パラメーターの定義
パラメーターを適切に定義することは、コンポーネントの使い勝手を良くするために重要です。優れた機能を提供するコンポーネントであっても、簡単かつ直感的に設定できなければ、ユーザーはコンポーネントの力を引き出すことができません。 JSON および XML パラメーターの処理
一部の操作は、JSON または XML ドキュメント形式の値を想定したパラメーターを公開しています。
-
Java 型
JSON および XML パラメーターは、InputStream の形式で渡される必要があります。これらのデータ型を表す通常の Java 型 (Reader、Sax オブジェクト、Document、Node、JsonNode など) は使用できません。
-
DataSense による解決
想定されるスキーマに準拠したドキュメントとしてこれらのパラメーターが提供されることを保証するため、ユーザーはツールのサポートを必要とします。したがって、これらのパラメーターでは、想定されるスキーマが明確に定義されている必要があります。
-
静的 DataSense
スキーマが固定されて既知であることがあります。スキーマが既知で静的である場合は、動的な DataSense リゾルバーで問題を解決してはなりません。コネクタは、次のいずれかの方法でスキーマを指定する必要があります。
-
@InputJsonType アノテーション
モジュールのリソースの一部である JSON スキーマを参照することで想定されるデータ型を定義できるようにします。
public void createPerson(@InputJsonType(schema = "person-schema.json") @Content InputStream person) { ... } -
@InputXmlType アノテーション
@InputJsonType と同様ですが、XML スキーマを参照します。
public void createOrder(@InputXmlType(schema = "order.xsd", qname = "shiporder") @Content InputStream order) { ... } -
InputStaticTypeResolver
他の方法として、InputStaticTypeResolver を使用して、型をプログラムで定義することもできます。
public void createOrder(@TypeResolver(OrderTypeResolver.class) @Content InputStream order) { ... }
-
-
動的 DataSense
スキーマが動的である場合は、動的リゾルバーが必要です。これを行うには、InputTypeResolver インターフェースを実装します。
重要なルールは、ユーザーが準拠できる特定のスキーマにモジュールが解決される必要があるという点です。動的リゾルバーは、汎用の型である Any を返すことはできません。
public void createOrder(@TypeResolver(DynamicOrderTypeResolver.class) @Content InputStream order) { ... }
-
動的 Java 型パラメーター
コネクタが動的なデータ型を処理することは非常に一般的です。たとえば、Salesforce、NetSuite、SAP などのサービスでは、ユーザーがカスタマイズできる基本構造を持つコアエンティティ (Person、Order など) のセットを定義します。
他のサービス (OData サービスなど) では、さらに複雑で完全なカスタムデータ型セットを定義できます。
これらの動的データ型を使用するすべてのパラメーターには、現在の設定で使用する実際の型定義を提供する @TypeResolver が関連付けられている必要があります。
上のセクションでは、JSON や XML ドキュメントとして渡されるパラメーターでは @TypeResolver が必要だということを説明しました。Map やカスタム POJO などの Java 型として表されるパラメーターにも同じルールが適用されます。どの Java クラスを使用して表現されるかには関係なく、他のすべての動的データ型に対しては、慎重に定義された複雑な TypeResolver が存在する必要があります。
ストリーミング
ストリーミングは、Mule 4 の主要な側面の 1 つです。ストリーミングを活用できるように操作を定義することが重要です。
-
byte[] 配列パラメーターは使用しない
byte[] 型のパラメーターを使用してはなりません。代わりに InputStream を使用してください。Mule は、すべての byte[] パラメーター値を自動的に InputStream に変換します。
-
大きな文字列パラメーターは使用しない
文字列パラメーターそのものは問題ありませんが、サイズが 4 KB を超えた場合にどのような問題を起きるかを常に考えてください。それを超える可能性がある場合は、パラメーターは文字列ではなく InputStream として定義し、InputTypeResolver を使用して予想されるメディア種別のメタデータを提供する必要があります。
レイアウト
