使用します。各パートのメタデータはヘッダーを介して追加できます。
3 つのパートで構成される 34b21 境界を含む未加工の multipart/form-data ペイロードを以下に示します。
-
text という名前の text/plain -
file1 という名前の application/json ファイル (a.json) -
file2 という名前の text/html ファイル (a.html)
--34b21
Content-Disposition: form-data; name="text"
Content-Type: text/plain
Book
--34b21
Content-Disposition: form-data; name="file1"; filename="a.json"
Content-Type: application/json
{
"title": "Java 8 in Action",
"author": "Mario Fusco",
"year": 2014
}
--34b21
Content-Disposition: form-data; name="file2"; filename="a.html"
Content-Type: text/html
<!DOCTYPE html>
<title>
Available for download!
</title>
--34b21--DataWeave スクリプト内で、parts 要素を選択し、任意のパートのデータにアクセスし、変換できます。
操作は配列に基づくことができます。また、パートを参照するための名前がパートに設定されている場合は、キーに基づくことができます。
パートのデータには content キーワードを介してアクセスでき、ヘッダーには headers キーワードを介してアクセスできます。
たとえば、次のスクリプトでは、上記のペイロードを考慮して Book:a.json が生成されます。
%dw 2.0
output text/plain
---
payload.parts.text.content ++ ':' ++ payload.parts[1].headers.'Content-Disposition'.filenameDataWeave を介してマルチパートコンテンツを生成し、パートのリスト (各パートにヘッダーとコンテンツが含まれる) を含むオブジェクトを構築できます。以下の DataWeave スクリプトでは、ペイロード内で HTML データを使用できるものとみなして、以前に分析した未加工のマルチパートデータを生成します。
%dw 2.0
output multipart/form-data
boundary='34b21'
---
{
parts : {
text : {
headers : {
"Content-Type": "text/plain"
},
content : "Book"
},
file1 : {
headers : {
"Content-Disposition" : {
"name": "file1",
"filename": "a.json"
},
"Content-Type" : "application/json"
},
content : {
title: "Java 8 in Action",
author: "Mario Fusco",
year: 2014
}
},
file2 : {
headers : {
"Content-Disposition" : {
"filename": "a.html"
},
"Content-Type" : payload.^mimeType
},
content : payload
}
}
}パートの名前が Content-Disposition ヘッダーに明示的に提供されていない場合は、キーによりパートの名前が決まります。また、DataWeave は、サポートされる形式からのコンテンツを処理できるだけでなく、HTML など、サポートされない形式への参照からコンテンツを処理できます。
リーダープロパティ (マルチパート)
データの分析時にリーダーで使用する境界を設定できます。
| パラメータ | 型 | デフォルト | 説明 |
|---|---|---|---|
|
String (文字列) |
パートを区切る文字列。 |
DataWeave の read 関数では、省略可能なパラメータとしてプロパティを渡すこともできます。プロパティのスコープは、関数をコールする DataWeave スクリプトに制限されます。
ライタープロパティ (マルチパート)
ライターは DataWeave ヘッダーディレクティブを使用してフォームデータを出力します。
output multipart/form-data出力ディレクティブでは、指定された形式でライターがデータを出力するときに使用するプロパティを設定することもできます。
| パラメータ | 型 | Default (デフォルト) | 説明 |
|---|---|---|---|
|
String (文字列) |
ランダムに自動生成 |
パートを区切る文字列。 |
たとえば、境界が 34b21 の場合、以下を渡すことができます。
output multipart/form-data
boundary=34b21DataWeave の write 関数では、省略可能なパラメータとしてプロパティを渡すこともできます。プロパティのスコープは、関数をコールする DataWeave スクリプトに制限されます。
|
通常 (ただし、これに限定されない)、マルチパートは、コンテンツの読み取りと書き込みの両方で、 |
