バッチ処理
Mule バッチ処理コンポーネントは、メモリ量を上回るデータセットの信頼できる非同期処理を行うよう設計されています。コンポーネントには Batch Job、Batch Step、Batch Aggregator があります。Batch Job コンポーネントではソースデータを自動的に分割して永続的なキューに格納するため、大量のデータセットを処理しながら信頼性を提供できます。アプリケーションを再デプロイする場合、または Mule がクラッシュした場合、ジョブが停止した位置でジョブの実行を再開できます。
|
Mule バッチ処理コンポーネントは Mule の Enterprise Edition (EE) バージョン専用です。オープンソースの Mule Kernel を通じてコンポーネントを使用することはできません。 Mule 3.x でのバッチ処理に慣れている場合は、Mule 4.x でのバッチ処理の違いの概要について「Batch Module の移行」を参照してください。 |
バッチ処理の一般的なユースケースを次に挙げます。
-
NetSuite と Salesforce 間の連絡先の同期など、ビジネスアプリケーション間でデータセットを同期する。
-
フラットファイル (CSV) から Hadoop へのデータのアップロードなど、対象システムへの情報の抽出、変換、および読み込み (ETL) を行う。
-
API から従来のシステムへの大量の受信データを処理する。
例については Batch コンポーネントの設定 and Batch Job 中のエラー処理 を参照してください。
アーキテクチャ
Mule バッチ処理コンポーネントでは、レコードを一括で処理できるように準備し、これらのレコードでプロセッサーを実行して、処理の結果に関するレポートを発行します。レコードの準備とレポートは Batch Job コンポーネント内で行われます。処理は 1 つ以上の Batch Step コンポーネント内で行われ、必要に応じて、Batch Step コンポーネント内の Batch Aggregator コンポーネント内で行われます。
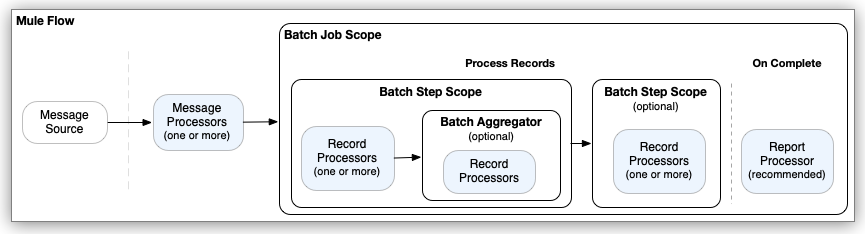
バッチ処理コンポーネント内に配置したプロセッサーはレコードに対するアクションを実行します。各レコードは Mule イベントに似ています。プロセッサーは payload キーワードを使用して各レコードのペイロードへのアクセス、変更、ルーティングを行うことができ、vars を使用して Mule 変数を操作できます。ただし、Batch Job コンポーネントへの入力から Mule 属性 (attributes) へのアクセスや変更を行うことはできません。
次の例は、バッチ処理を実行し、その処理の結果が記載されたレポートを返す Mule フローの XML 構造の概要を示しています。
<flow name="mule-flow" >
<!-- processor that triggers the flow -->
<event source placeholder />(1)
<!-- message processors -->
<processor placeholder />(2)
<processor placeholder />
<!-- Batch Job component -->
<batch:job name="Batch_Job"/>(3)
<!-- record processing occurs within process-records -->
<batch:process-records >(4)
<!-- Batch Step component -->
<batch:step name="Batch_Step"/>(5)
<!-- processors that act on records -->
<processor placeholder />
<processor placeholder />
<!-- Batch Aggregator component -->
<batch:aggregator />(6)
<!-- processor that acts arrays of records -->
<processor placeholder />
</batch:aggregator>
</batch:step>
<!-- another Batch Step component -->
<batch:step name="Batch_Step1"/>(7)
<!-- processor that acts on records -->
<processor placeholder />
</batch:step>
</batch:process-records>
<!-- processing of a batch job report takes place in on-complete -->
<batch:on-complete>(8)
<!-- processor for result of a batch job -->
<processor placeholder />
</batch:on-complete>
</batch:job>
</flow>
</mule>例に含まれる <processor placeholder /> などのさまざまな placeholder エントリはコネクタ操作、Mule コアコンポーネントなど、Mule メッセージ、レコード、バッチ処理レポートを処理する実際のプロセッサーの場所を示している点に注意してください。これらは実際のプロセッサーではありません。
-
