データベースの照会の例
データベース用 Anypoint Connector (Database Connector) の Select 操作では、データベースのデータを選択できます。次の例は、Studio で [Input Parameters (入力パラメーター)]、[Fetch size (フェッチサイズ)]、[Max rows (最大行数)]、[Query timeout (クエリタイムアウト)] 項目を設定して操作を設定するときに役立ちます。また、動的クエリを設定する方法についても記載されています。
Studio で Select 操作を設定する
Studio で Select 操作を追加および設定する手順は、次のとおりです。
-
[Mule Palette (Mule パレット)] ビューで「
database」を検索し、[Select] 操作を選択します。 -
[Select] 操作を Studio キャンバスにドラッグします。
-
操作の設定画面の [General (一般)] タブで、[Connector configuration (コネクタ設定)] 項目の横にあるプラス記号 (+) をクリックし、グローバル要素設定項目にアクセスします。
-
データベース接続情報を指定し、[OK] をクリックします。
-
実行する SQL クエリを [SQL Query Text (SQL クエリテキスト)] 項目に設定します (例:
SELECT * FROM PLANET WHERE name = :name)。
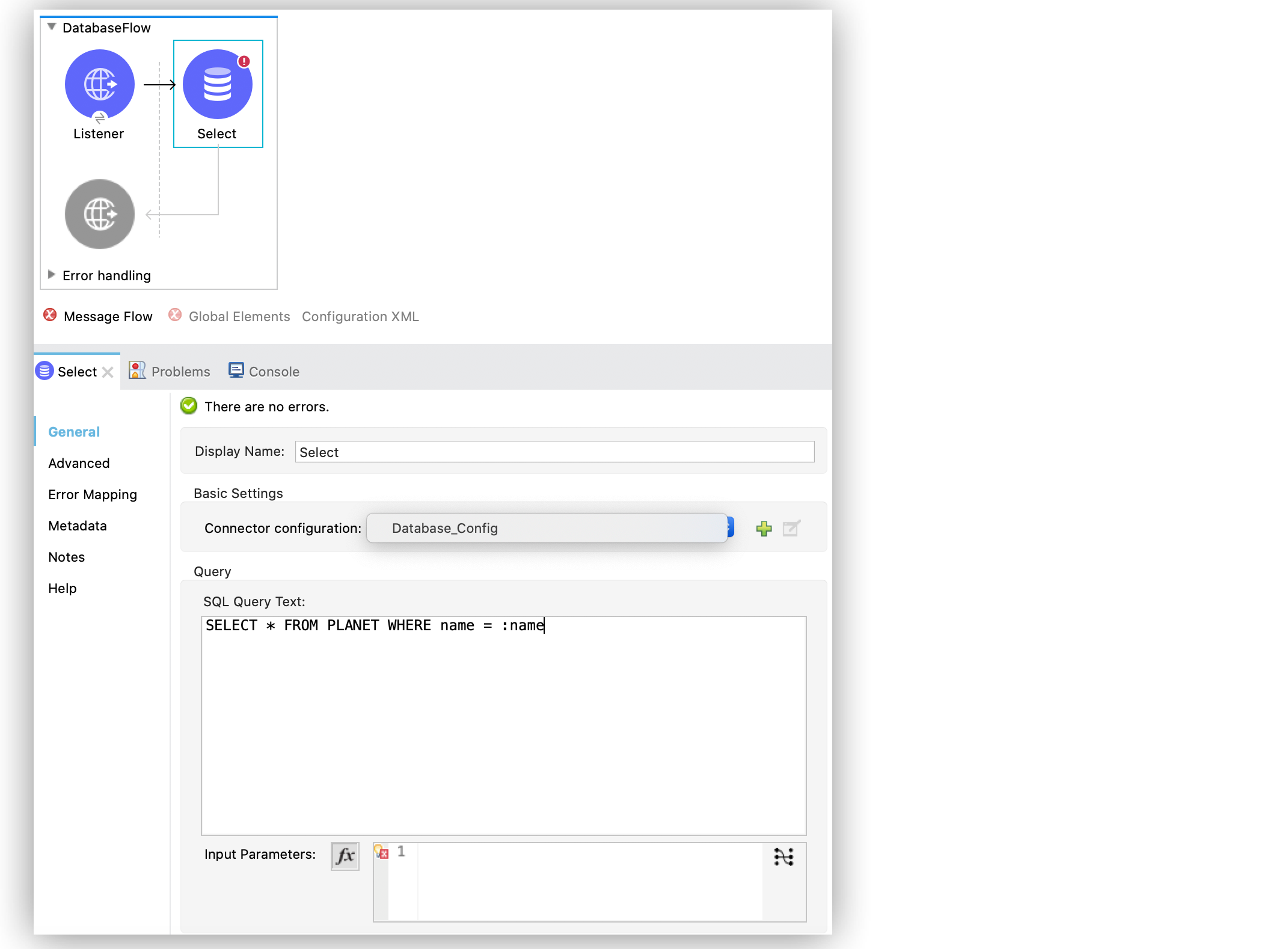
設定 XML エディターでは、<db:select> 設定は次のように記述されます。
<db:select config-ref="dbConfig">
<db:sql>SELECT * FROM PLANET WHERE name = :name</db:sql>
</db:select>Select 操作の [Input Parameters (入力パラメーター)] 項目を設定する
データベースクエリを保護するには、データベースで実行する SQL ステートメントに変数値を追加して、Select 操作の [Input parameters (入力パラメーター)] 項目を設定します。Select 操作の主な目標は、SQL クエリを提供し、パラメーターに DataWeave を使用することです。
指定するパラメーターは、JDBC プリペアードステートメントに設定する入力パラメーターの名前をキーとするマップです。SQL テキスト内でコロンプレフィックスを使用して各パラメーターを参照します (例: where id = :myParamName)。マップの値には、各パラメーターの実際の割り当てが含まれます。
入力パラメーターを使用して SQL SELECT ステートメントの WHERE 句を設定すると、クエリが SQL インジェクション攻撃の影響を受けなくなり、他の方法では不可能な最適化を実行でき、アプリケーションのパフォーマンスが向上します。
セキュリティ上の理由により、<db:sql>SELECT * FROM PLANET WHERE name = #[payload] </db:sql> は直接記述しないでください。
操作の入力パラメーターと出力パラメーターには DataSense を使用できます。Database Connector はクエリを分析し、SQL ステートメントの射影セクションを分析することで、クエリの出力構造を自動的に計算します。同時に、WHERE 句の条件をテーブル構造と比較して、DataSense 入力も生成します。これは、入力パラメーターを生成する DataWeave スクリプトをビルドするのに役立ちます。
