Batch Job のフェーズ
Batch Job コンポーネントが実行されるたびに、次のフェーズが行われます。
-
Load and Dispatch フェーズ: Batch Job コンポーネントにより有効な入力がレコードに分割され、レコードを処理する準備が整えられます。このフェーズは Batch Job コンポーネント内で行われます。
-
Process フェーズ: Batch Job の 1 つ以上の Batch Step コンポーネント内の Mule コンポーネントおよびコネクタの操作により、特定の Batch Job インスタンス内のレコードが処理されます。Batch Aggregator コンポーネント内での処理も Process フェーズで行われます。
-
On Complete フェーズ: Batch Job コンポーネントにより、Batch Job インスタンスの処理の結果が含まれるレポートオブジェクトが発行されます。
例については、バッチフェーズの XML を参照してください。
Load and Dispatch フェーズ
フローのアップストリームイベントによって Batch Job コンポーネントがトリガーされると、Load and Dispatch フェーズが開始されます。このフェーズでは、以下が行われます。
-
Mule によって、Batch Job の各フェーズで保持される新しい Batch Job インスタンスが作成されます。
Batch Job コンポーネントのスコープ内で、
batchJobInstanceId 変数を使用して現在処理中の Batch Job インスタンス ID が Mule によって公開されます。vars.batchJobInstanceId を使用して、任意のバッチ処理フェーズで現在のインスタンスの識別子にアクセスできます。自動生成される識別子は UUID ですが、別の値に変更できます。詳細は、Batch Job インスタンス IDを参照してください。 -
Batch Job コンポーネントにより、受信されたメッセージペイロードが自動的にレコードに分割され、ステッピングキューにレコードが格納されます。
Batch Job コンポーネントによって入力のすべての項目のレコードが正常に生成され、キューに追加されるか、
MULE:EXPRESSION メッセージなどのエラータイプと "Expecting Array or Object but got String." evaluating expression: "payload" などのエラーメッセージでイベント全体が失敗します。Anypoint Runtime Manager では、たとえば次のようにキュー名に
BSQ というプレフィックスが付けられます。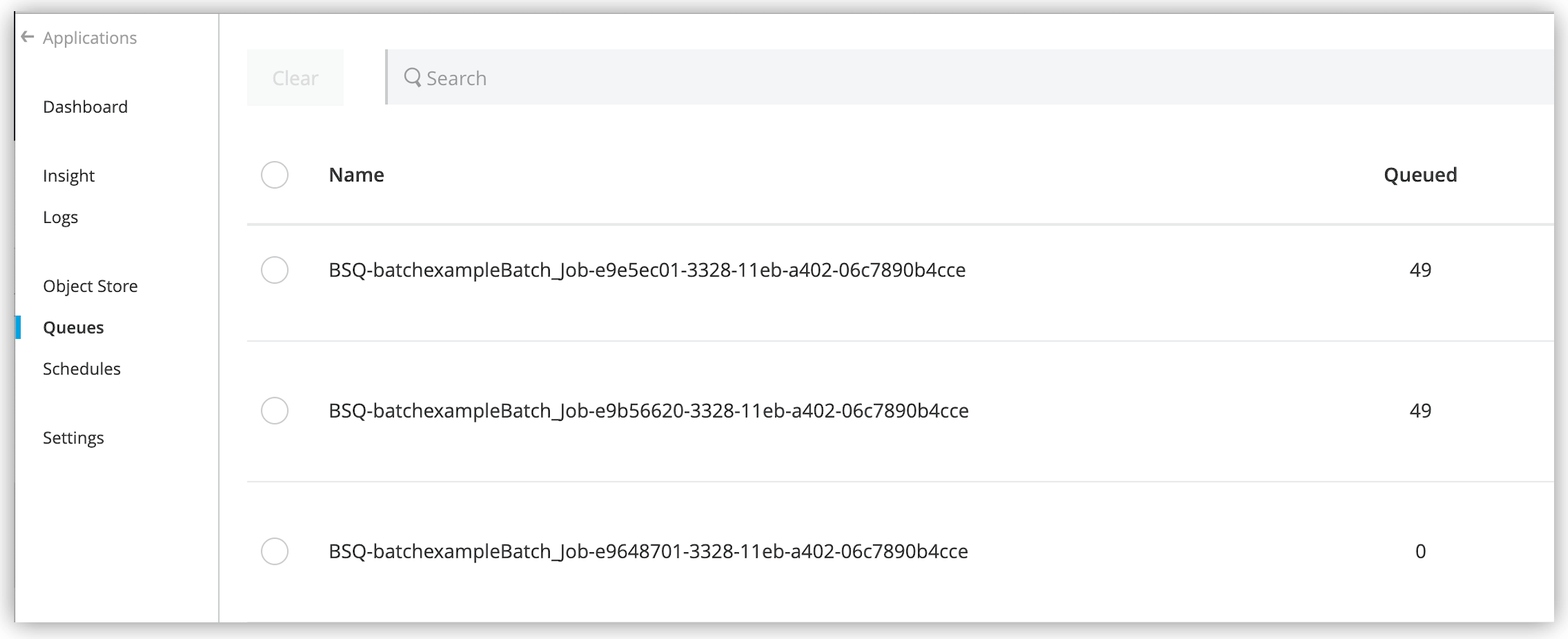
-
Batch Job コンポーネントにより、読み込まれたレコードを処理する Batch Job インスタンスの実行が開始されます。
Process フェーズ
Process フェーズは、Load and Dispatch でキューへのレコードの読み込みを完了し、Batch Job インスタンスの処理を開始した後に開始されます。このフェーズでは、Batch Step コンポーネントによって設定済みのサイズのレコードブロックがキューから抽出され、処理されます。(デフォルトのバッチブロックサイズは 100 です)。
Batch Step コンポーネント内での処理はブロックレベルで並列に行われますが、各ブロック内のレコードはデフォルトで順次処理されます。Mule では、自動調整機能によって、使用するスレッド数と適用する並列性レベルが決定されます (「実行エンジン」を参照)。
このフェーズ中、コンポーネント内のプロセッサーは payload および vars Mule 変数を使用してレコードにアクセスし、変更を行います。Batch Job ではすべてのレコードの処理が完了した後でレコードがコンシュームされます。そのため、処理済みレコードを外部サーバーまたはサービスに転送する場合は、Batch Step または Batch Aggregator コンポーネント内で転送する必要があります。Mule 変数の伝播ルールについては、「変数の伝播」を参照してください。