MuleSoft のレイアウトメカニズムは、グループとタブという 2 つの構成概念から成り立っています。
グループやタブは自由に定義できますが、標準的な名前が用意されています。
デフォルトグループ:
-
General (一般)
-
Advanced (詳細)
-
Connection (接続)
デフォルトタブ:
-
Default (デフォルト)
-
Advanced (詳細)
-
Security (セキュリティ)
-
Connection (接続)
パラメーターがこれらのカテゴリに適合しない場合は、新しいカテゴリを定義できます。その場合は、その判断について拡張機能の設計仕様に明確に記述する必要があります。
-
必須パラメーター
必須パラメーターは、常にデフォルトのグループとタブに存在する必要があり、生成される UI では最初に表示される必要があります。
必須パラメーターは、エンドユーザーが一目でわかるようにメインのグループとタブに配置する必要があります。
-
省略可能なパラメーター
省略可能なパラメーターはメインビューには配置するべきではありません。これは、平均的なユーザーであればほとんどの場合は設定しないようなパラメーターでビューを溢れさせないようにするためです。
例外:
-
設定が必須ではなく、省略可能であっても、使用する頻度が非常に高いパラメーターもあります。
-
デフォルト値が用意されているために省略可能であっても、コンポーネントの動作にとって重要なパラメーターもあります (例: http:request 操作の method パラメーター)。
-
デフォルト値
デフォルト値として式を使用するべきではありません。たとえば、イベントにアクセスする式 (
[vars]、[attributes]、[payload] など)、動的な値を取得する式 ([now()] など)、デフォルトの空の構造を作成する式 (#[[]] など) があります。
-
-
@NullSafe
Null 値の代わりに空のインスタンスを自動的に提供することで Null 値が回避されるように、Collection 型または Map 型の省略可能なパラメーターには @NullSafe アノテーションを付ける必要があります。
-
セキュリティパラメーター
セキュリティパラメーターについて述べる場合は、実際のセキュリティパラメーターと接続パラメーターを区別することが重要です。たとえば、ユーザー名とパスワードはアクセス制御に使用するため、セキュリティパラメーターとして考えることができます。しかし現実的には、これらを第一に考えなければ接続を確立することは不可能であるため、必須の接続パラメーターであるとも言えます。
-
そのため、省略可能なセキュリティパラメーター (tlsContext やハッシュアルゴリズムなど) は、必須としない場合には [Security (セキュリティ)] タブに配置する必要があります。
-
必須のセキュリティパラメーターは、他の必須パラメーターと同じように [General (一般)] タブに配置する必要があります。
-
-
パラメーターの順序
前述のように、必須パラメーターは最初に表示する必要がありますが、ではどの順序で並べるべきでしょうか? 省略可能なパラメーターについても同様です。必須パラメーターの後に並べるのは分かっていますが、どの順序で並べればよいのでしょうか?
パラメーターの順序に関する考慮事項:
-
強力かつ既知の関連性ランキングがある
一部のパラメーターが他と比べて関連性の高いことが分かっているケースがあります。関連性の根拠としては、使用される頻度やコネクタの特定ドメインとの関連性などがあります。たとえば、http:listener の場合は、他に必須パラメーターがあったとしても、path が最も関連性の高いパラメーターとなります。省略可能なパラメーターにも同じことが言えます。たとえば、allowed-methods パラメーターは、キープアライブ設定よりも関連性は高くなります。
このケースで問題となるのは、関連性が主観によって変わってしまう可能性があることです。関連性については人によって意見が分かれることもありますし、操作を呼び出すユーザーが単に間違っていることもあります。これらの場合には、拡張機能の設計ドキュメントで関連性の順序とその理由を明確に記述する必要があります。レビュー担当者にも、その順序について異議を唱える機会を与える必要があります。
-
メタデータキーの順序:
このシナリオは操作にのみ適用されます。操作のメタデータキーが階層化されている場合、メタデータキーと一致するパラメーターも同じ順序に並べるべきです。
-
使用や関連性のランキングがない
-
混在
強力な関連性を持つパラメーターグループまたはサブグループと、そうではないグループ (詳細やセキュリティなど) が混在する場合があります。
関連性が明確ではない場合には、アルファベット順に並べるべきです。
-
-
Parameter Types (パラメーターの型)
Java ベースのコネクタを扱う場合は、コネクタが外部ライブラリからの型を公開してはなりません。
たとえば、MongoDB ライブラリを使用して MongoDB Connector を作成する場合、クエリの結果は BSON オブジェクトとして表されます。この結果は、次の理由から、操作の出力または入力になることはありません。
