Batch Job 中のエラー処理
Mule バッチ処理は、非常に大規模なデータセットを処理して、ほぼリアルタイムのデータインテグレーションを実行できるように設計されており、クラッシュから復旧して、ジョブの処理を障害が発生した時点から続行できます。ただし、大規模なデータセットでは、発生する問題の冗長ログが膨大なサイズとなり、パフォーマンスが大きく低下する原因になることがあります。
この影響を抑えるため、Mule ではBatch Step 内の失敗したレコードのログで説明するように INFO レベルのログをデフォルトで使用します。より冗長なログメッセージが必要な場合は、モードを DEBUG に変更してください。このモードはデバッグに便利であり、小規模のデータセットを使用するケースで使用できます。
ログモードは次のプロパティで設定します。
log4j.logger.com.mulesoft.module.batch=DEBUG本番環境で大規模なデータセットを処理する場合は、DEBUG モードは使用しないでください。
Batch Step 内の失敗したレコードのログ
Batch Step インスタンスを処理するときに、たとえばレコードデータが破損していたり不完全であったりすることなどが原因で、Batch Step 内のプロセッサーが失敗したりエラーを発生させたりすることがあります。問題が発生した場合、デフォルトでは、Mule は INFO ログレベルを使用して、次のロジックに従ってスタックトレースをログに記録します。
-
Mule が例外の完全なスタック追跡を取得します。
-
Mule がログ内のエラーメッセージからスタックトレースを削除します。
すべてのレコードで同じエラーが発生したとしても、処理中のメッセージにはおそらくそれらのレコードに関連する特定の情報が含まれています。たとえば、リードを Salesforce アカウントに転送していて、特定のリードはすでにアップロード済みであるため 1 つのレコードがエラーになった場合、別の繰り返されるリードのレコード情報は異なりますが、同じエラーになります。 -
Mule はスタック追跡がすでに現在のステップに記録されているかどうかを検証します。
ランタイムでこのエラーに初めて遭遇すると、Mule はエラーをログに記録して、次のようなメッセージを生成します。com.mulesoft.mule.runtime.module.batch.internal.DefaultBatchStep: Found exception processing record on step 'batchStep1' for job instance 'Batch Job Example' of job 'CreateLeadsBatch'. This is the first record to show this exception on this step for this job instance. Subsequent records with the same failures will not be logged for performance and log readability reasons:Mule は「ステップごと」にログを記録します。別のステップでも同じエラーが発生した場合、ランタイムはそのステップに対してもログを記録します。
-
Batch Job が On Complete (完了時) フェーズに達すると、Mule にはエラー概要とすべてのエラーの種別、および各 Batch Step での発生回数が表示されます。
batch.exception 種別が発生した 2 つの Batch Step が含まれる Batch Job のエラー概要を次に示します。************************************************************************************************************************ * - - + Exception Type + - - * - - + Step + - - * - - + Count + - - * ************************************************************************************************************************ * com.mulesoft.mule.runtime.module.batch.exception.B * batchStep1 * 10 * * com.mulesoft.mule.runtime.module.batch.exception.B * batchStep2 * 9 * ************************************************************************************************************************ここでは、最初のステップが 10 回失敗し、2 番目のステップが 9 回失敗しています。
エラー処理用の DataWeave 関数
Mule 4.x には、Batch Step のコンテキストで使用できる DataWeave 関数のセットが含まれています。
| DataWeave 関数 | 説明 |
|---|---|
#[Batch::isSuccessfulRecord()] |
現在のレコードが前のステップで例外をスローしなかった場合に true を返すブール関数。 |
#[Batch::isFailedRecord()] |
