バッチ処理
|
このバージョンの Mule は、拡張サポートが終了する 2023 年 5 月 2 日にその すべてのサポートが終了しました。 このバージョンの Mule を使用する CloudHub には新しいアプリケーションをデプロイできなくなります。許可されるのはアプリケーションへのインプレース更新のみになります。 標準サポートが適用されている最新バージョンの Mule 4 にアップグレードすることをお勧めします。これにより、最新の修正とセキュリティ機能強化を備えたアプリケーションが実行されます。 |
| バッチ処理は Mule Enterprise ランタイム専用です。 |
Mule では、メッセージをバッチで処理できます。
アプリケーション内で Batch Job スコープを開始できます。これによって、メッセージが個々のレコードに分割され、各レコードに対してアクションが実行され、その結果が報告され、場合によっては処理された出力が他のシステムまたはキューに転送されます。
たとえば、次の場合にバッチ処理を使用できます。
-
NetSuite と Salesforce 間の連絡先の同期など、ビジネスアプリケーション間でデータセットを同期する。
-
フラットファイル (CSV) から Hadoop へのデータのアップロードなど、対象システムへの情報の抽出、変換、および読み込み (ETL) を行う。
-
API から従来のシステムへの大量の受信データを処理する。
Mule 3.x のバッチ処理にすでに精通している場合は、記事「バッチモジュールの移行」で Mule 4.x のバッチとの違いの概要を確認してください。
概要
Mule アプリケーション内では、バッチ処理は、個々のレコードに分割される、メモリ量を上回るデータセットを非同期で処理するための構造を提供します。バッチジョブを使用すると、ソースデータを自動的に分割して永続的なキューに保存する信頼できるプロセスを記述できるため、大量のデータセットを処理しながら信頼性を提供できます。アプリケーションを再デプロイする場合、または Mule がクラッシュした場合、ジョブが停止した位置でジョブの実行を再開できます。
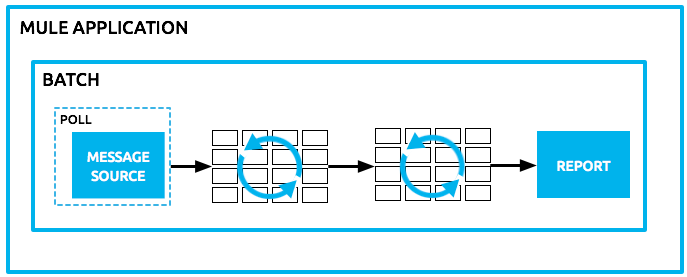
これで、個々のレコードの処理の観点でジョブが表わされるため、レコードレベルの変数、集約、およびエラー処理のセマンティクスが提供されます。
基本構造
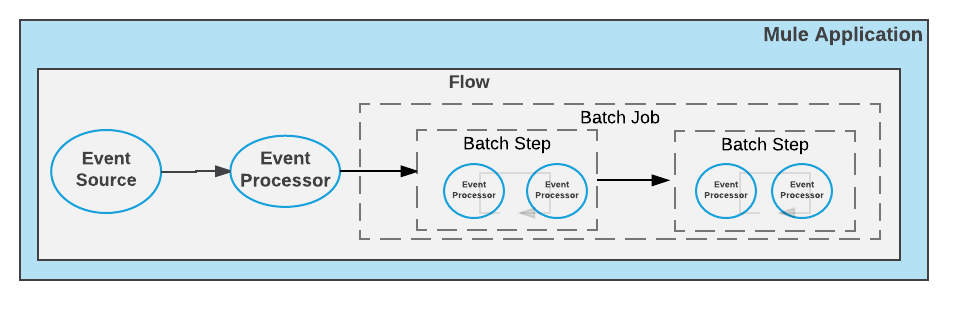
Mule のバッチ処理の中心は Batch Job です。Batch Job は、大きなメッセージを Mule が非同期で処理するレコードに分割するスコープです。フローがメッセージを処理する方法と同様に、Batch Job はレコードを処理します。
バッチ XML 構造は Mule 4.0 で変更されました。次の例は、バッチ要素を強調表示するため省略された詳細を示しています。
<flow name="flowOne">
<batch:job jobName="batchJob">
<batch:process-records>
<batch:step name="batchStep1">
<event processor/>
<event processor/>
</batch:step>
<batch:step name="batchStep2">
<event processor/>
<event processor/>
</batch:step>
</batch:process-records>
</batch:job>
