CloudHub 高可用性機能
CloudHub 高可用性 (HA) 機能を使用すると、CloudHub のアプリケーションで拡張性、ワークロードの分散、信頼性の向上を実現できます。この機能は、CloudHub の拡張性の高い負荷分散サービス、ワーカーのスケールアウト、永続的なキュー配置機能によって提供されます。
新しいアプリケーションをデプロイするときや、既存のアプリケーションを再デプロイするときに Anypoint Runtime Manager コンソールを使用して、アプリケーションごとに HA 機能を有効にできます。
前提条件
CloudHub HA では、以下が必要です。
-
この機能を使用できるようにする CloudHub Enterprise または Partner アカウント種別。
-
Runtime Manager コンソールを使用したアプリケーションのデプロイについての理解。
ワーカーのスケールアウト
CloudHub では、アプリケーションのワーカーの容量とサイズを選択して、水平拡方向に拡張できます。このように計算能力のプロビジョニングを詳細に制御できるため、高い負荷に対処する場合はアプリケーションをスケールアップし、負荷が低い期間はスケールダウンするという作業を任意のタイミングで柔軟に行うことができます。
[workers (ワーカー)] の横にあるドロップダウンメニューを使用して、アプリケーションのワーカーの数とサイズを選択し、必要な計算能力を設定します。
サブスクリプションに応じて、任意の種類の最大 8 個のワーカー、アプリケーションごとに最大 128 個の vCore でアプリケーションをデプロイできます。 十分なリソースがあることを確認するには、「CloudHub ワーカー」を参照してください。
ワーカーのスケールアウトにより、信頼性も向上します。Mule Runtime Engine (Mule) は、自動的に同じアプリケーションで複数のワーカーを 2 つ以上のデータセンターで分散し、最大限の信頼性を確保します。
アプリケーションを 2 つ以上のワーカーにデプロイすると、それらの Mule インスタンスでワークロードを分散できます。CloudHub では、以下が提供されます。
-
HTTP 負荷分散サービス。割り当てたワーカーで HTTP 要求を自動的に分散します。
-
永続的なメッセージキュー (下記参照)
バッチジョブは、一度に 1 つのワーカーでのみ実行され、複数のワーカーで分散できません。 同じデプロイメントで Mule が再起動すると、その状況は保持され、バッチの処理が続行されます。バッチの実行中にアプリケーション全体が更新または再デプロイされると、残りのバッチジョブは続行されません。CloudHub の永続的なバッチジョブの主な解決策は、クラウドオブジェクトストアを使用することです。
永続的なキュー
永続的なキューにより、メッセージの損失がなくなり、ワークロードを一連のワーカーで分散できます。
-
アプリケーションを複数のワーカーにデプロイする場合、永続的なキューを使用すると、ワーカー間の通信とワークロードの分散を実現できます。たとえば、大きなファイルがキューに配置された場合、ワーカーはこれを分割して並列で処理できます。
-
永続的なキューでは、大きな利害が関係する処理のメッセージセキュリティが追加されており、1 つ以上のワーカーまたはデータセンターがダウンしても、メッセージが確実に配信されます。
-
アプリケーションで永続的なキューが有効になっていると、実行時に Runtime Manager コンソールの [Queues (キュー)] タブでキューを表示できます。
-
すべての永続的なキューで保存時のデータの暗号化を有効にできます。この機能を有効にすると、永続的なキューに書き込まれる共有アプリケーションデータが暗号化され、セキュリティとコンプライアンスのニーズを満たすことができます。
-
永続的なキューのメッセージの保持期間は最大 4 日です。永続的なキューのメッセージのサイズや数に制限はありません。
-
ワーカーの永続的なキューは、ワーカーと同じリージョンにあります。
永続的なキューでは 1 回のみのメッセージ配信は保証されません。重複するメッセージが送信される場合もあります。1 回のみのメッセージ配信が重要なユースケースの場合、永続的なキューを有効にしないでください。
アプリケーションでの永続的なキューの動作についての詳細は、「キューの管理」を参照してください。
CloudHub HA 機能の有効化
次の 2 つのいずれかの方法で CloudHub HA の機能のいずれかまたは両方を有効/無効にできます。
-
初めてアプリケーションを CloudHub にデプロイするときに Runtime Manager コンソールを使用する
-
以前にデプロイされたアプリケーションの Runtime Manager コンソールで [Deployment (デプロイメント)] タブにアクセスする
-
[Workers (ワーカー)] の横で、ドロップダウンメニューからオプションを選択し、アプリケーションに割り当てられているワーカーの数と種別を定義します。
-
複数のワーカーへのデプロイについての詳細は、「CloudHub ワーカー」を参照してください。