次の例では、入力パラメーターをキー-値ペアとして指定します。
-
Studio のフローで、[Select] 操作を選択します。
-
操作設定画面で、[SQL Query Text (SQL クエリテキスト)] を
SELECT * FROM PLANET WHERE name = :name に設定します。 -
[Input Parameters (入力パラメーター)] を
{'name' : payload} に設定します。
このキーでは、コロン文字 (:) を使用して、名前によりパラメーター値を参照します。
![Studio での [Input parameters (入力パラメーター)] 項目の設定](_images/database-select-operation-2.png)
設定 XML エディターでは、<db:input-parameters> 設定は次のように記述されます。
<flow name="DatabaseFlow">
<db:select config-ref="dbConfig">
<db:sql>SELECT * FROM PLANET WHERE name = :name</db:sql>
<db:input-parameters>
#[{'name' : payload}]
</db:input-parameters>
</db:select>
</flow>|
Database Connector 1.4.0 では、SQL クエリでコロンをエスケープできます。SQL クエリでコロン文字 (
|
|
Database Connector 1.8.0 以降では、ダブルコロン (::) 表現を使用して、各コロンをエスケープせず SQL キャスト PostgreSQL および Snowflake 構文を受け入れることができます。エスケープされたコロンの動作に影響することもありません。例:
|
Select 操作の動的クエリを設定する
WHERE 句だけでなくクエリ自体の一部をパラメーター化する必要がある場合 (条件に依存するテーブルを比較するクエリや、プロジェクトテーブル列を変更する必要がある複雑なクエリなど)、動的クエリを設定できます。
次の例では、テーブルが変数に依存することを記述する文字列 $(vars.table) が含まれる完全な式を使用して動的クエリを設定します。一部のクエリテキストは動的 ("SELECT * FROM $(vars.table)) ですが、WHERE 句では、入力パラメーターを使用して引き続き WHERE 条件を定義します (この例では WHERE name = :name)。
-
Studio のフローで、[Select] 操作を選択します。
-
操作設定画面で、[SQL Query Text (SQL クエリテキスト)] 項目を
SELECT * FROM $(vars.table) WHERE name = :name に設定します。 -
[Input Parameters (入力パラメーター)] 項目を
{'name' : payload} に設定します。
次のスクリーンショットは、Studio の設定を示しています。
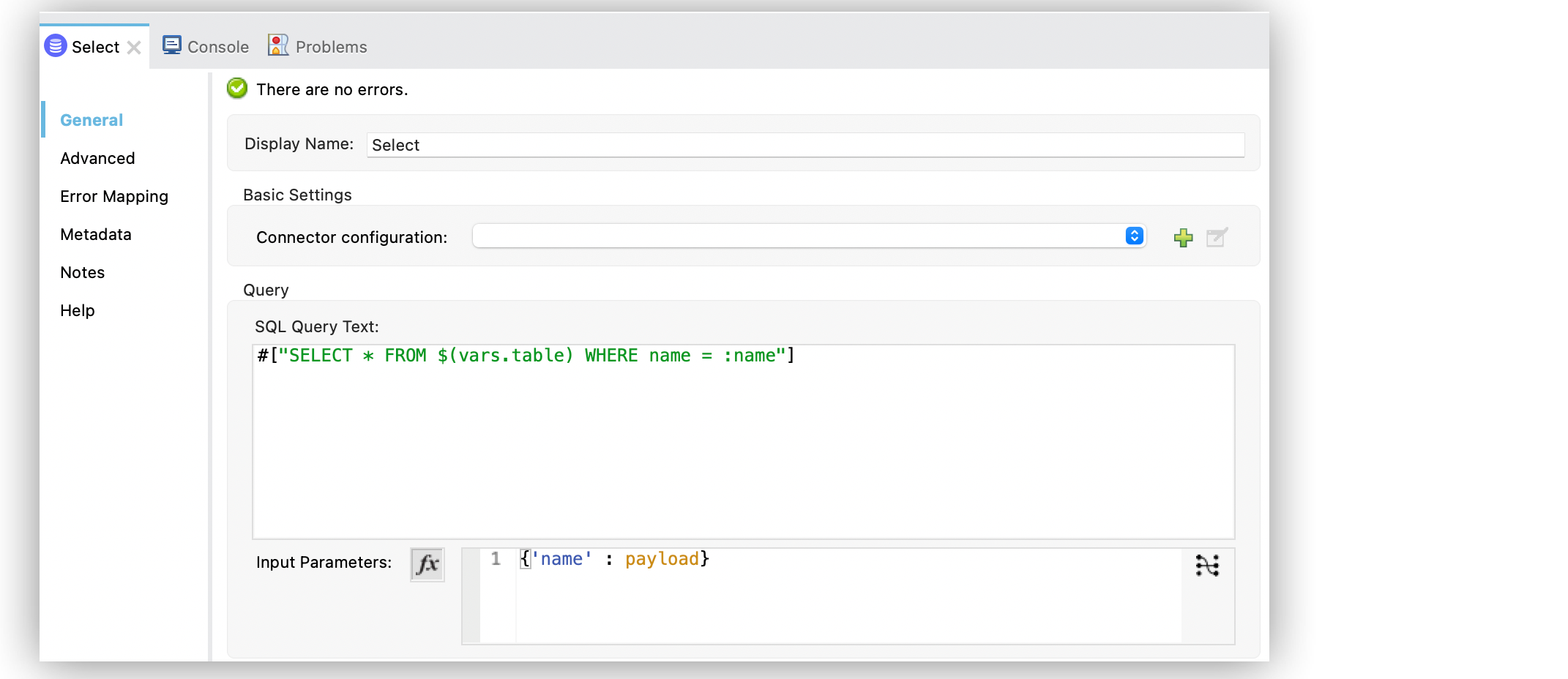
XML エディターでは、<db:sql> 設定は次のように記述されます。
<set-variable variableName="table" value="PLANET"/>
<db:select config-ref="dbConfig">
