バッチコンポーネントリファレンス
Mule バッチコンポーネントでは、デフォルトのコンポーネント設定に対する調整を最小限に抑えてレコードのバッチ処理を管理します。コンポーネントは、処理およびパフォーマンスに関する特定の要件に合わせて高度に設定可能です。
Batch Job コンポーネントには 1 つ以上の Batch Step コンポーネントが含まれている必要があります。必要に応じて、各 Batch Step コンポーネントには 1 つの Batch Aggregator コンポーネントを含めることができます。次の図の Mule フローはバッチコンポーネントを示しています。
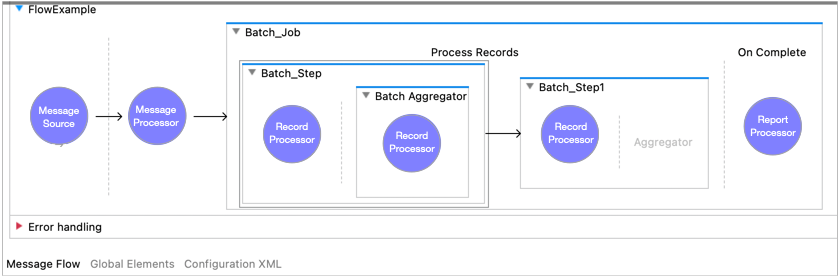
Batch Job コンポーネントでは Mule メッセージのペイロードをレコードに分割します。Batch Step コンポーネントおよび Batch Aggregator コンポーネント内で、これらのレコードはキーワード payload で使用でき、Mule 変数は vars キーワードを使用してアクセスすることもできます。ただし、Mule 属性はこれらのコンポーネント内からアクセスできません。どちらのコンポーネントも attributes で null を返します。
このリファレンスでは、読者が Batch Job インスタンスのバッチ処理フェーズに精通していることを前提としています。
Batch Job コンポーネント (<batch:job />)
このコンポーネントでは、処理用の入力を準備し、その処理の結果が記載されたレポートを出力します。準備は Batch Job インスタンスの Load and Dispatch フェーズ中に行われ、レポートは On Complete フェーズで使用できます。
Studio では、これらのプロパティをコンポーネントの [General (一般)] タブと [History (履歴)] タブで設定できます。
Batch Job のプロパティ
Batch Job コンポーネントには、バッチ処理の実行方法を決定する設定可能な多数のプロパティが用意されています。また、入力ペイロードをフローの後続のコンポーネントで使用できるように対象変数に格納することもできます。Batch Job コンポーネントはメッセージペイロードをコンシュームするため、これは便利な可能性があります。
Anypoint Studio の [General (一般)] タブには次の項目があります。
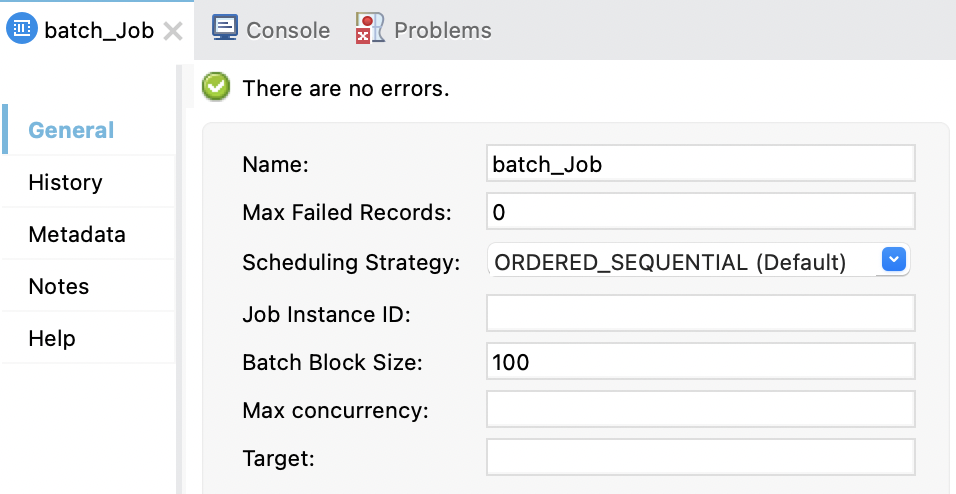
次の表に、各項目と項目の XML 属性を示します。
| 項目名 | XML | 説明 |
|---|---|---|
名前 |
|
Batch Job コンポーネントの設定可能な名前。デフォルトの名前はアプリケーションの名前に |
Max Failed Records (最大失敗レコード数) |
|
Batch Job インスタンスの実行が停止する前にその Batch Job インスタンス内で失敗できるレコードの最大数。デフォルトは INFO ... DefaultBatchEngine: instance '6d85c380-f332-11ec-bb5f-147ddaaf4f97' of job 'Batch_Job_in_Mule_Flow' has reached the max allowed number of failed records. Record will be added to failed list and the instance will be removed from execution pool. ... INFO ... DefaultBatchEngine: instance 6d85c380-f332-11ec-bb5f-147ddaaf4f97 of job Batch_Job_in_Mule_Flow has been stopped. Instance status is FAILED_PROCESS_RECORDS Batch Job インスタンス内の並列処理により、複数のレコードで同時に失敗できるようになるため、エラー数が設定した最大値を超えることができます。 |
Scheduling Strategy (スケジュール戦略) |
|
Batch Job コンポーネントが繰り返しトリガーする場合、複数の Batch Job インスタンスを同時に実行するように準備できます。インスタンスは作成タイムスタンプに基づいて (デフォルト)、または使用可能なリソースの使用を最大化しようとするラウンドロビンアルゴリズムに従って順次実行できます。この設定は、処理順序が保証されないため、他のレコードに対する副作用や連動関係がないジョブのみに適しています。
|
Job Instance ID (ジョブインスタンス ID) |
|
バッチインスタンスの認識可能な一意の名前を提供する省略可能な式。名前を一意にするには、この項目内でたとえば |