</flow>Batch Job には、レコードが Batch Job 内を移動するときにレコードに対して実行する 1 つ以上の Batch Step が含まれます。
Batch Job の各 Batch Step には、レコードに対してその中に含まれるデータを変換、転送、強化、または別の方法で処理するプロセッサーが含まれます。既存の Mule プロセッサーの機能を利用することで、Batch Job がレコードを処理する方法を Batch Step で柔軟に制御できます。詳細は、「Batch Step 処理の絞り込み」を参照してください。
フローが Batch Job の process-records セクションに到達すると、その Batch Job が実行されます。トリガーされると、Mule は新しい Batch Job インスタンスを作成します。 ジョブインスタンスが実行可能になると、バッチエンジンは各レコードブロックのタスクを I/O プールに送信して各レコードを処理します。並列処理はレコードブロックレベルで自動的に行われます。Mule Runtime Engine では、自動調整機能によって、使用するスレッド数と適用する並列性レベルが決定されます (「実行エンジン」参照)。
Batch Job の実行が開始されると、Mule は受信メッセージをレコードに分割して永続的なキューに保存し、処理するレコードのブロックでそれらのレコードのクエリとスケジュールを実行します。デフォルトでは、ランタイムは各 Batch Step に 100 件のレコードを保存します。必要なパフォーマンスに応じて、このサイズをカスタマイズできます。詳細は、「Batch Step 処理の絞り込み」を参照してください。
すべてのレコードがすべての Batch Step を通過したら、ランタイムは Batch Job インスタンスを終了し、処理中に成功したレコードと失敗したレコードを示す Batch Job の結果を報告します。
エラー処理
Batch Job は、Batch Job 全体の失敗を回避するため、処理中に発生する可能性があるレコードレベルの失敗を処理できます。また、バッチ処理中に Mule が変数 (上記で割り当て済み) に従って Batch Job 内のレコードの転送またはアクションを実行できるように、個々のレコードの変数を設定または削除できます。詳細は、「Batch Job 中のエラー処理」を参照してください。
Batch Job と Batch Job インスタンスの比較
上記のコンテキストで定義されていますが、Batch Job と Batch Job インスタンスという用語は相互に関連するため、詳しく説明します。
-
Batch Job は、Mule がメッセージペイロードをレコードのバッチとして処理する、アプリケーションのスコープ要素です。Batch Job という用語は、Load and Dispatch (読み込みおよびディスパッチ)、Process (プロセス)、On Complete (完了時) の 3 つの処理フェーズすべてを含みます。
-
Batch Job インスタンスは、Mule フローが Batch Job を実行するたびに Mule アプリケーションで発生します。Mule は Load and Dispatch (読み込みおよびディスパッチ) フェーズで Batch Job インスタンスを作成します。すべての Batch Job インスタンスは、Batch Job インスタンス ID と呼ばれる一意の文字列を使用して内部的に識別されます。