-
コネクタが、コネクタ開発者によって管理されていない実装と結合される。
-
型を DataWeave からコンシュームまたは作成することが困難あるいは不可能である。
-
内部ライブラリがアプリケーションクラスローダーで共有され、クラスの競合が発生する可能性がある。
-
パラメーターのヒント
-
@Example
省略可能なパラメーターでデフォルトを指定しない場合は、@Example アノテーションを使用して有効な値の例を提示すべきです。これによって設定すべきデータの種類と構造について確信が持てるようになるため、Mule 開発者の UX が向上します。
これは単純型のパラメーターにのみ適用されます。POJO、リスト、マップは含まれません。 -
表示名
SDK と Studio は、パラメーターの名前を UI に表示されている名前に変換しようと最大限の努力を試みますが、それだけでは不十分な場合があります。コネクタの DSL では意味を持つ名前であっても、UI では意味を持たない場合 (そしてその逆の場合) があります。この場合は @DisplayName 機能を使用するべきです。
拡張機能で使用するパラメーター名は DSL (XML) と表示名でも使用されるため、コネクタのリリース後は、下位互換性を維持するため、この名前は変更できません。下位互換性に影響せずに UI に表示される名前を変更するには、@DisplayName アノテーションも使用できます。最後に、Java や Mule DSL とは異なり、@DisplayName では空白スペースも使用できます。
-
式のサポート
デフォルトでは、パラメーターで式を使用できます。このデフォルトを変更すべきケースもあります。
設定や接続プロバイダーのパラメーターで式をサポートすることが無意味な場合は、式のサポートを無効にしてください。たとえば、HTTP リスナーを配置するポート番号を指定する場合などです。Mule がメッセージを処理するたびにインバウンドリスナーのポートが変更されてはいけません。
どのユースケースでも固定値を取らないパラメーターでは、式の使用を必須としてください。たとえば、アグリゲーターのグループ ID を指定する場合などです。
-
概要
すべてのパラメーターには、パラメーターの目的とセマンティクスを説明する Javadoc があります。場合によっては説明が非常に長くなることがあります。このような場合には、@Summary アノテーションを使用して 1 行だけの説明を提供するとよいでしょう。概要なので、意味や目的がすべて記述されていなくても問題ありません。これは 1 行だけの短い説明であり、UI ではツールチップとして使用できます。
-
設定の上書き
設定オブジェクトでコネクタにグローバルに影響すべきパラメーターを定義する場合があります。ですが、一部のコンポーネントでは、そのパラメーターを上書きする必要がある場合もあります。
文字セットのエンコードが良い例です。File Connector で、設定レベルで使用するエンコードを定義したとします。一方、アプリケーションの特定のフローでのみ (別のフローでは設定されているエンコードを使用するとしても) 異なるエンコードを使用すべき場合があります。この場合には、@ConfigOverride アノテーションを使用する必要があります。これは (設定されているデフォルトを上書きする部分を手動でチェックする場合と比較して) コードを簡素化できるだけではありません。@ConfigOverride は、自動的に上書きを行えるだけではなく、このパラメーターが設定パラメーターを上書きしていることを Studio やフローの設計者に知らせる役割も果たし、UI を同じように表示させることができます。
-
ピースを組み合わせる
ヒントの相互作用の例を次に示します。
@Parameter @Optional @Summary("The sender 'From' address. If not provided, it defaults to the address specified in the config") @Example("example@company.com") private String fromAddress;
列挙と値プロバイダー
特定のパラメーターを事前定義済みの値のリストとしてユーザーに表示するユースケースがあります。
このリストは、固定されている場合、つまり選択できる値がすでにコンパイル時に定義されていて変更できない場合があります。たとえば、SFTP プロキシのプロトコルです。可能な値は HTTP、SOCKS4、SOCKS5 のみです。このリストは固定され、いかなる状況においても変更されることはありません。
このような場合は、モジュールで Java 列挙型をパラメーターの型として使用する必要があります。列挙は、選択可能な値をすべてリストし、SDK は設計時に自動的に適切なリストを生成します。
一方、選択できる値が動的であり、他の条件によって変更される場合があります。
たとえば、Slack Connector では、メッセージを異なるチャネルに送信できます。使用できるチャネルは、ログインしているユーザーによって異なります。そのため、リストは動的です。
カスタム値など、既知ではない (動的な) 値を含めるには、代わりに値プロバイダーを使用するべきです。