アプリケーションをクリックして概要を表示し、[Manage Application (アプリケーションを管理)] をクリックします。[Settings (設定)] をクリックして [Persistent Queues (永続的なキュー)] チェックボックスをオンにし、キューの永続性を有効にします。
アプリケーションがすでにデプロイされている場合、新しい設定を有効にするには、再デプロイする必要があります。
HA の実装方法
HTTP 負荷分散は、内部リバースプロキシサーバーで実装されます。アプリケーション (ドメイン) URL http://appname.cloudhub.io への要求は、自動的にすべてのアプリケーションのワーカー URL で負荷分散されます。
クライアントは、ワーカーの直接 URL を使用してアプリケーションのロードバランサーをバイパスできます。特定の CloudHub ワーカーでアプリケーションにアクセスする方法についての詳細は、「CloudHub ネットワークガイド」を参照してください。
ユースケース
単一のアプリケーションでは、HA 機能のどちらか片方または両方を使用する、あるいはどちらも使用しないように選択できます。
-
永続的なキューを利用するには、この機能をサポートするように Mule アプリケーションを設定します。詳細については、「永続的なキューをサポートする Mule アプリケーションの構築」を参照してください。
-
永続的なキューを有効にすると、パフォーマンスに影響があります。小さなメッセージ (50KB 以下) をキューに配置する場合は 10 ~ 20 ミリ秒 (ms) かかりますが、同じメッセージをキューから取り出す場合は 70 ~ 100 ミリ秒かかります。
-
ワーカーを追加すると、サービスのコストが増加します。
| ユースケース | 推奨される HA 設定 | 影響 |
|---|---|---|
アプリケーションをスケールアウトしたいが、サービスの中断とメッセージの損失については、既存の可用性の高い CloudHub アーキテクチャに満足している。 |
永続的なキューを有効にしない。 ワーカーの数: 2 つ以上 |
|
メッセージの損失に対する保護が必要な大きな利害が関係するプロセスがあるが、処理負荷の対処に問題は発生しておらず、データセンターが停止した場合に一部のサービスが中断されても問題はない。 |
永続的なキューを有効にする。 ワーカーの数: 1 |
|
メッセージの損失に対する保護が必要な大きな利害が関係するプロセスがあり、サービスの中断を避けて、大きな処理負荷に対処する。 |
永続的なキューを有効にする。 ワーカーの数: 2 つ以上 |
|
処理負荷やメッセージの損失に関して特殊な要件のないアプリケーションがある。 |
永続的なキューを有効にしない。 ワーカーの数: 1 |
|
バッチジョブが含まれるアプリケーションの永続的なキュー
バッチジョブが含まれるアプリケーションを永続的なキューが有効になっている CloudHub にデプロイする場合、バッチジョブは CloudHub の永続的なキューを使用して、バッチキュー機能を実現します。
永続的なキューを有効にする場合、次の制限事項に留意してください。
-
CloudHub の永続的なキューを使用すると、バッチジョブのレイテンシーが増加します。
パフォーマンスを向上させるには、永続的なキューを無効にしてください。
-
CloudHub の永続的なキューは、複数回メッセージを処理することがあります。
メッセージが 1 回だけ処理されるようにするには、永続的なキューを無効にしてください。
-
アプリケーションが再起動されると、メッセージの損失が起こる場合があります。
これらの制限事項を踏まえて、Mulesoft ではバッチジョブについては永続的なキューを無効にすることをお勧めします。
バッチジョブの永続的なキューを無効にするには、次のプロパティをアプリケーションに追加します。
batch.persistent.queue.disable=trueデフォルトでは、このプロパティの値は false です。
true に設定すると、アプリケーションではバッチジョブに永続的なキューが使用されませんが、他の Mule コンポーネントについては永続的なキューが有効なままになります。
永続的なキューをサポートする Mule アプリケーションの構築
アプリケーションで永続的なキューの利点を得るには、信頼性パターンをアプリケーションコードに実装して、個々の XA トランザクションを VM トランスポートから分離します。詳細は、「信頼性パターン」を参照してください。
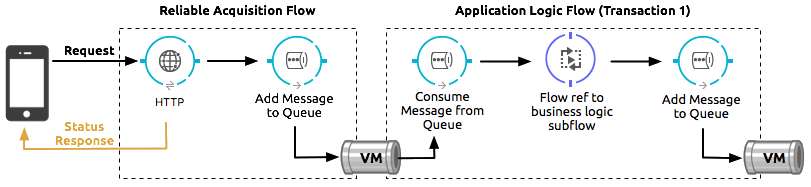
信頼性の高い取得フローでは、インバウンド HTTP Connector からアウトバウンド VM エンドポイントにメッセージが確実に配信されます。信頼性の高い取得フローでメッセージを VM キューに配置できない場合、クライアントが要求を再試行できるように「要求失敗」応答をクライアントに返して、メッセージの損失を回避します。
アプリケーションロジックフローでは、インバウンド VM エンドポイントからアプリケーションのビジネスロジック処理にメッセージが配信されます。このフローは、1 つのトランザクションを表します。各自のビジネスロジックには、表示されていない他のトランザクションがいくつか含まれる可能性があります。