Batch Step ではブロック内のレコードを処理した後に、レコードをステッピングキューに送信します。ステッピングキューでは、レコードは次の Batch Step を待機します。すべてのレコードが同じ Batch Job コンポーネント内のすべての Batch Step を通過するまで、このプロセスが続行されます。このフェーズの最後の時点で、すべてのレコードがコンシュームされます。Mule フローのダウンストリームプロセッサーによる追加の処理には使用できません。
Batch Aggregator コンポーネント内で行われるレコードに対する変更は Batch Aggregator コンポーネント外に伝播されないため、変更内容はフローの後続の Batch Step コンポーネントでは表示されませんのでご注意ください。
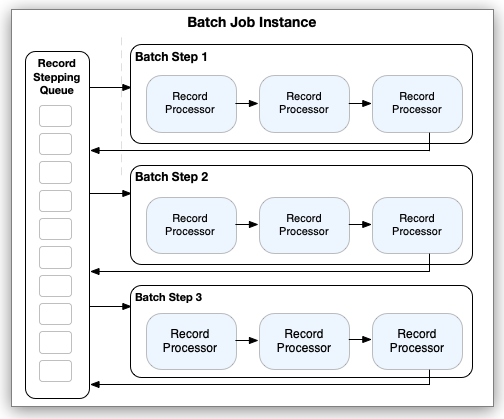
処理が行われるときに、各レコードはすべての Batch Step コンポーネントでの処理を監視します。
デフォルトでは、Batch Job インスタンスは、キューに追加されたすべてのレコードが 1 つの Batch Step コンポーネントでの処理を終了するのを待たずに、レコードを次の Batch Step で処理できるようにします。Batch Aggregator コンポーネントを設定するとこの動作が変更されます。
-
Batch Aggregator コンポーネントが固定サイズを設定するときの動作:
Batch Aggregator 内のプロセッサーは入力としてレコードの配列を受け取れる必要があります。
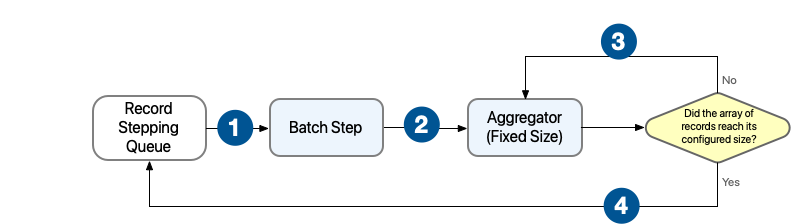
1 Batch Job コンポーネント内の各 Batch Step によって 1 つ以上のレコードブロックが受け取られ、並列での処理が開始されます。 2 Batch Step コンポーネントはレコードを処理した後で、さらに処理するためにレコードを Batch Aggregator コンポーネントに送信します。 3 固定サイズ ( size) を処理するよう設定した場合、Aggregator コンポーネントによってレコードが指定した数のレコードが含まれる 1 つ以上のブロックに配置されます。レコードが設定したサイズより少ない場合、最後のレコードのブロックが小さくなります。4 特定の配列でレコードを処理した後で、Batch Aggregator コンポーネントではすべてのレコードブロックがステッピングキューに送信されます。 -
Batch Aggregator コンポーネントがレコードをストリーミングするよう設定されているときの動作:
ストリーミング時には、Batch Aggregator コンポーネントではレコードをレコードブロックに配置するのではなく、受け取った直後にレコードを処理します。アグリゲーターのすべてのレコードで現在の Batch Step のすべてのレコードが処理されるまで、レコードは次の Batch Step コンポーネントに公開されません。
コンポーネント内のプロセッサーは入力としてレコードの配列を受け入れることができる必要があります。
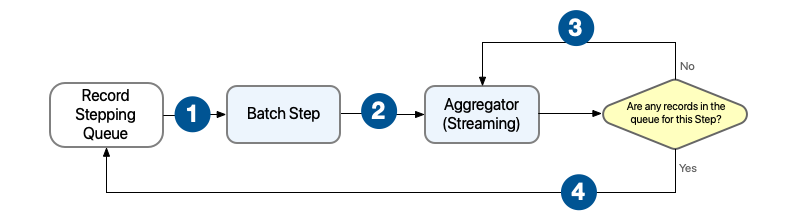
1 各 Batch Step コンポーネントで 1 つ以上のレコードブロックを受け取り、レコードブロックの並列処理を開始します。 2 Batch Step でレコードを処理したら、レコードを Batch Aggregator に送信してさらに処理を行います。 3 Batch Aggregator コンポーネントでは、現在の Batch Step による処理を待機している、ステッピングキュー内のレコードがなくなるまでレコードの処理を継続します。 4 Batch Aggregator コンポーネントでは集約したすべてのレコードがステッピングキューに送信されます。
Mule では、各 Batch Step での処理に成功または失敗したすべてのレコードのリストを保持しています。Batch Step のイベントプロセッサーでレコードの処理に失敗した場合、Mule はバッチの処理を続行し、後続の各 Batch Step では acceptPolicy に基づいて失敗したレコードをスキップします。Batch Job コンポーネントには、Batch Job が停止する前に失敗できるレコードの数を設定するための maxFailedRecords プロパティが用意されています。「Batch Job のプロパティ」を参照してください。
On Complete フェーズ