<db:sql>#["SELECT * FROM $(vars.table) WHERE name = :name"]</db:sql>
<db:input-parameters>
#[{'name' : payload}]
</db:input-parameters>
</db:select>入力パラメーターは WHERE 句のパラメーターにのみ適用できます。クエリの別の部分を変更するには、DataWeave 補間演算子を使用します。
設計時に式の値を使用できない場合があるため、動的クエリを使用すると、DataWeave 評価エラーがスローされたり、Select 操作の出力メタデータ (DataSense) に影響したりすることがあります。 値をデフォルトにして、前述の不都合を回避するには、次のように default 修飾子を使用します。
<set-variable variableName="table" value="PLANET"/>
<db:select config-ref="dbConfig">
<db:sql>#["SELECT * FROM $(vars.table default ASTEROIDS) WHERE name = :name"]</db:sql>
<db:input-parameters>
#[{'name' : payload}]
</db:input-parameters>
</db:select>大量の結果のストリーミング
インテグレーションのユースケースなど、多くのレコードを返すクエリでストリーミングを使用します。Mule 4 では、ストリーミングは透過的であり、常に有効になっています。
たとえば、10,000 行を返すクエリを送信した場合、それらすべての行を一度にフェッチしようとすると、ネットワークから大量の取り込みを行うため、パフォーマンスが低下し、すべての情報を RAM に読み込む必要があるため、メモリ不足になるリスクがあります。
ストリーミングでは、Database Connector は一度にクエリの一部のみをフェッチおよび処理するため、ネットワークとメモリの負荷が軽減されます。これは、コネクタが 10K 行を一度にフェッチしないことを意味します。代わりに、コネクタは小さなチャンクをフェッチし、そのチャンクがコンシュームされたら残りをフェッチします。
反復可能なストリームメカニズムを使用することもできます。これにより、DataWeave や他のコンポーネントで同じストリームを何度も処理できます。また、並列処理も可能です。
Select 操作の [Fetch Size (フェッチサイズ)] と [Max Rows (最大行数)] 項目を設定する
Mule Runtime Engine (Mule) では、Database Connector でストリーミングを管理できますが、データの大きなチャンクをデータベースから Mule に移動することをお勧めできない場合もあります。ストリーミングを使用しても、単純な SQL クエリで、各行に大量の情報を含む多くの行が返される可能性はあります。結果を制限するには、[Fetch size (フェッチサイズ)] 項目と [Max rows (最大行数)] 項目を設定します。
次の例では、Select 操作でこれらの項目を設定します。この構文は、フェッチできる合計行数は 1000 ([Max rows (最大行数)] 値) 以下、同時にフェッチできる行数は 200 ([Fetch size (フェッチサイズ)] 値) 以下であることを Database Connector に指示します。これにより、ネットワークとメモリの負荷が大幅に軽減されます。[Fetch size (フェッチサイズ)] 値は JDBC ドライバープロバイダーごとに異なって適用され、多くの場合、デフォルトで 10 に設定されます。この組み合わせにより、取得される情報の総量が制限され ([Max rows (最大行数)] 値)、ネットワーク経由でデータベースから小さいチャンクのデータが返されることが保証されます ([Fetch size (フェッチサイズ)] 値)。