信頼性の高い取得フローでコミットされたメッセージは、アプリケーションロジックフローで処理する準備が整うまで、これらの 2 つのフローの間にある永続的な VM キューで保持されます。トランザクション内で処理エラーが発生した場合や、トランザクションがタイムアウト (トランザクションに割り当てられている時間を超過) した場合、Mule はロールバックをトリガーします。このロールバックにより、メッセージで行われた部分的な処理が消去され、メッセージがキューに戻ります。Mule インスタンスが停止した場合や、トランザクションを明示的にロールバックできない場合、トランザクションに割り当てられている時間を超えると、トランザクションが自動的にロールバックします。割り当て時間は、トランザクション要素の timeout 属性によって決まります。自分でタイムアウトを設定することも、デフォルトを受け入れることもできます。
3 つのステップで各トランザクションを考えるとわかりやすくなります。
-
開始。Mule は、トランザクション内のすべてのサブコンポーネントの処理を開始します。
-
コミット。Mule は、完了したトランザクションの結果を次のステップに送信します。XA トランザクションの場合、コミットステップは、コミット要求フェーズとコミットフェーズの 2 つのフェーズになります。コミット要求フェーズでは、Mule はトランザクションのスコープ内の複数の応答の結果を調整し、すべての処理が正常に実行されて、コミットの準備が整っていることを確認します。その後、コミットフェーズで各リソースがコールされ、その処理がコミットされます。
-
ロールバック。「開始」または「コミット」ステップのいずれかでエラーが発生した場合、Mule は部分的な完了がないようにトランザクション内の処理をロールバックします。
次のコードスニペットは、CloudHub でキューの永続性を確保するために VM トランスポートを使用する信頼性パターンでセットアップされたアプリケーションの例です。
<mule xmlns:vm="http://www.mulesoft.org/schema/mule/vm" xmlns:http="http://www.mulesoft.org/schema/mule/http" xmlns="http://www.mulesoft.org/schema/mule/core" xmlns:doc="http://www.mulesoft.org/schema/mule/documentation" xmlns:spring="http://www.springframework.org/schema/beans" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans-current.xsd
http://www.mulesoft.org/schema/mule/core http://www.mulesoft.org/schema/mule/core/current/mule.xsd
http://www.mulesoft.org/schema/mule/http http://www.mulesoft.org/schema/mule/http/current/mule-http.xsd
http://www.mulesoft.org/schema/mule/vm http://www.mulesoft.org/schema/mule/vm/current/mule-vm.xsd
http://www.mulesoft.org/schema/mule/jbossts http://www.mulesoft.org/schema/mule/jbossts/current/mule-jbossts.xsd">
<vm:connector name="vmConnector" doc:name="VM">
</vm:connector>
<http:listener-config name="listener-config" host="..." port="..."/>
<!-- This is the reliable acquisition flow in the reliability pattern. -->
<flow name="reliable-data-acquisition" doc:name="reliable-data-acquisition">
<http:listener config-ref="listener-config" path="/" doc:name="HTTP Connector"/>
<expression-filter expression="#[message.inboundProperties.'http.request.path' != '/favicon.ico']" nullReturnsTrue="true" doc:name="Expression"/>
<vm:outbound-endpoint exchange-pattern="one-way" path="input" connector-ref="vmConnector" doc:name="VM"/>
</flow>
<!-- This is the application logic flow in the reliability pattern.