このフェーズ中、特定の Batch Job インスタンスで処理したレコードのレポートまたは概要を作成するように Mule Runtime を設定できます。このフェーズでは、システム管理者および開発者に、どのレコードが処理に失敗し、どのレコードが正常に処理されたかに関するインサイトが提供されますが、各レコードの処理が行われたり各レコードへのアクセスが提供されたりすることはなく、処理されたレコードがフローのダウンストリームプロセッサーに渡されたりすることもありません。
このフェーズの終了時に Batch Job インスタンスは完了し、消滅します。
ベストプラクティスとしては、失敗または成功したレコードについて報告するための何らかのメカニズムを設定し、必要な場合は追加アクションの実行を促してください。On Complete フェーズ中に、次のいずれかのタスクを実行できます。
-
Mule アプリケーションの他の場所にある Batch Job の結果オブジェクトを参照し、特定の Batch Job インスタンスで処理に失敗したレコード数などの Batch Job メタデータを取得および使用する。
-
各 Batch Job インスタンスの結果オブジェクトを記録する。
<batch:job name="Batch3">
<batch:process-records>
<batch:step name="Step1">
<batch:record-variable-transformer/>
<ee:transform/>
</batch:step>
<batch:step name="Step2">
<logger/>
<http:request/>
</batch:step>
</batch:process-records>
<batch:on-complete>
<logger level="INFO" doc:name="Logger"
message='#[payload as Object]'/>
</batch:on-complete>
</batch:job>ロガーから payload as Object に設定すると、レポートは次のようになります。
INFO 2022-07-06 11:39:02,921 [[MuleRuntime].uber.06:
[w-batch-take6].batch-management-work-manager @56978b97]
[processor: w-batch-take6Flow/processors/3/route/1/processors/0;
event: e835b2c0-fd5a-11ec-84a5-147ddaaf4f97]
org.mule.runtime.core.internal.processor.LoggerMessageProcessor:
{onCompletePhaseException=null, loadingPhaseException=null, totalRecords=1000,
elapsedTimeInMillis=117, failedOnCompletePhase=false, failedRecords=0,
loadedRecords=1000, failedOnInputPhase=false, successfulRecords=1000,
inputPhaseException=null, processedRecords=10, failedOnLoadingPhase=false,
batchJobInstanceId=e84b5da0-fd5a-11ec-84a5-147ddaaf4f97}
インスタンス内で失敗したレコードの数を返す payload.failedRecords のように、Batch Job レポートオブジェクトの項目は DataWeave セレクターを使用するときのキーとしてアクセスできます。
On Complete フェーズを空のままにすると、Batch Job インスタンスは警告なしに完了し、たとえば次のように、インスタンスに関する処理情報がログで提供されます。
Finished execution for instance 'e84b5da0-fd5a-11ec-84a5-147ddaaf4f97' of job 'w-batch-take6Batch_Job'. Total Records processed: 1000. Successful records: 1000. Failed Records: 0