パフォーマンス監視
パフォーマンステストのベストプラクティスを補うため、Mule Runtime Engine (Mule) がテスト中にコンシュームするリソースを監視します。それぞれの主なシステムリソースを監視するために最も重要なメトリクスと、CloudHub の監視で使用するツールについて以下に説明します。
以下に示すリソース監視コマンドは、sysstat がインストールされている Linux OS で使用できます。
CPU リソース
負荷が増大すると CPU リソースが枯渇することがあります。これらのリソースはいくつかの方法で監視できます。その中から 2 つを紹介します。
-
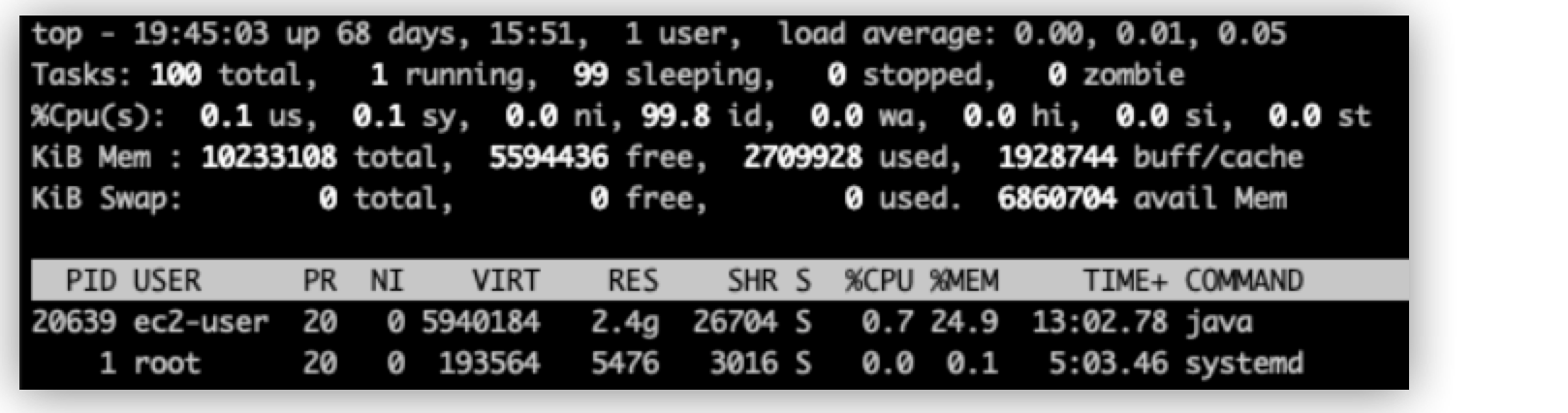
top コマンド:
top
%CPU メトリクスは、CPU 使用量をコア数で割った値です。
-
sar コマンド:
sar -u ALL $INTERVAL $COUNT
