CloudHub 2.0 High Availability and Disaster Recovery
CloudHub 2.0 provides high availability (HA) and disaster recovery (DR) capabilities for applications and protection against hardware failures.
CloudHub 2.0 leverages Amazon AWS for its cloud infrastructure, so availability is directly dependent on Amazon services. CloudHub 2.0 deployments and availability are region-based and correspond to Amazon regions. If an Amazon region goes down, the applications within that region are unavailable and not automatically replicated in other regions.
In the event of a network partition between the control plane and the runtime plane, applications in the runtime plane continue to run. The runtime plane continues to locally buffer log and telemetry data until control plane availability is restored.
CloudHub 2.0 leverages external messaging services, such as Anypoint MQ, to ensure message reliability through persistent queues. These external queues are highly available within a region, but they can be inaccessible for short periods, generally seconds to minutes, during a regional outage leading to some data loss. Communication with the queues resumes after the region becomes available. For more information, see Configuring Cross-Region Failover for Standard Queues.
Anypoint Object Store v2 enables CloudHub 2.0 applications to store data and states across various components and applications. Object Store v2 is maintained in the same region as the deployed CloudHub 2.0 application. Data persists and becomes available after the region returns to service. However, Object Store v2 is a regional service. It doesn’t provide any region failover functionality. You can’t access data in Object Store v2 from an application in a different region. Implement your own external storage solution for cross-region data persistence and access. Object Store v2 doesn’t provide periodic backups.
High Availability Versus Disaster Recovery
High availability (HA) is the measure of a system’s ability to remain accessible despite a system component failure. You generally implement HA by building in multiple levels of fault tolerance or load balancing capabilities into a system. In CloudHub 2.0, you can achieve high availability by deploying your application with multiple replicas.
Disaster recovery (DR) refers to the process of restoring a system to an acceptable previous state after a natural or man-made disaster, such as flooding, tornadoes, earthquakes, fires, power failures, server failures, and misconfigurations.
While they both increase overall availability, the difference is that with HA there’s generally no loss of service. HA retains the service, and DR retains the data, but with DR, there’s usually a slight loss of service while the DR plan executes and the system restores.
These key terms are essential to understanding HA and DR strategies in CloudHub 2.0:
- Recovery Time Objective (RTO)
-
The maximum amount of downtime a business can tolerate. The RTO represents the time it takes for the system to recover after a business disruption.
- Recovery Point Objective (RPO)
-
The maximum amount of time acceptable for data loss after a disaster. The RPO influences the frequency of data backups.
High Availability in CloudHub 2.0
CloudHub 2.0 implements high availability through built-in mechanisms, which MuleSoft manages automatically, and require no additional configuration.
- Multiple-Replica Deployment
-
If an application uses multiple replicas, CloudHub 2.0 deploys these replicas across two or more availability zones (AZs) by default. In case of an AZ failure, CloudHub 2.0 automatically restarts the application in a different AZ to maintain availability.
Disaster Recovery in CloudHub 2.0
Disaster recovery in CloudHub 2.0 focuses on the process of restoring systems after significant disruptions.
Global Distribution
You can deploy applications to CloudHub 2.0 in various global regions, including North America, South America, the European Union, and Asia-Pacific.
If you have the Global Deployment entitlement, and are in the US Cloud or EU cloud, you can deploy applications to CloudHub 2.0 in more than one runtime plane region.
You can host integrations in a runtime plane region that is closer to your services to reduce latency.
For a list of available runtime plane regions based on the control plane region where your organization is provisioned, see: Runtime Plane Regions and DNS Records.
The runtime plane region is the region where you deploy your CloudHub 2.0 applications and create CloudHub 2.0 private spaces.
Customer Responsibility for Disaster Recovery
If your organization has cross-region DR requirements for your applications, build your applications accordingly and consider deploying them across multiple regions. You can use a load balancer, either cloud-based or on-premises, for applications deployed to different regions to switch traffic to your backup region as part of your DR strategy.
For more information about how to deploy for HA and DR strategies, see High Availability and Disaster Recovery.
Disaster Recovery Use Cases and Architecture for the Runtime Plane
CloudHub 2.0 supports various multi-region disaster recovery strategies based on application impact and statefulness. These strategies typically involve a bring-your-own (BYO) global load balancer to manage traffic distribution and failover across regions.
To decouple your runtime plane application availability from the control plane region, configure your primary and backup runtime plane regions to be different from the region where your Anypoint Platform control plane is located. This is applicable to EU, with the control plane in eu-central-1, and US, with the control plane in us-east-1.
You can use a load balancer, either cloud-based or on-premises, for applications deployed to different regions to provide a better disaster recovery strategy.