Mule イベントソースにより Mule フローがトリガーされます。一般的なイベントソースには HTTP 用 Anypoint Connector (HTTP Connector)、Scheduler コンポーネント、新しいファイルをポーリングするコネクタ操作からの HTTP リスナーなどのリスナーがあります。
-
Batch Job コンポーネントのアップストリームに配置されたプロセッサーは通常コンシュームする Batch Job コンポーネントメッセージを取得し、必要に応じてこのメッセージを準備します。たとえば、HTTP 要求操作では処理するデータを取得する場合があり、Transform Message コンポーネントの DataWeave スクリプトではデータを受信する Batch Job コンポーネントにとって有効な形式に変換する場合があります。
-
Batch Job コンポーネントでフローのアップストリームプロセッサーからメッセージを受信すると、Load and Dispatch フェーズが開始されます。このフェーズでは、コンポーネントでレコードとして処理するための入力が準備されます。これには処理が行われる Batch Job インスタンスの作成などがあります。
-
Batch Job インスタンスは、Batch Job インスタンスが
<process-records/> に達した時点で実行されます。この時点で、Process フェーズが開始されます。すべてのレコード処理はこのフェーズ中に行われます。 -
各 Batch Step コンポーネントには、レコードに対してその中に含まれるデータを変換、転送、強化、または変更する 1 つ以上のプロセッサーが含まれます。たとえば、処理したレコードを 1 つずつ外部サーバーに渡すようにコネクタ操作を設定する場合があります。
-
Batch Aggregator コンポーネントは省略可能です。Batch Step コンポーネントに追加できるのは 1 つのみです。Batch Aggregator 内の最初のプロセッサーは入力としてレコードの配列を受け入れることができる必要があります。バッチ集計は処理したレコードの配列を外部サーバーに読み込む場合に便利です。他のプロセッサーでレコードを 1 つずつ処理できるように、For Each など、配列に対して反復処理を行うコンポーネントを使用することもできます。Batch Aggregator コンポーネントには、レコードの処理方法を示す
streaming または size 設定が必要です。 -
追加の Batch Step コンポーネントは省略可能です。この例には、Batch Aggregator コンポーネントは含まれません。
-
レコードがすべての Batch Step コンポーネントを通過したら、Mule で Batch Job インスタンスが完了され、処理中に成功したレコードと失敗したレコードを示す結果がオブジェクトで報告されます。
<batch:on-complete /> 内の Logger などのプロセッサーを使用して結果を取得または記録できます。Batch Job コンポーネントではレコードが On Complete フェーズでコンシュームされます。このフェーズは Batch Job インスタンスのすべてのレコード処理が完了した後に発生し、処理したレコードは Batch Job コンポーネントの外側の外部コンポーネントに伝播されません。ただし、多くの Mule コンポーネントと同じように、Batch Job コンポーネントにより、Batch Job の外側のダウンストリームコンポーネントで Batch Job コンポーネントが受け取る事前に処理されたペイロードにアクセスするために使用する対象変数 (
target) プロパティを設定できます。
詳細は、Batch Job のフェーズを参照してください。
Batch Job コンポーネントに対する有効な入力
フローのアップストリームイベントによって Batch Job コンポーネントがトリガーされると、Mule メッセージ入力に対する暗黙的な分割操作が実行されます。この操作では、Java イテラブル、イテレーター、配列のほか、JSON ペイロードと XML ペイロードを受け入れます。このコンポーネントでは他のデータ形式を分割できません。
分割プロセスとの互換性がないデータ形式を使用する場合は、Batch Job コンポーネントに入る前にペイロードをサポートされる形式に変換してください。
Mule 変数の伝播
Batch Job インスタンスの各レコードは、Batch Job コンポーネントへの入力から Mule イベント変数を継承します。これらの変数の値は Process フェーズ中に実行される Batch Step コンポーネントおよび Batch Aggregator コンポーネントでアクセスして変更でき、これらのコンポーネント内で新しい変数を作成できます。このフェーズ内の各レコードについて、変数 (およびこれらの変数に対する変更) は Batch Job コンポーネント内の各 Batch Step コンポーネントよび Aggregator コンポーネントを通じて伝播されます。たとえば、レコード R1 で Mule 変数 varName を "hello" に設定し、レコード R2 で varName を "world" に設定して、レコード R3 でこの変数を設定しない場合、次の Batch Step コンポーネント R1 には値 "hello" が表示され、R2 には値 "world" が表示されて、R3 はその変数について null を返します。