$INTERVAL はメトリクスを取得する時間間隔を指定し、$COUNT は収集するデータポイント数を指定します。
注目すべき主なメトリクスは次のとおりです。-
%sys、システムレベル (カーネル) での CPU 使用量を表示 -
%idle、CPU のアイドル時間のパーセンテージを表示
-

メモリリソース
ヒープやネイティブメモリ、オフヒープバッファなど、Mule によるメモリ使用状況を理解するため、メモリをいくつかの方法で監視します。その中から 2 つを紹介します。
-
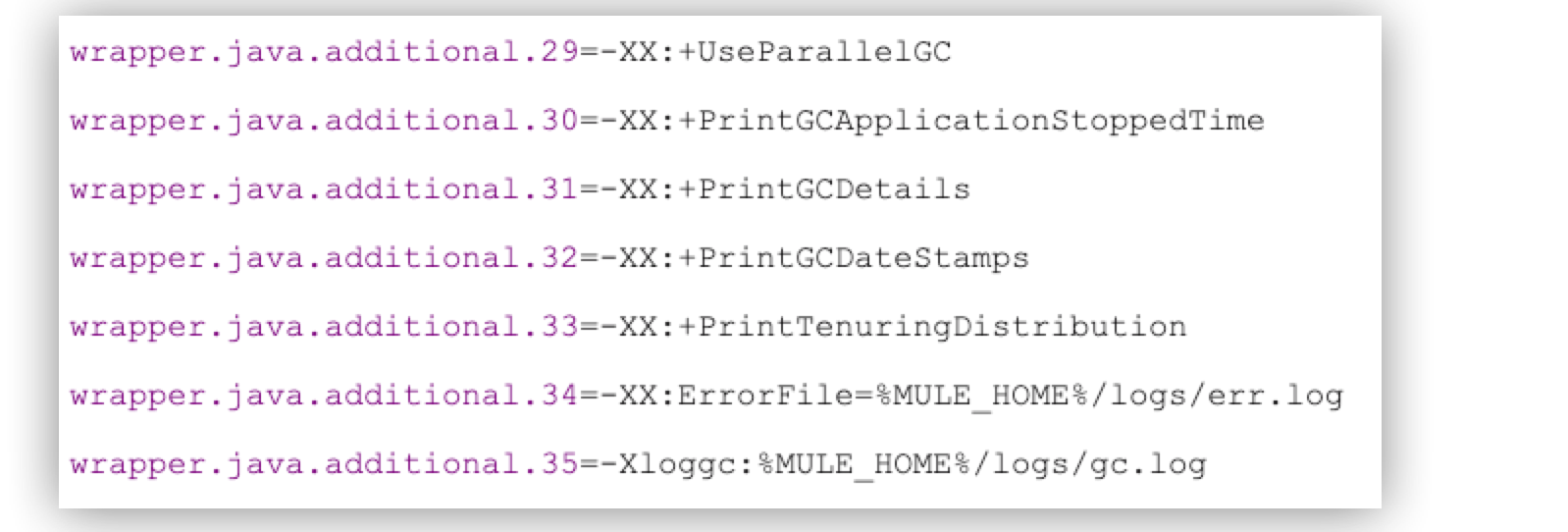
GC ログ
GC (ガベージコレクション) のログを有効にして、割り当てレート、オブジェクトの増大などの情報を入手します。また、ヒープでのアクティビティに関する情報も入手します。GC ログを有効にすると、ディスクオーバーヘッドが若干増大します。
-
sar コマンド:
sar -r $INTERVAL $COUNT