Batch Block Size (バッチブロックサイズ) |
|
レコードブロックあたりの処理するレコードの件数。デフォルトはブロックあたり |
Max Concurrency (最大同時実行) |
|
コンポーネント内でレコードブロックを処理するときに許可する並列性の最大レベルを設定するプロパティ。デフォルトは CPU で使用可能なコア数の 2 倍です。Mule インスタンスを実行しているシステムの容量によっても、同時実行が制限されます。 |
変換先 |
|
Batch Job コンポーネントの後に配置されたコンポーネントの Batch Job インスタンスで受け取られたペイロードを使用するには、 |
Batch Job 履歴 (<batch:history />)
Batch Job 履歴設定により、Batch Job インスタンスの履歴データが一時的な Mule ディレクトリで保持される期間を調整することにより、No space left on device エラーを解決できます。このエラーは、空きディスクスペース、または指定したサイズの CloudHub ワーカーに対して処理するレコードの頻度が高すぎるか数が多すぎて処理できない場合に発生する可能性があります。
デフォルトでは、Batch Job インスタンスの履歴は 7 日間保持されます。この期間が経過すると、監視プロセスによりその履歴が自動的に削除されます。
![Anypoint Studio の Batch Job の [History (履歴)] 項目](_images/batch-job-fields-history-studio.png)
次の表に、各項目と項目の XML 属性を示します。
| 名前 | XML | 説明 |
|---|---|---|
Max Age (最長有効期間) |
|
ジョブインスタンスが期限切れになる前の最長有効期間。例: |
Time Unit (時間単位) |
|
|
これらの項目は、<batch:history/> 内に埋め込まれる <batch:expiration/> 要素に対する属性です。
<batch:job ...>
<batch:history >
<batch:expiration maxAge="10" ageUnit="MINUTES" />
</batch:history>
<batch:process-records>
<batch:step />
</batch:process-records>
<batch:job />XML の例は、バッチ履歴項目の設定に焦点を絞るために編集されています。
Batch Step コンポーネント (<batch:step/>)
Batch Step コンポーネントは、Load and Dispatch フェーズや On Complete フェーズ中ではなく、Batch Job インスタンスの Process フェーズ中に実行されます。
Batch Job コンポーネント内には 1 つ以上の Batch Step コンポーネントが必要です。Batch Step コンポーネントの名前を変更するだけでなく、コンポーネントがコンポーネント内の処理に受け入れるレコードを決定する検索条件を設定できます。コンポーネントに追加したプロセッサーは、Batch Job コンポーネントが受け入れるレコードに対するアクションを実行します。
![Anypoint Studio の Batch Job の [General (一般)] 項目](_images/batch-step-fields-studio.png)
次の表に、各項目と項目の XML 属性を示します。
| 項目名 | XML | 説明 |
|---|---|---|
名前 |
|
Batch Step コンポーネントの設定可能な名前。Batch Job コンポーネント内の最初の Batch Step コンポーネントでは、デフォルトは |
Accept Expression (受け入れ式) |
|
コンポーネントでレコードを処理するかどうかを決定する検索条件の省略可能な DataWeave 式。レコードの
|
Accept Policy (受け入れポリシー) |
|
ポリシーがそのレコードで
|
Batch Aggregator コンポーネント (<batch:aggregator />)
Batch Aggregator コンポーネントはレコードの配列に対してアクションを実行する省略可能なコンポーネントです。集計は Batch Job インスタンスの Process フェーズ中に行われます。
Batch Aggregator コンポーネントにはデフォルトの設定はありません。このコンポーネントを使用する場合は、レコードをストリーミングするか (streaming)、キューから固定サイズ (size) の別の配列にレコードを取り込むか、どちらも行わないかを指定する必要があります。これらの設定は相互に排他的です。ストリーミングされたレコードへのランダムアクセスはできません。