Java
MIME タイプ: application/java
Java オブジェクトと DataWeave 型との間のマッピングを次の表に示します。
| Java 型 | DataWeave 型 |
|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
メタデータプロパティ class (Java)
Java 開発者は、入力としてどのクラスを作成し、送信する必要があるかについてのヒントとして class メタデータキーを使用します。これが明示的に定義されていない場合、DataWeave コンテキストから推定を試みるか、これにデフォルト値を割り当てます。
-
オブジェクトの場合は
java.util.HashMap -
リストの場合は
java.util.ArrayList
%dw 2.0
type user = Object { class: "com.anypoint.df.pojo.User"}
output application/json
---
{
name : "Mariano",
age : 31
} as user上のコードでは、必須入力の種別を com.anypoint.df.pojo.User のインスタンスとして定義します。
JSON
MIME タイプ: application/json
JSON データ構造と DataWeave データ構造は多くの類似点を共有しているため、これらのデータ構造はマップされます。
ライタープロパティ (JSON)
JSON 種別の出力を定義する場合、データの解析方法をカスタマイズするために出力ディレクティブに追加できるいくつかの省略可能なパラメータがあります。
| パラメータ | 型 | Default (デフォルト) | 説明 |
|---|---|---|---|
|
boolean (ブール) |
true |
JSON コードをインデントして読みやすくするか、JSON コードを 1 行に圧縮するかを定義します。 |
|
string (文字列) |
UTF-8 |
出力で使用する文字セット |
|
number (数値) |
153600 |
バッファライターのサイズ |
|
string (文字列) |
どのような場合にライターでインラインの終了タグを使用するか。使用可能な値 = empty/none |
|
|
string (文字列) |
使用可能な値: |
|
|
boolean (ブール) |
false |
JSON 言語では、1 つの同じ親を持つ重複キーは許可されず、通常これにより例外が発生します。true に設定した場合、1 つのキーが含まれます。このキーは、自身に割り当てられたすべての値が含まれる配列を参照します。 |
output application/json indent=false, skipNullOn="everywhere"XML
MIME タイプ: application/xml
XML データ構造は、キーの値として他のオブジェクトが含まれている可能性がある DataWeave オブジェクトにマップされます。反復するキーがサポートされます。例:
<users>
<company>MuleSoft</company>
<user name="Leandro" lastName="Shokida"/>
<user name="Mariano" lastName="Achaval"/>
</users>{
users: {
company: "MuleSoft",
user @(name: "Leandro",lastName: "Shokida"): "",
user @(name: "Mariano",lastName: "Achaval"): ""
}
}リーダープロパティ (XML)
XML 種別の入力を定義する場合、データの解析方法をカスタマイズするために Mule プロジェクトの XML 定義に追加できるいくつかの省略可能なパラメータがあります。
| パラメータ | 型 | デフォルト | 説明 |
|---|---|---|---|
|
string (文字列) |
|
空または空白のテキストを含むタグを null として読み取るかどうか。 |
|
boolean (ブール) |
|
使用するリーダーのモダリティを選択します。インデックス付けされたリーダーは高速ですが、より多くのメモリを使用します。一方、インデックス付けされていないリーダーは低速ですが、より少ないメモリを使用します。 |
|
integer (整数) |
|
XML コード内でエンティティを参照できる回数を宣言します。これは、 サービス拒否攻撃から保護するために含まれています。 |
|
boolean (ブール) |
|
XML の外部のファイルで定義されたエンティティへの参照を有効として受け入れるかどうかを定義します。 セキュリティ上の理由からもこれを回避することをお勧めします。 |
|
|
|
DTD サポートを有効または無効にします。無効にすると、内部および外部のサブセットがスキップされ、処理されません。有効なオプションは、 |
ライタープロパティ (XML)
XML 種別の出力を定義する場合、データの解析方法をカスタマイズするために出力ディレクティブに追加できるいくつかの省略可能なパラメータがあります。
| パラメータ | 型 | デフォルト | 説明 |
|---|---|---|---|
|
boolean (ブール) |
true |
XML コードをインデントして読みやすくするか、XML コードを 1 行に圧縮するかを定義します。 |
|
string (文字列) |
|