注目すべき主なメトリクスは次のとおりです。-
kbmemfree、使用できるメモリ量をキロバイト数で表示 -
kbmemused、使用中のメモリ量をキロバイト数で表示 -
kbcommit、現在のワークロードに必要な RAM またはスワップメモリの量をキロバイト数で表示
-

ディスクリソース
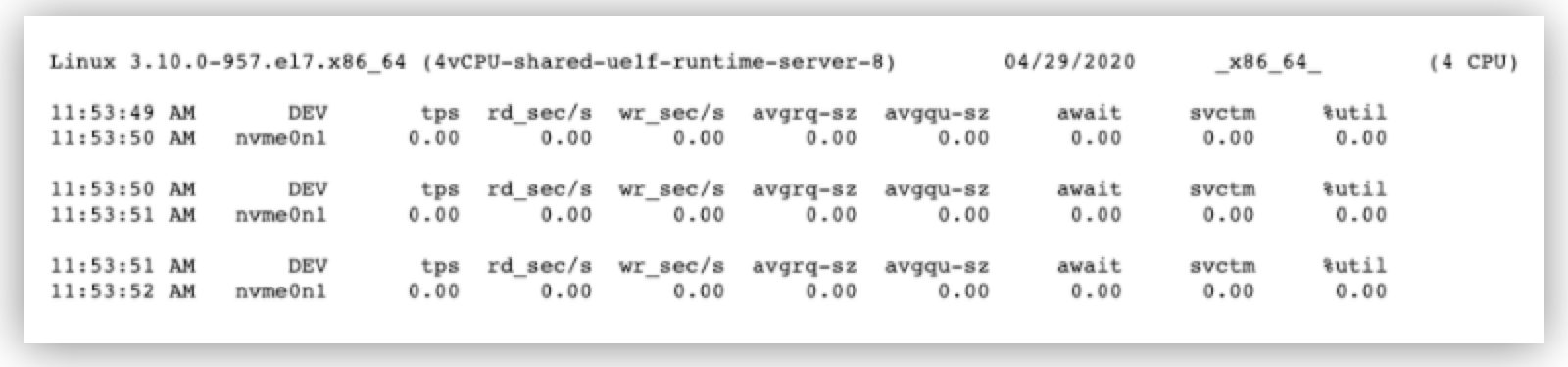
一部の Mule コンポーネントは、反復可能ストリームとして処理された大きなペイロードによって I/O (入出力) 要求が大量に発生し、リソースが大量に枯渇した書き込み操作やシナリオをログに記録します。ディスクリソースは sar コマンド sar -d -p $INTERVAL $COUNT を使用して監視します。
注目すべき主なメトリクスは次のとおりです。
-
await、デバイスを処理するために発行された I/O 要求の平均時間 (要求がキューに登録されていた時間と処理に要した時間の合計) を表示。 -