この識別子は、たとえばデータを参照および管理するためにローカルジョブインスタンス ID を外部システムに渡したり、ジョブのカスタムログを改善したり、特定の Batch Job インスタンスに関する重要なイベントのメールまたは SMS 通知を送信したりする場合に役立ちます。この識別子とそのカスタマイズ方法についての詳細は、「Batch Job インスタンス ID」を参照してください。
Batch Job 処理フェーズ
各 Batch Job には 3 つの異なるフェーズがあります。
-
Load and Dispatch (読み込みおよびディスパッチ)。
-
Process (プロセス)。
-
On Complete (完了時)。
Load and Dispatch (読み込みおよびディスパッチ)
この最初のフェーズは暗黙的です。このフェーズでは、ランタイムはすべてのバックグラウンド処理を実行して Batch Job インスタンスを作成します。基本的に、これは Mule がバッチとして処理するためにシリアル化されたメッセージペイロードをレコードのコレクションに変換するフェーズです。このアクティビティが発生するために何も設定する必要はありませんが、Mule がこのフェーズ中に完了するタスクを理解しておくと役立ちます。
-
Mule は DataWeave を使用してメッセージを分割します。この最初の手順では、新しい Batch Job インスタンスが作成されます。
Mule は batchJobInstanceId 変数を使用して Batch Job インスタンス ID を公開します。この変数はすべてのステップと on-complete フェーズで使用可能です。 -
Mule は永続的なキューを作成して新しい Batch Job インスタンスに関連付けます。
キュー名には
BSQ のプレフィックスが付けられ、それを Anypoint Runtime Manager で確認できます。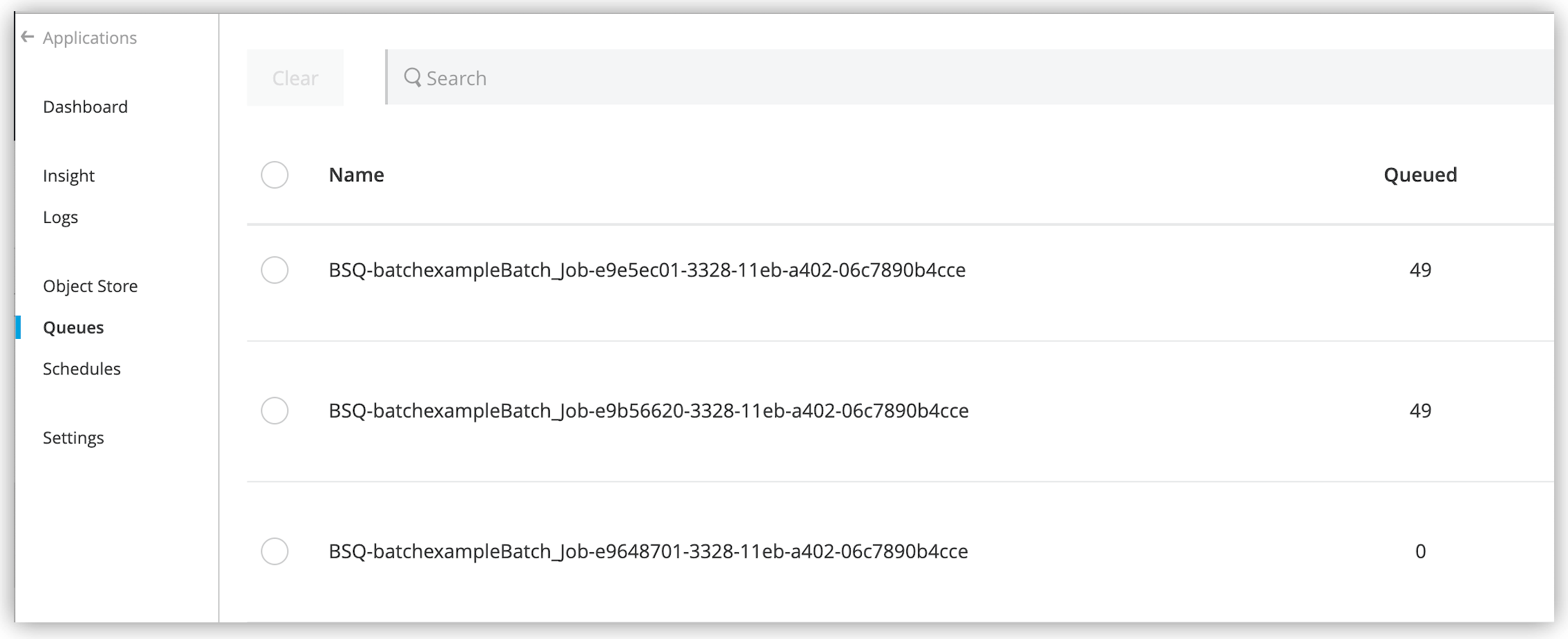
-
スプリッターによって生成された各アイテムに対して、Mule はレコードを作成してキューに保存します。このアクティビティは「オールオアナッシング」です。つまり、Mule がすべての項目のレコードを正常に生成してキューに追加するか、このフェーズ中にメッセージ全体が失敗します。
-
Mule は Batch Job のインスタンスとキュー内のすべてのレコードを処理用の最初の Batch Step に渡します。
このフェーズが完了したら、フローは Batch Job がすべてのレコードの処理を完了するのを待たずに実行を続行します。この動作は、次のフェーズである Process (プロセス) が非同期なために発生します。
Process (プロセス)
Process (プロセス) フェーズ中、Mule はバッチ内のレコードの処理を非同期で処理します。各レコードは最初の Batch Step のプロセッサーを通過し、次の Batch Step で処理されるのを待つ間に元のキューに戻されます。すべてのレコードがすべての Batch Step を通過するまでこの処理が繰り返されます。Batch Job インスタンスごとに 1 つのキューのみが存在します。レコードは各 Batch Step でキューから選択され、処理されてから、キューに戻されます。各レコードは、このキュー内にある間にどの段階の処理が完了したかを追跡します。ただし、たとえば Batch Step にアグリゲーターが含まれる場合など、内部目的で Batch Job インスタンスが追加のキューを作成する場合があります。