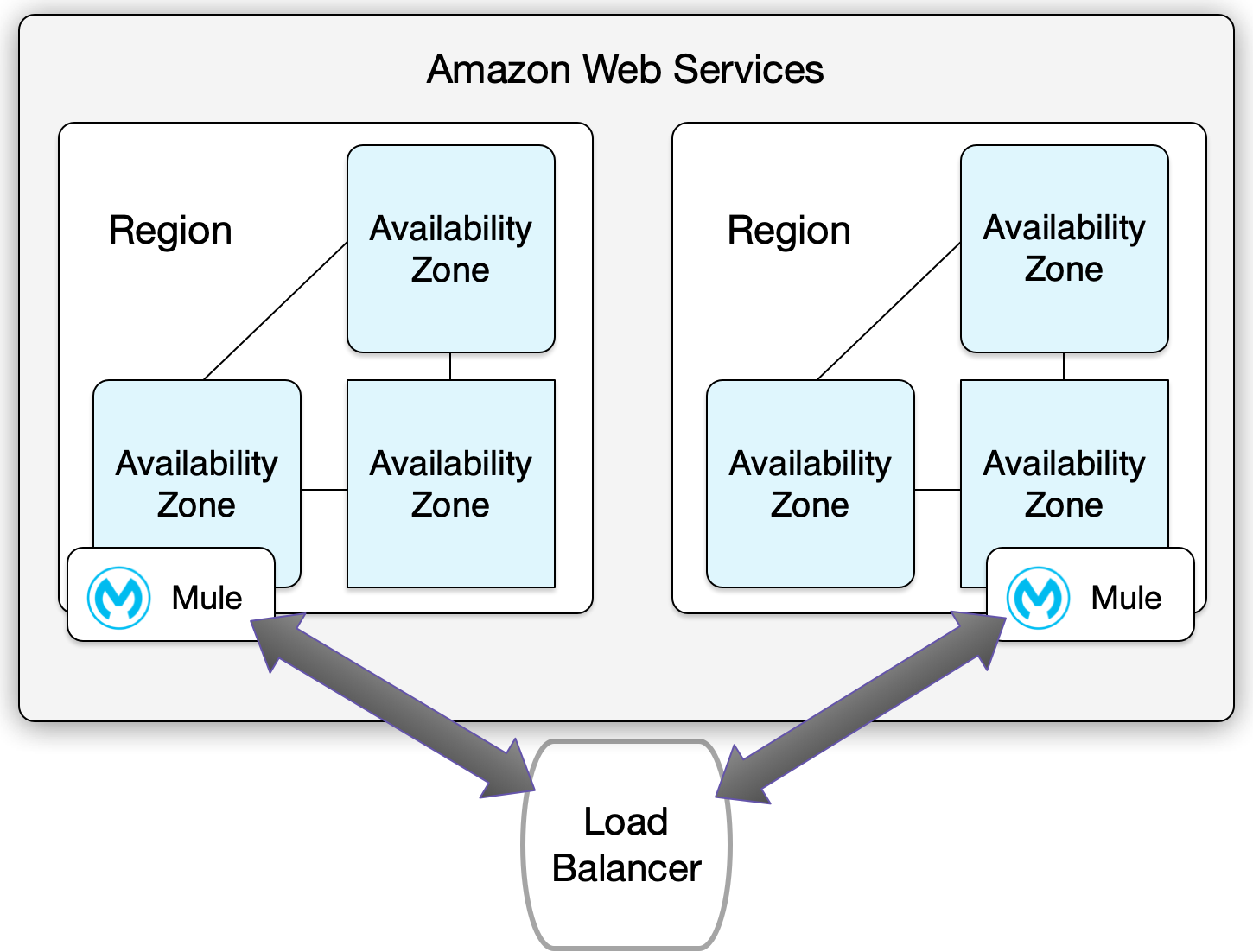
Use Case 1: Active-Active Configuration
When to Use
High-impact, stateless applications that require continuous availability with minimal downtime.
Application State
-
Set up the infrastructure with applications in different regions, with these applications running simultaneously and fully scaled up.
Traffic Management
-
Use a BYO global load balancer to distribute traffic between both regions.
-
Perform health checks to detect disasters.
-
Applications continue to run even if the control plane region is unavailable, as long as these applications are deployed in different regions than the control plane.
Licensing
-
For organizations using UBP, this configuration distributes Mule messages and Data throughput between the two regions. It consumes Mule flows based on the number of running replicas per application deployment.
-
For organizations not using UBP, this configuration consumes additional vCores.
Use Case 2: Warm Standby Configuration
When to Use
Medium-impact stateless APIs that tolerate brief downtime during failover or stateful APIs.
Application State
-
Set up the infrastructure across multiple regions. In the passive region, you can deploy your backup applications either in a fully scaled-up state or in a scaled-down state, with fewer replicas or smaller replica sizes. Scaled-down applications increase reliance on the control plane to redeploy and scale up during an outage in the primary runtime plane region.
-
You can configure CPU-based Horizontal Pod Autoscaling (HPA) where applicable if available to your organization. For more information, see Configuring Horizontal Autoscaling (HPA) for CloudHub 2.0 Deployments.
Traffic Management
-
Use a BYO global load balancer to route traffic to only one region at a time.
-
Perform health checks to determine DR and switch routing.
-
For non-HTTP use cases, such as Schedulers, externalize a DR flag in your application and use a Groovy script to enable and disable scheduler flows directly in the runtime plane. This reduces reliance on the control plane to trigger your backup applications via a cold standby approach.