空の XML 子要素を 1 つの自己終了タグとして表示するか、開始および終了タグを使用して表示するかを定義します。値 |
|
string (文字列) |
UTF-8 |
出力で使用する文字セット |
|
number (数値) |
153600 |
バッファライターのサイズ |
|
string (文字列) |
どのような場合にライターでインラインの終了タグを使用するか。使用可能な値 = |
|
|
string (文字列) |
使用可能な値: |
|
|
boolean (ブール) |
true |
XML 宣言を 1 行目に含めるかどうかを定義します。 |
output application/xml indent=false, skipNullOn="attributes"inlineCloseOn パラメータでは、出力を次のような (デフォルト) 構造にするかどうかを定義します。
<someXml>
<parentElement>
<emptyElement1></emptyElement1>
<emptyElement2></emptyElement2>
<emptyElement3></emptyElement3>
</parentElement>
</someXml>次のような構造にすることもできます (empty の値を設定)。
<payload>
<someXml>
<parentElement>
<emptyElement1/>
<emptyElement2/>
<emptyElement3/>
</parentElement>
</someXml>
</payload>「自己終了 XML タグの出力」の例も参照してください。
Null をスキップ (XML)
null 値の項目を含むアウトバウンドメッセージを変換で生成するかどうか、またはこのような項目を完全に無視するかどうかを指定できます。これは、skipNullOn という名前の出力ディレクティブ内の属性を介して設定でき、3 つの異なる値 (elements、attributes、または everywhere) に設定できます。
各設定値について説明します。
-
elements: キーと null 値のペアは無視されます。 -
attributes: null 値を含む XML 属性はスキップされます。 -
everywhere: このルールが要素と属性の両方に適用されます。
CData カスタム型 (XML)
MIME タイプ: application/xml
CData は、CDATA XML ブロックを識別するために使用する XML のカスタムデータ型です。CDATA 内でコンテンツをラップするか、CDATA ブロック内に入力文字列が到達したかどうかを確認するようにライターに指示することができます。CData は型 String から継承されます。
%dw 2.0
output application/xml
---
{
users:
{
user : "Mariano" as CData,
age : 31 as CData
}
}<?xml version="1.0" encoding="UTF-8"?>
<users>
<user><![CDATA[Mariano]]></user>
<age><![CDATA[31]]></age>
</users>URL エンコード
MIME タイプ: application/x-www-form-urlencoded
エンコードされた URL 文字列は DataWeave オブジェクトにマップされます。
-
ドットまたはスターセレクタを使用して、値をキーで読み取ることができます。
-
DataWeave オブジェクトを指定して、ペイロードを書き込むことができます。
x-www-form-urlencoded データの例を次に示します。
key=value&key+1=%40here&key=other+value&key+2%25次の DataWeave スクリプトでは、上のデータが生成されます。
output application/x-www-form-urlencoded
---
{
"key" : "value",
"key 1": "@here",
"key" : "other value",
"key 2%": null
}上のデータを次の例の DataWeave スクリプトへの入力として読み取って、結果として value@here を返すことができます。
output text/plain
---
payload.*key[0] ++ payload.'key 1'エンコードされた URL データのリーダープロパティはありません。
ライター (エンコードされた URL データ)
フォームデータを書き込むための DataWeave 出力ディレクティブを次に示します。
output application/x-www-form-urlencoded出力ディレクティブでは、指定された形式でライターがデータを出力するときに使用するプロパティを設定することもできます。
| パラメータ | デフォルト | 説明 |
|---|---|---|
|
UTF-8 |
使用するエンコードを指定します。 |
|
192KB |
バッファで使用するバイト数を指定します。 |
output application/x-www-form-urlencoded encoding="UTF-8", bufferSize="500"DataWeave の write 関数では、省略可能なパラメータとしてプロパティを渡すこともできます。プロパティのスコープは、関数をコールする DataWeave スクリプトに制限されます。