Batch Aggregator コンポーネントではメッセージ payload として 1 つ以上のプロセッサーを受け入れます。ただし、For Each スコープなど、アグリゲーター内のスコープを使用して各レコードに対して反復し、スコープ内の子プロセッサーが個別に各レコードに対するアクションを実行できるようにするのが一般的です。
Batch Aggregator コンポーネントにより、固定サイズ (size) として集計しているレコードの一部にアクセスする場合に必要な MIME タイプのレコード (preserveMimeTypes) を保持することもできます。「集約されたレコードの MIME タイプの保持」を参照してください。このコンポーネント内のレコード処理についての詳細は、「Process フェーズ」のバッチ集計に関する情報を参照してください。
Salesforce 用 Anypoint Connector (Salesforce Connector) や NetSuite 用 Anypoint Connector (NetSuite Connector) などの一部のコネクタには、バッチ集計プロセスを失敗させることなくレコードレベルのエラーを処理できる操作が用意されています。
Batch Aggregator を使用するときは、次の制限事項を考慮してください。
-
Batch Aggregator コンポーネントを使用するときには、
ImmutableMap などの Guava データ型を処理しようとしないでください。代わりに、Java Map を使用してシリアル化の問題を回避します。 -
Batch Aggregator コンポーネントでは、ジョブインスタンス全体のトランザクションがサポートされません。Batch Step コンポーネント内で、各レコードを個別のトランザクションで処理するトランザクションを定義できます。ただし、Batch Step コンポーネントによって開始されたトランザクションは、Batch Aggregator コンポーネントが処理を開始する前に終了します。トランザクションはコンポーネント間の境界を越えることができないため、コンポーネントはトランザクションを共有できます。
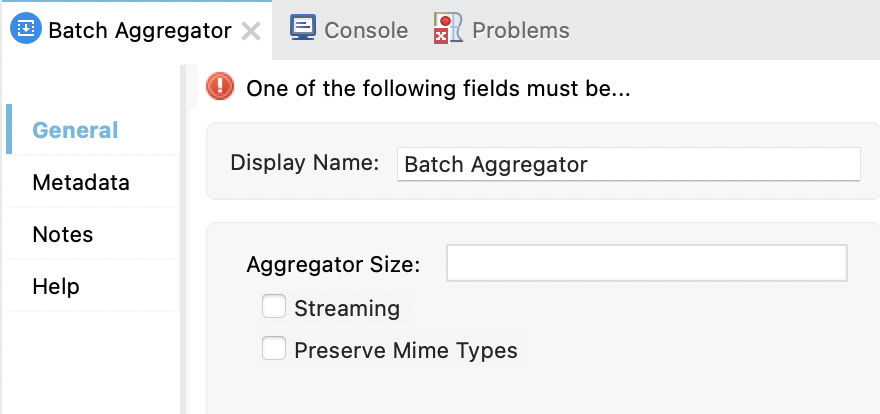
次の表に、各項目と項目の XML 要素を示します。
| 項目名 | XML | 説明 |
|---|---|---|
Display Name (表示名) |
|
コンポーネントの設定可能な名前。例: |
Aggregator Size (Aggregator サイズ) |
|
処理するレコードの各配列のサイズ。デフォルトのサイズはありません。コンポーネント内のプロセッサーは入力として配列を受け入れる必要があります。コンポーネントはレコードを残りがなくなるまでバッチステッピングキューから設定したサイズの配列に取り込み続けます。キューに含まれるレコードが設定したサイズより少ない場合、コンポーネントがこれらのレコードを処理するための取り込み先の配列が小さくなります。Size (サイズ) ( この設定を使用するときは、コンポーネントは Batch Step コンポーネントがインスタンスまたはバッチのすべてのレコードの処理を完了するのを待機しません。ステッピングキューで設定した数のレコードが使用可能になると、Batch Aggregator コンポーネントはこれらのレコードを配列に取り込んで処理します。 |
ストリーミング |
|
プロセッサーはストリーミングされたレコードの配列に順次アクセスできます。Aggregator では処理されたレコードが保持されないため、ストリーミングされたレコードへのランダムアクセスはできません。 デフォルトはありません。Size (サイズ) ( |
Preserve Mime Types (MIME タイプを保持) |
|
デフォルトは |
集計されたレコードをストリーミングするかどうかを決定するときは、次の点を考慮してください。
-
SaaS プロバイダーでは、ストリーミング入力の受入に制約がある場合が多くあります。
-
バッチストリーミングは、CSV、JSON、XML などのファイルに書き込む場合のバッチ処理に便利な場合が多くあります。
-
レコードの配列は RAM に格納され、トランザクションの処理速度が低下する可能性があるため、バッチストリーミングはアプリケーションのパフォーマンスに影響します。パフォーマンスは低下しますが、その分、ストリーミングデータが確実に使用できるようになる可能性があります。
-
ストリーミングのコミットは 1 つずつの読み取りで前方移動のみのイテレーターであるため、ストリーミングではレコードへのランダムアクセスはできません。ただし、For Each などのコンポーネントを使用した場合はストリーミング時にランダムアクセス操作を実行できます。For Each により、レコードの個別の配列が提供され、その
records 変数を使用してアクセスできます。