Licensing
-
For organizations using UBP, this configuration doesn’t consume messages or throughput. The configuration consumes fewer flows if you configure the application with CPU-based HPA.
-
For organizations not using UBP, this configuration consumes lower vCores if the backup deployment is in a scaled-down state before it scales up in response to an outage in the primary region.
Recovery Time Objective
If the backup application is in a fully scaled state, you experience lower disruption in the event of an outage. If the backup application is in a scaled-down state, the RTO depends on the time it takes to scale the application up either through control-plane-triggered redeployments or through CPU-based HPA.
For integrating systems to resend events or data of in-flight transactions, capture recovery points in logs and monitoring. This builds reliability in your applications.
Use Case 3: Cold Standby Configuration
When to Use
Low-impact, stateless, or stateful applications that tolerate longer downtime during recovery.
Application State
-
Set up the infrastructure, but configure your application to a stopped state in the passive region.
-
Start the application only if you detect an outage.
Traffic Management
-
Use a BYO global load balancer to route traffic only to the region that is up.
-
Perform health checks to determine DR, and use scripts to start your applications in backup state and switch traffic routing.
-
If the control plane is unavailable, you can’t start the backup application in the runtime plane.
Runtime Plane High Availability and Disaster Recovery Summary
- High-Impact Stateless API
-
Use an active-active setup with active replicas in two regions and an external load balancer.
- High-Impact Stateful API
-
Use an external load balancer to route traffic, and perform health checks to determine DR and switch traffic.
- Medium-Impact Stateless and Stateful API
-
-
Use cold/warm standby, with applications deployed to both regions.
-
Stop or scale down the applications or replicas in the secondary region.
-
CloudHub 2.0 High Availability and Disaster Recovery Improvements
CloudHub 2.0 improvements over CloudHub include:
-
Loose coupling of the runtime plane region and control plane region due to a service-oriented architecture.
-
Clustering, which allows you to configure HA while running the process on a single primary replica.
-
Usage optimization by elastic scaling with Horizontal Pod Autoscaling (HPA) for warm standby if a failover is required.
-
Active/passive application management, which enables you to set schedulers and listening connectors, such as Anypoint MQ, DB, FTP, and Salesforce listeners, to a stopped or inactive state.
Externalize DR flags and expose REST endpoints to enable and disable flows via Groovy script as needed.
Disaster Recovery for Regional Services
Certain MuleSoft services are regional, which impacts their DR strategy.
- Anypoint MQ
-
This regional service runs in the same region as the application and provides OOTB region failover to a fallback region for standard queues. If an application’s RTO tolerates processing in-flight messages only after the primary site is backed up, Anypoint MQ failover is sufficient. Otherwise, configure a backup application in an active/passive setup, and resend in-flight events and data to the failover queue during a traffic switch. During backup with VM Queues and Anypoint MQ, data can be lost for a few minutes, depending on the configuration.
- Object Store v2
-
This regional service runs in the same region as the application and doesn’t provide any region failover functionality. An application deployed in a different region can’t access it. Bring your own external storage to access or back up data from different regions. Object Store v2 doesn’t retrieve data for regular backups. Caching in the object store, used for token management between calls, is region-specific, and you can’t transfer it to a secondary region.
Considerations for Disaster Recovery Implementations
Implementing a Disaster Recovery (DR) strategy for applications deployed to CloudHub 2.0 requires careful consideration of several key factors.
- Control Plane Availability
-
The CloudHub 2.0 management UI and control plane are available in the US East region of North America. They’re also available in EU, Canada, and Japan. For more information, see Control Plane and Runtime Plane Support Matrix.
- Caching
-
Use caching in the object store to share the tokens among various calls. Object stores are only region-specific, and you can’t transfer them to a secondary region.
- Rate-Limiting API Policies
-
Rate-limiting policies are currently set at the replica level. If you require rate limiting for in-flight transactions during DR, define custom policies using an external multiregion shared object store. Include a DR playbook with steps to adjust rate limits during and after DR.
- Schedulers
-
Many applications run on a scheduled basis to read from databases or files. In this case, schedulers continue to run even if the control plane is briefly unavailable.
- Listeners and Watermarks
-
For listeners like DB Table Row and Salesforce Events, use an external persistent store, like DB or Redis, across replicas and regions for polling and watermarks. This is crucial only if connectors use watermarks directly or indirectly.
Regional Differences and Disaster Recovery for Specific Regions
Some control plane regions have limitations for multiregion DR.
- Control Plane to Runtime Plane Ratio
-
Unlike the US (1:12) and EU (1:2) regions, Canada and Japan have a 1:1 control plane region to runtime plane region ratio.
Cross-Region Disaster Recovery Limitations
-
Cross-region runtime plane DR isn’t possible in Canada and Japan.
Disaster Recovery for the Anypoint Platform Control Plane
The Anypoint Control Plane encompasses additional Anypoint services apart from CloudHub 2.0. For more details, refer to the DR Test Summary.