Batch Job インスタンスは、キューに追加されたすべてのレコードが 1 つの Batch Step での処理を終了するのを待たずに、レコードを次の Batch Step に転送します。
Mule は、すべてのレコードが各 Batch Step での処理に成功したか失敗したときに、そのリストを保持します。レコードが Batch Step でイベントプロセッサーによる処理に失敗した場合、ランタイムはバッチの処理を続行し、後続の各 Batch Step では失敗したレコードをスキップします。
このフェーズの終了時に Batch Job インスタンスは完了し、消滅します。
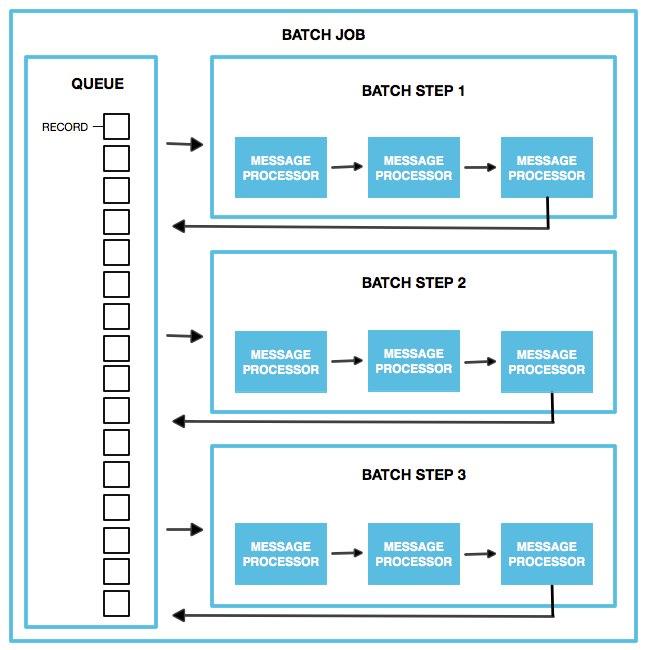
レコードの単純な処理以外に、Batch Step 内でレコードを使用してできることがいくつかあります。
-
各 Batch Step 内に acceptExpressions を追加して検索条件を追加し、ステップが特定のレコードを処理しないようにする。 たとえば、先行するステップで処理に失敗したレコードがステップで処理されないようにする検索条件を設定できます。
-
Batch Aggregator プロセッサーを使用して、レコードをグループに集約し、それらを一括更新/挿入で外部ソースまたはサービスに送信可能。 たとえば、各連絡先 (レコード) を Google コンタクトにバッチで更新/挿入する代わりに、100 件のレコードを蓄積するようにバッチアグリゲーターを設定して、そのすべてを 1 つのチャンクで Google コンタクトに更新/挿入できます。
詳細は、「Batch Step 処理の絞り込み」を参照してください。
On Complete (完了時)
このフェーズ中、必要に応じて、特定の Batch Job インスタンスで処理したレコードのレポートまたは概要を作成するようにランタイムを設定できます。このフェーズは、入力データに存在する可能性がある問題に対処できなかったレコードに関するインサイトをシステム管理者と開発者に提供するために存在します。
<batch:job name="Batch3">
<batch:process-records>
<batch:step name="Step1">
<batch:record-variable-transformer/>
<ee:transform/>
</batch:step>
<batch:step name="Step2">
<logger/>
<http:request/>
</batch:step>
</batch:process-records>
<batch:on-complete>
<logger/>
</batch:on-complete>
</batch:job>Mule が Batch Job 全体を実行したら、出力は Batch Job 結果オブジェクト (BatchJobResult) になります。Mule は Batch Job を非同期の一方向フローとして処理するため、バッチ処理の結果は、そのトリガー元のフローに戻されることも、呼び出し元への応答として返されることもありません。データを Batch Job に送り込むイベントソースは、要求 - 応答ではなく一方向である必要があります。
出力を操作する方法は 2 つあります。
-
On Complete (完了時) フェーズで、失敗したレコード数や正常に処理されたレコード数などの情報を使用する DataWeave を使用して、エラーが発生した可能性があるステップに関するレポートを作成する。