-
Studio のフローで、[Select] 操作を選択します。
-
操作設定画面で、[SQL Query Text (SQL クエリテキスト)] を
select * from some_table に設定します。 -
[Advanced (詳細)] をクリックし、[Fetch size (フェッチサイズ)] を
200、[Max rows (最大行数)] を 1000 に設定します。
![Studio での [Fetch size (フェッチサイズ)] 項目と [Max row (最大行数)] 項目の設定](_images/database-select-operation-4.png)
[Configuration XML (設定 XML)] エディターで、fetchSize および maxRows の設定は次のように記述されます。
<db:select fetchSize="200" maxRows="1000" config-ref="dbConfig">
<db:sql>select * from some_table</db:sql>
</db:select>Select 操作の [Query Timeout (クエリタイムアウト)] 項目を設定する
多くの場合、次の要因によりクエリの実行が遅延します。
-
非効率なクエリ (多くの行を反復処理する不適切なインデックスを持つクエリなど)
-
混雑している RDBMS またはネットワーク
-
ロック競合
クエリの実行時にタイムアウトしないようにするには、[Query timeout (クエリタイムアウト)] 項目と [Query time unit (クエリ時間単位)] 項目を設定します。すべての Database Connector 操作でタイムアウトの設定がサポートされています。
次の例は、タイムアウトを設定する方法を示しています。
-
Studio のフローで、[Select] 操作を選択します。
-
操作設定画面で、[SQL Query Text (SQL クエリテキスト)] を
select * from some_table に設定します。 -
[Advanced (詳細)] タブで、JDBC ドライバーが実行中のステートメントをキャンセルしようとするまでの最短時間を [Query timeout (クエリタイムアウト)] に設定します。例:
0。 -
[Query timeout (クエリタイムアウト)] に使用できる時間単位を [Query timeout unit (クエリタイムアウト単位)] に設定します。例:
SECONDS。
![Studio での [Query timeout (クエリタイムアウト)] 項目の設定](_images/database-select-operation-5.png)
[Configuration XML (設定 XML)] エディターで、queryTimeout および SECONDS の設定は次のように記述されます。
<db:select queryTimeout="0" queryTimeoutUnit="SECONDS" config-ref="dbConfig">
<db:sql>select * from some_table</db:sql>
</db:select>