%util、デバイスの帯域幅使用量に対する、I/O 要求が発行されていた CPU 時間のパーセンテージによりデバイス飽和を表示。
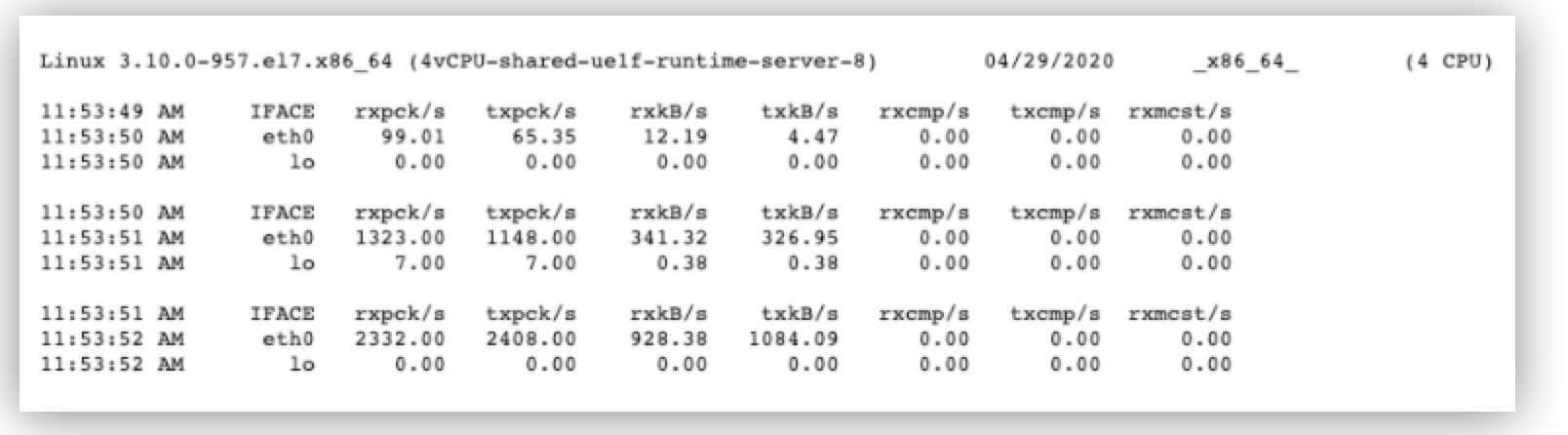
ネットワークリソース
Mule はネットワーク経由でいくつかのサービスと通信するため、ネットワークの使用量が飽和してボトルネックになることがあります。これを管理するには、使用できる帯域幅を把握し、使用量を監視する必要があります。これを行うためのシンプルは方法は、sar コマンド sar -n DEV $INTERVAL $COUNT を使用することです。
注目すべき主なメトリクスは次のとおりです。
-
rxpck/s、1 秒間に受信したパケットの合計数を表示。 -
txpck/s、1 秒間に送信したパケットの合計数を表示。
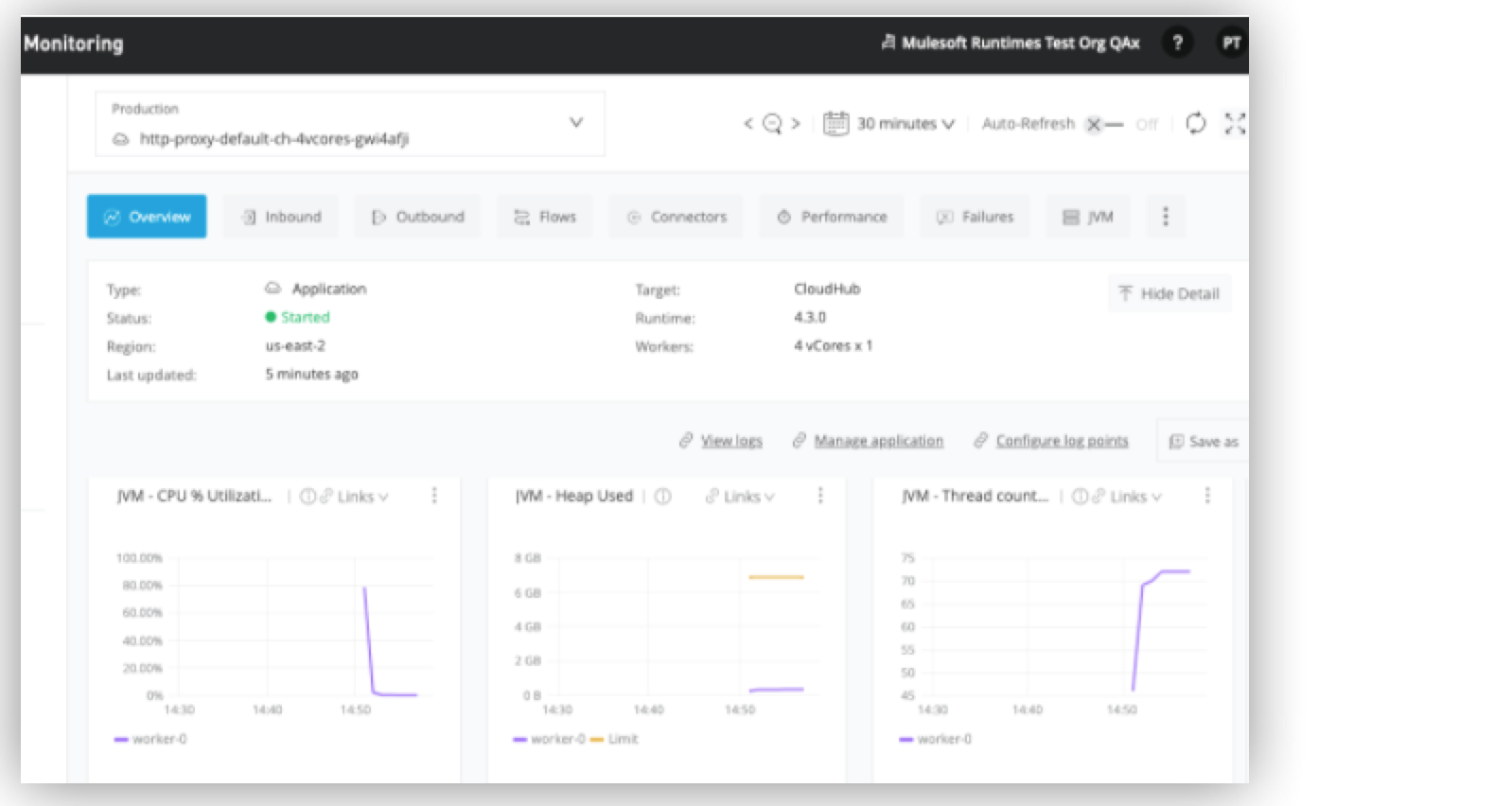
CloudHub の監視