It is a wrapper around a subflow, "business-logic-processing".
-->
<flow name="main-flow" doc:name="main-flow">
<vm:inbound-endpoint exchange-pattern="one-way" path="input" connector-ref="vmConnector" doc:name="VM">
<xa-transaction action="ALWAYS_BEGIN" timeout="30000"/>
</vm:inbound-endpoint>
<flow-ref name="business-logic-processing" doc:name="Flow Reference"/>
<vm:outbound-endpoint exchange-pattern="one-way" path="output" connector-ref="vmConnector" doc:name="VM">
</flow>
<!--
This subflow is where the actual business logic is performed.
-->
<sub-flow name="business-logic-processing" doc:name="business-logic-processing">
....
</sub-flow>
</mule>ハイブリッド VM キューと CloudHub VM キューの違い
次の表に、ハイブリッド VM キューと CloudHub VM キューの主な違いを示します。
| オンプレミスアプリケーションの VM キュー | CloudHub にデプロイされているアプリケーションの VM キュー |
|---|---|
queue-profile 要素を使用して、未処理メッセージの最大数を設定できます。 |
CloudHub では、未処理メッセージの数に制限はありません。アプリケーションで未処理メッセージの最大数を使用して queue-profile 要素をコーディングしていても、[Persistent Queues (永続的なキュー)] チェックボックスをオンにしてアプリケーションを CloudHub にデプロイすると、未処理メッセージは無制限になります。 |
queue-profile 要素を使用して、キューの永続性を切り替えることができます。 |
キューの永続性は、[deployment (デプロイメント)] ダイアログの [Advanced Details (高度な詳細)] セクションにある [Persistent Queues (永続的なキュー)] チェックボックスを使用して管理します。アプリケーションで queue-profile 要素をコーディングしていても、[Persistent Queues (永続的なキュー)] チェックボックスをオンにしてアプリケーションを CloudHub にデプロイすると、これらの設定は上書きされます。 |
使用する VM キューのキューストアを定義できます。 |
キューストアは CloudHub で管理されるため、キューストアを定義する必要はありません。 |
XA トランザクションのコミットとロールバックは、2 フェーズコミットアルゴリズムに従って処理されます。 |
CloudHub でメッセージをキューに追加する場合、XA トランザクションの 2 フェーズコミットアルゴリズムの動作に重要な例外があります。詳細は、以下の既知の問題を参照してください。注意: CloudHub で永続的なキューのメッセージをコンシュームする場合、この 2 フェーズコミットアルゴリズムの例外は適用されません。 |
考慮事項
CloudHub でメッセージを VM キューに追加する場合、次の条件を満たすと、XA トランザクションの 2 フェーズコミットプロトコルが失敗し、完了したトランザクションがロールバックされる可能性があります。
-
コミット要求フェーズが正常に完了した。トランザクション内の関連するすべての処理が正常に実行されるため、メッセージをキューにコミットできるようになります。
-
コミットフェーズでエラーが発生し、トランザクション内のサブプロセスをコミットできなくなり、トランザクションのロールバックがトリガーされる。
-
ロールバックが発生する前に VM アウトバウンドエンドポイントでコミットが完了する。
上記の 3 つの条件をすべて満たす場合、メッセージは意図したとおりトランザクションロールバックプロセスでロールバックされる代わりにキューに追加されます。メッセージの損失は発生せず、トランザクションを引き続き繰り返すことができますが、アウトバウンド VM キューに意図しないメッセージが追加されます。
| この問題は、VM キューに追加する必要のあるメッセージがフローで生成される場合にのみ発生します。キューのメッセージをコンシュームするプロセスには影響はありません。 |