クラスターランタイムインスタンス
Mule は、さまざまなトポロジーでデプロイできます。Mule アプリケーションをビルドする場合、目的の可用性、フォールトトレランス、パフォーマンス特性を実現するために、アプリケーションの最適な設計方法についてよく考えることが重要です。このページでは、オンプレミスにアプリケーションをデプロイするときにクラスタリングを介してこれらの特性を適切に融合するためのいくつかのソリューションについて説明します。1 つのアプローチですべてのユーザーに適切に対応することはできません。システム設計は、芸術と科学の両方で成り立っています。さらにサポートが必要な場合、MuleSoft プロフェッショナルサービスがアーキテクチャプランの確認や設定を行うことができます。詳細は、 お問い合わせください。
クラスタリングについて
以下の実現するには、アプリケーションをクラスターにデプロイすることが効果的です。
-
高可用性 (HA): クラスターの 1 つ以上のサーバーまたはデータセンターに障害が発生してもシステムを継続的に使用できます。
-
フォールトトレランス (FT): 基盤となるコンポーネントの障害から回復できます。通常、回復はトランザクションロールバックまたは補正アクションによって行われます。
-
スケーリング: 需要の増加に合わせてアプリケーションを垂直スケーリングできます。
このページでは、いくつかのクラスタリングソリューション候補について説明します。
Mule 高可用性
Enterprise Edition
Mule 高可用性では、Mule の基本的なフェールオーバー機能が提供されます。(JVM またはハードウェアの致命的な障害のため) プライマリ Mule インスタンスが使用できなくなった場合、バックアップ Mule インスタンスが即座にプライマリノードになり、障害の発生したインスタンスが中断した場所から処理を再開します。システム管理者が障害が発生した Mule インスタンスを回復してオンラインに戻すと、自動的にバックアップノードになります。 シームレスなフェールオーバーは、次のようなクラスタリングされた Mule インスタンスですべての一時的な状態の情報を共有する分散メモリストアによって実現します。
現在、Mule 高可用性は次のトランスポートで使用できます。
|
|
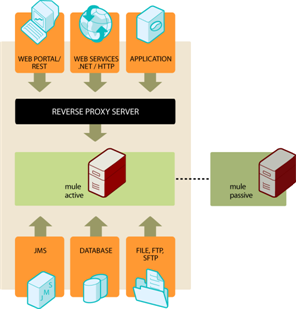
Mule 高可用性は、Mule Enterprise サブスクリプションで使用できます。テクニカルハイライト、要件、インストールなどの詳細は、お問い合わせください。
JMS キュー
JMS を使用すれば、メッセージを JMS キューを介してルーティングして HA & FT を実現できます。この場合、各メッセージはコンポーネント間の移動時に必ず JMS キューを介してルーティングされます。
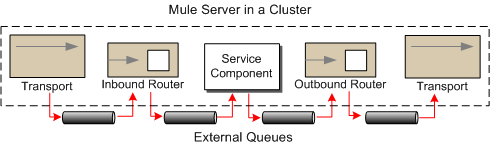
プラス面:
-
簡単に実行できる
-
開発者の理解が深い
マイナス面:
-
多くのトランザクションが必要となり、トランザクションが複雑になる可能性がある
-
XA を使用している場合、パフォーマンスが低下する
ロードバランサー
ロードバランサーは、各サーバーの現在の負荷と現在稼働しているサーバーに基づいて、要求を各サーバーにルーティングします。ロードバランサーは、ソフトウェアベースまたはハードウェアベースになります。このアプローチは、一般的にクラスタリングされたデータベースで使用されます (下記参照)。
プラス面:
-
簡単に実行できる
-
開発者の理解が深い
マイナス面:
-
これ自体では完全なソリューションにはならず、フォールトトレランスが提供されない。
例
このサンプルアーキテクチャでは、HTTP 要求がロードバランサーから入り、即座に JMS キューに配置されます。JMS キューは、異なるサーバー間でクラスタリングされています。サーバーは、JMS キューのメッセージの処理を開始し、トランザクションのすべてをラップします。
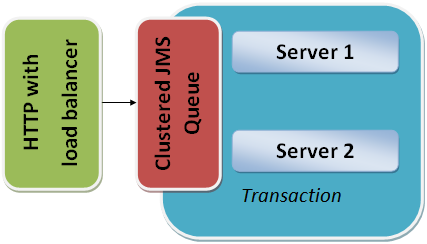
サーバーがダウンすると、トランザクションがロールバックされ、別のサーバーがメッセージを取得して処理を開始します。
注意: ロードバランサーはサーバー間で接続を透過的に切り替えないため、このプロセスの間に HTTP 接続が開いていると、このアプローチは機能しません。その場合、HTTP クライアントは要求を再試行する必要があります。
データベースでの状態の保持
クラスタリングされたデータベースがある場合、アプリケーションですべての状態をデータベースに保存し、それを使用してサーバー間で継続的にデータを複製できます。
プラス面:
-
簡単に実行できる
-
開発者の理解が深い
マイナス面:
-
すべての状態をデータベースに保存できるわけではない
ステートフルコンポーネントの処理
上記の手法で大部分のアプリケーションをサポートできますが、JVM 間でより深く状態を共有することが必要になる場合もあります。
この一般的な例として、Aggregator コンポーネントが挙げられます。たとえば、2 つの異なるプロデューサーのメッセージを集計するアグリゲーターがあるとします。プロデューサー #1 は、アグリゲーターにメッセージを送信します。アグリゲーターは、そのメッセージを受信して、プロデューサー #2 がメッセージを送信するまでメモリに保持します。
Producer #1 ---> |----------|
|Aggregator| --> Some other component
Producer #2 ---> |----------|プロデューサー #1 がメッセージを送信してからプロデューサー #2 がメッセージを送信する間にアグリゲーターのあるサーバーがダウンすると、プロデューサー #2 はそのメッセージを別のサーバーに送信できません (そのサーバーにプロデューサー #1 のメッセージがないため)。
この解決策は、Terracotta、Oracle Coherence、JGroups などのクラスタリングソフトウェアを介して Aggregator コンポーネントの状態を各マシンで共有することです。 これらのツールのいずれかを使用することで、プロデューサー #2 は別のサーバーにフェールオーバーできます。MuleSoft は、これらのツールで Mule をテストしていないため、正式にはサポートしていません。
プラス面:
-
すべてのクラスタリングケースで機能する
-
キャッシュとしても機能する
マイナス面:
-
MuleSoft で正式にサポートされていない
-
効率化のためにパフォーマンス調整が必要となる