CloudHub 環境での Mule アプリケーションのパフォーマンスは、Anypoint Runtime Manager ダッシュボードまたは Anypoint Monitoring を使用して監視できます。
-
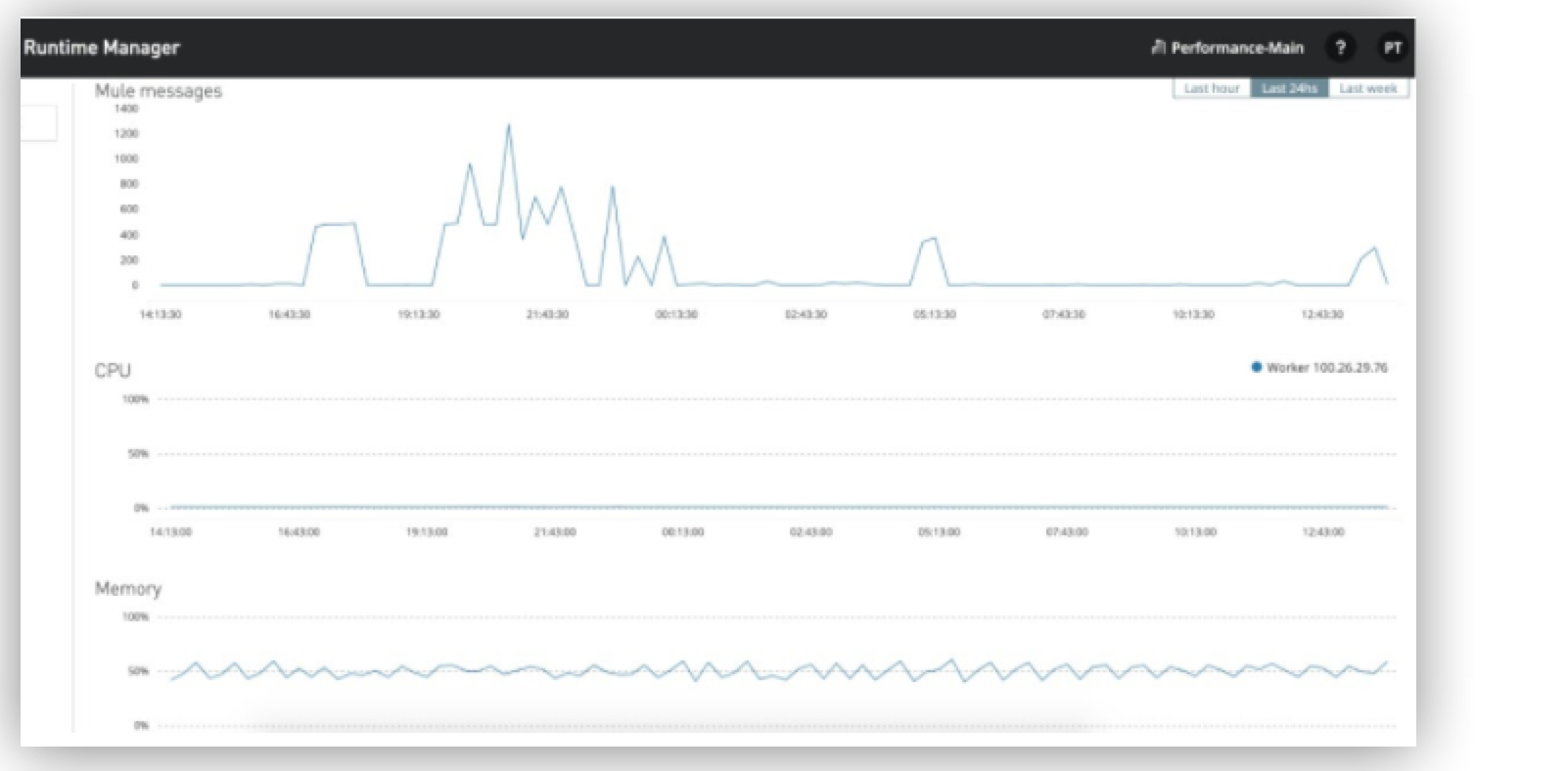
Runtime Manager ダッシュボード
このツールは、メッセージ数やトランザクション数、CPU やメモリの使用量、そして過去 1 時間、過去 24 時間、先週といった特定期間のメトリクスなど、パフォーマンスの重要なメトリクスを可視化します。
-
Anypoint Monitoring
このツールは、リソースを視覚的に表現する組み込みダッシュボードやカスタムダッシュボードを使用して、パフォーマンスのメトリクスを追跡して可視化します。さらに、Anypoint Monitoring では、異常の検出、問題のトラブルシューティング、未加工データを見ているだけでは気付かないトレンドの表示なども行えます。