似たようなシナリオで、varName が Batch Job コンポーネントの前のフローで設定され、レコード 3 (R3) で varName の値が変更されない場合、R3 はその値を継承します。この点について説明するために、Mule フローが Batch Job コンポーネントに配列 [1,2,3,4] の payload および値が "my variable before batch job" の Mule 変数 varName を送信するとします。次の例では、Choice ルーター (choice) を使用して最初と 2 番目のレコードで varName の新しい値を設定していますが、3 番目のレコードでは設定していません。後続のレコードでも新しい varName 値を設定しています。
<flow name="batch-variables-ex" >
<scheduler doc:name="Scheduler" >
<scheduling-strategy >
<fixed-frequency frequency="45" timeUnit="SECONDS"/>
</scheduling-strategy>
</scheduler>
<!-- Set Payload -->
<set-payload value="#[[1,2,3,4]]" doc:name="Set Payload" />
<!-- Set Variable -->
<set-variable value='"my variable before batch job"' doc:name="Set Variable"
variableName="varName" />
<!-- Log Variable -->
<logger level="INFO" doc:name="Logger"
message="#[vars.varName]"
category="PRINT VARIABLE BEFORE BATCH" />
<!-- Batch Job -->
<batch:job jobName="batch-variables-exBatch_Job" >
<batch:process-records >
<!-- First Batch Step -->
<batch:step name="Batch_Step" >
<logger level="INFO" doc:name="Logger"
message="#[payload]"
category="PRINT RECORD NUMBER"/>
<choice doc:name="Choice" >
<!-- First record, R1 -->
<when expression="#[payload == 1]">
<set-variable value='"hello"' doc:name="Set Variable"
variableName="varName" />
<logger level="INFO" doc:name="Logger"
message="#[vars.varName]"
category="R1: PRINT VARIABLE for PAYLOAD is 1"/>
</when>
<!-- Second record, R2 -->
<when expression="#[payload == 2]">
<set-variable value='"world"' doc:name="Set Variable"
variableName="varName" />
<logger level="INFO" doc:name="Logger"
category="R2: PRINT VARIABLE for PAYLOAD is 2"
message="#[vars.varName]"/>
</when>
<!-- Third record, R3 -->
<when expression="#[payload == 3]">
<logger level="INFO" doc:name="Logger"
message="#[vars.varName]"
category="R3: PRINT VARIABLE for PAYLOAD is 3"/>
</when>
<!-- Other records -->
<otherwise>
<set-variable value='"some other value"' doc:name="Set Variable"
variableName="varName"/>
<logger level="INFO" doc:name="Logger"
category="Rn: PRINT DEFAULT VARIABLE" message="#[vars.varName]"/>
</otherwise>
</choice>
</batch:step>
<!-- Second Batch Step -->
<batch:step name="Batch_Step1" >
<logger level="INFO" doc:name="Logger"
message='#[("payload " ++ payload as String) : vars.varName]'
category="PRINT VARIABLES IN SECOND STEP"/>
</batch:step>
</batch:process-records>
</batch:job>
<!-- Log Variables After Batch Job -->
<logger level="INFO" doc:name="Logger"
message="#[vars.varName]"
category="PRINT VARIABLE VALUES AFTER BATCH JOB"/>
</flow>ログでは Batch Job インスタンスの次のメッセージが出力されます (読みやすいように編集済み)。
...
INFO ...PRINT VARIABLE BEFORE BATCH: "my variable before batch job"
...