-
Mule アプリケーションの他の場所にある Batch Job 結果オブジェクトを参照し、特定の Batch Job インスタンスで処理に失敗したレコード数などのバッチメタデータを取得および使用する。
On Complete (完了時) フェーズを空のままにし、アプリケーションの他の場所で Batch Job 結果オブジェクトを参照しない場合は、失敗したか成功したかに関係なく、Batch Job は単に完了します。
|
失敗または成功したレコードについて報告するための何らかのメカニズムを設定し、必要な場合は追加アクションの実行を促すことをお勧めします。 |
変数の伝播
Batch Job インスタンスの各処理済みレコードは、ブロックの実行前に提供された変数と値で開始されます。各レコードには独自の一連の変数があるため、特定のレコードの処理中の新しい変数またはすでに存在している変数の変更は、別のレコードの処理中に表示されません。それらの変数 (および変更) は、レコードごとに異なる Batch Step で伝播されます。たとえば、レコード R1 で変数 varName: "hello" を設定し、レコード R2 で varName: "world" を設定して、レコード R3 でこの変数を設定しない場合、次のステップで R1 には値 "hello" が表示され、R2 には "world" が表示されて、R3 にはその変数の値が表示されません。
On Complete フェーズでは、これらのどの変数 (元の変数も含む) も表示されません。このフェーズでは、最終結果のみを使用できます。さらに、Batch Job インスタンスは、フローの残りの部分から非同期で実行されるため、Batch Step または On Complete フェーズで設定された変数は、Batch スコープ外で表示されません。
Scheduling Strategy (スケジュール戦略)
Mule アプリケーションには、複数の Batch Job 定義を含めることができます。各定義には固有のスケジュール戦略が設定されます。スケジュール戦略を使用すると、特定の Batch Job のインスタンスの実行方法を制御できます。
-
ORDERED_SQUENTIAL (デフォルト): 複数のジョブインスタンスが同時に実行可能状態になっている場合、インスタンスは作成タイムスタンプに基づいて 1 つずつ実行されます。 -
ROUND_ROBIN: この設定では、使用可能なリソースをラウンドロビンアルゴリズムを使用して割り当てて、Batch Job の実行可能なすべてのインスタンスを実行しようとします。他のジョブ実行に副次的影響を及ぼすジョブ実行がないと保証できる場合は、
ROUND_ROBIN オプションが役立ちます。データ同期ジョブの場合、同時に実行される 2 つのジョブによって同じレコードが更新される可能性があるため、このオプションは適していません。ジョブ実行の順序が保証されないため、結果は以前のバージョンのデータになる可能性があります。ただし、Batch Job によってデータベースから新しいレコードのみを取得したり、SFTP サーバーから個別ファイルを取得したりするときに、すべてのレコードが完全に独立していることが確信できる場合は、この戦略を安全に使用してジョブの実行を並列化することができます。
これらのいずれの戦略でも、レコードが順番に処理されることは保証されません。 戦略は Batch Job でのレコードの実行順序は制御せず、各インスタンスに含まれるレコード数によって決まることもありません。