現在のレコードが前のステップで例外をスローした場合に true を返すブール関数。 |
#[Batch::failureExceptionForStep(String)] |
ステップの名前を文字列引数として受け取ります。現在のレコードがそのステップで例外をスローした場合、実際の例外オブジェクトを返します。それ以外の場合は null を返します。 |
#[Batch::getStepExceptions()] |
Java |
#[Batch::getFirstException()] |
現在のレコードが失敗した最初のステップの例外を返します。レコードがどのステップでも失敗しなかった場合、null を返します。 |
#[Batch::getLastException()] |
現在のレコードが失敗した最後のステップの例外を返します。レコードがどのステップでも失敗しなかった場合、null を返します。 |
例
連絡先情報を含むファイルをポーリングする Batch Job があるとします。
最初のステップでは、Batch Job は連絡先情報を集約し、Transform Message コンポーネントを使用してそれらを変換してから Salesforce に転送します。
2 番目のステップでは、ジョブはその同じ連絡先を別のサードパーティ連絡先アプリケーション (Google コンタクトなど) のデータ構造と一致するように再度変換し、HTTP 要求を使用してこのサービスに転送します。
次に、3 番目のステップとして、失敗したレコードごとに JMS デッドレターキューに書き込むことができる必要があるとします。簡略化するため、例外自体をメッセージにするとします。この要件には注意が必要です。各レコードが両方のステップで失敗し、同じレコードが 2 つの JMS メッセージに変換される可能性があります。
このアプリケーションは次のようになります。

目標は失敗を収集することであるため、ONLY_FAILURES 検索条件を使用して Failures ステップを設定することが理にかなっています (バッチ検索条件についての詳細は「Batch Step 処理の絞り込み」参照)。
このステップの set-payload プロセッサーは、Batch::getStepExceptions() 関数を使用するように設定できます。
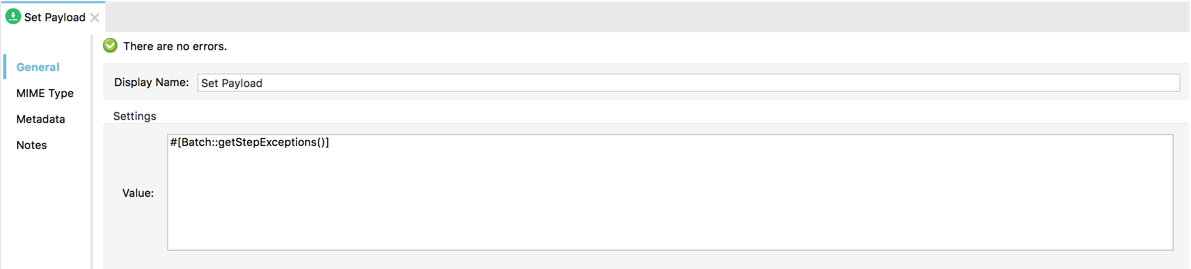
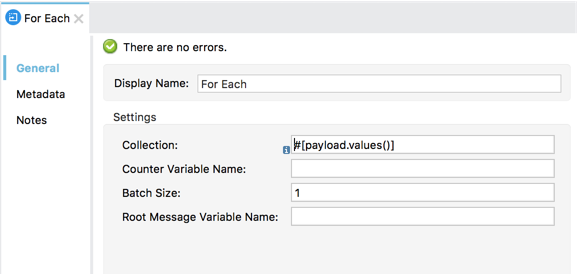
上述のように、この関数はすべてのステップで見つかったすべてのエラーを含むマップを返します。ここでの目標は JMS を介して例外を送信することであり、ステップを気にする必要はないため、foreach スコープを使用してマップの値 (エラー) を反復処理し、JMS アウトバウンドエンドポイントを介して送信できます。
エラー処理用のバッチ処理戦略
Mule には、レコードレベルのエラーを処理するための 3 つのオプションがあります。
-
処理を終了。現在のジョブインスタンスの実行を停止します。現在インフライト状態のレコードの実行を終了しますが、キューからそれ以上レコードを取得せずにジョブインスタンスを
FAILURE 状態に設定します。On Complete (完了時) フェーズが呼び出されます。 -
失敗したレコード数に関係なく処理を続行。
acceptExpression および acceptPolicy 属性を使用して、失敗したレコードの処理方法を後続の Batch Step に指示します。 -
Batch Job が失敗したレコードの最大数に達するまで、失敗したレコード数に関係なく処理を続行 (
acceptExpression および acceptPolicy 属性を使用して、失敗したレコードの処理方法を後続の Batch Job に指示します)。最大数に達した時点で、オプション 1 と同様に実行を停止します。
デフォルトでは、Mule の Batch Job はバッチインスタンスの実行を停止する最初のエラー処理戦略に従います。上記の動作は、maxFailedRecords 属性を使用して制御されます。
| 失敗したレコードの処理オプション | Batch Job 属性 | 値 |
|---|---|---|
失敗したレコードが見つかったときに処理を停止 |
|
|
失敗したレコード数に関係なく、無期限に処理を続行 |
|
|
失敗したレコードの最大数に達するまで処理を続行 |
|
|
<batch:job jobName="Batch1" maxFailedRecords="0">最大失敗しきい値の超過
Batch Job で maxFailedRecords しきい値を超えるのに十分な失敗したレコード数が蓄積されると、Mule は残りの Batch Job の処理を中止し、On Complete (完了時) フェーズに直接移動します。
たとえば、maxFailedRecords の値を「10」に設定し、Batch Job が 3 つの Batch Step 最初のステップで失敗したレコードを 10 件蓄積した場合、Mule は残り 2 つの Batch Step ではバッチを処理しません。代わりに、それ以降の処理を中止し、On Complete (完了時) に直接移動して Batch Job の失敗を報告します。
Batch Job が maxFailedRecords しきい値を超えるのに十分な失敗したレコード数を蓄積しない場合、すべてのレコード (成功と失敗) が引き続き Batch Step 間を移動します。各 Batch Step で処理するレコードを制御するには、検索条件を使用します。