INFO ...PRINT VARIABLE VALUES AFTER BATCH JOB: "my variable before batch job"
INFO ...PRINT RECORD NUMBER: 1
INFO ...R1: PRINT VARIABLE for PAYLOAD is 1: "hello"
INFO ...PRINT RECORD NUMBER: 2
INFO ...R2: PRINT VARIABLE for PAYLOAD is 2: "world"
INFO ...PRINT RECORD NUMBER: 3
INFO ...R3: PRINT VARIABLE for PAYLOAD is 3: "my variable before batch job"
INFO ...PRINT RECORD NUMBER: 4
INFO ...Rn: PRINT DEFAULT VARIABLE: "some other value"
...
INFO ...PRINT VARIABLES IN SECOND STEP: {payload 1="hello"}
INFO ...PRINT VARIABLES IN SECOND STEP: {payload 2="world"}
INFO ...PRINT VARIABLES IN SECOND STEP: {payload 3="my variable before batch job"}
INFO ...PRINT VARIABLES IN SECOND STEP: {payload 4="some other value"}
...3 番目のレコード (R3) が Batch Job コンポーネントの前で設定された varName の値を継承している点に注意してください。R3 より後のレコードでは変数を "some other value" に設定しています。2 番目の Batch Step に記録されたレコードは最初の Batch Step から変数の値を継承しています。Batch Job インスタンスが処理を完了する前に非同期で処理される Batch Job コンポーネントの後の Logger は、Batch Job が実行される前の varName の値である "my variable before batch job" も受け取ります。
Process フェーズ中に Mule 変数を変更または追加しても、On Complete フェーズには伝播されません。Batch Job コンポーネントへのトリガーイベントから継承された変数のみが On Complete フェーズに伝播され、batchJobInstanceId など、Batch Job レポートに含まれる標準変数はこのフェーズでも表示されます。On Complete フェーズでは、このフェーズの最後までは保持されるが On Complete が終了した後は保持されない変数を作成できます。
たとえば、On Complete フェーズで新しい変数 (myOnCompleteVar) を設定し、このフェーズで見つかったすべての変数 (vars) を記録するとします。
<batch:on-complete >
<set-variable value="Hello On Complete Variable" doc:name="Set Variable"
variableName="myOnCompleteVar"/>
<logger level="INFO" doc:name="Logger"
message="#[vars]"
category="PRINT ON COMPLETE VARIABLES"/>
</batch:on-complete>On Complete レポートには、たとえば次のように Batch Job インスタンスで最終的に設定される変数が表示されます。
INFO ... PRINT ON COMPLETE VARIABLES: {
varName=TypedValue[value: '"my variable before batch job"', dataType: 'SimpleDataType{type=java.lang.String, mimeType='*/*; charset=UTF-8'}'],
batchJobInstanceId=TypedValue[value: '869ae510-5c84-11ed-bc38-147ddaaf4f97', dataType: 'SimpleDataType{type=java.lang.String, mimeType='*/*'}'],
myOnCompleteVar=TypedValue[value: 'Hello On Complete Variable', dataType: 'SimpleDataType{type=java.lang.String, mimeType='*/*; charset=UTF-8'}']}
レポートオブジェクトの変数の例は以下に従います。
-
varName は Batch Job コンポーネントに達する前に作成された変数の例です。この変数には、コンポーネントに入ったときの値が保持されます。Process フェーズ中に値を変更しても、On Complete フェーズでは保持されません。 -
batchJobInstanceId は Batch Job インスタンスを識別する標準変数です。 -
myOnCompleteVar は On Complete フェーズ内で作成された変数の例です。レポートには表示されますが、On Complete フェーズの終了後は保持されません。
Batch Job コンポーネントからのダウンロードストリームでは、varName のみが保持されます。レコードやその属性と同じように、レコードの変数は Batch Job コンポーネント内で完全にコンシュームされます。Batch Job インスタンスはフローの残りの部分から非同期で実行されるため、Process フェーズまたは On Complete フェーズ内で作成された変数は Batch Job コンポーネント外で保持されません。
エラー処理
Batch Job 全体の失敗を防止するために、Batch Job コンポーネントではレコードレベルで発生する失敗を処理できます。また、バッチ処理中に Mule が変数に従って Batch Job インスタンス内のレコードの転送またはアクションを実行できるように、個々のレコードの変数を設定または削除できます。詳細は、「Batch Job 中のエラー処理」を参照してください。