列挙を使用する状況
-
値のセットが既知である場合
-
値のセットが制限されている場合
-
値のセットがコンテキストに連動しない場合
-
値のセットがクローズドである場合
-
POJO 内でコンボが必要な場合 (値プロバイダーは POJO 内では使用できません)
値プロバイダーを使用する状況
-
値が既知ではない場合
-
値のセットが接続、設定、または他のパラメーターのコンテキストに連動している場合
-
値のセットがオープンであり、コネクタがいくつかの値を提案できるうえ、他の値も有効である場合
-
値のセットが動的である場合
排他的パラメーター
パラメーター値が無効である場合も、モジュールは起動時または実行時に失敗すべきではありません。たとえば、Scripting Module は、インラインで指定されたスクリプトまたはファイルから参照されたスクリプトを実行します。このモジュールは、2 つのパラメーターを持ちます。1 つはインラインオプションの script、もう 1 つは scriptFile です。ユーザーは一度にどちらか片方のみを使用できるため、両方とも省略可能であるとも言えます。
優れたユーザーエクスペリエンスを実現するため、UI は次の場合にユーザーにヒントを提供するように設計するべきです。
-
同時に 2 つのパラメーターが指定された場合
-
パラメーターが 1 つも指定されなかった場合
このようなユースケースでは、設計時に優れたエクスペリエンスを保証するように、排他的で省略可能な機能を活用すべきです。
POJO パラメーターの使用
POJO 型のパラメーターの定義が必要になる場合があります。シナリオによって、この方法が推奨される場合と推奨されない場合があります。
-
パラメーターのグループ化での POJO の使用
POJO パラメーターを使用するケースの一例は、複数のコンポーネント (操作やソース) に対して同じパラメーターセットを常に繰り返す場合です。Java のグッドプラクティスは、これらのパラメーターを 1 つの再利用可能なクラスにまとめることです。
たとえば、すべてのグループベースのアグリゲーターが共通のパラメーターセットを必要とする Aggregators Module を考えてください。次の例では、GroupBasedAggregatorParameterGroup クラスを作成しています。
public class GroupBasedAggregatorParameterGroup extends TimeoutContainingAggregatorParameterGroup { /** * An expression that determines the aggregation group unique ID. * This ID determines which events *must* be aggregated together. */ @Parameter @Expression(REQUIRED) @Optional(defaultValue = "#[correlationId]") private String groupId; /** * The size of the expected group to aggregate. All messages with * the same correlation ID *must* have the same groupSize. * If not, only the first message groupSize is considered and * a warning is logged. */ @Parameter @Expression(SUPPORTED) @Optional private Integer groupSize; /** * The time to remember a group ID once it was completed or timed out. * 0 means, don't remember, -1 remember forever */ @Parameter @Expression(NOT_SUPPORTED) @Optional(defaultValue = "180") private int evictionTime; /** * The unit for the evictionTime attribute */ @Parameter @Expression(NOT_SUPPORTED) @Optional(defaultValue = "SECONDS") private TimeUnit evictionTimeUnit; }このオブジェクトは次のように使用します。
@Alias("groupBasedAggregator") @Throws(GroupBasedAggregatorErrorProvider.class) public void aggregateByGroup( GroupBasedAggregatorParameterGroup aggregatorParameters, @Alias("incrementalAggregation") @Optional IncrementalAggregationRoute incrementalAggregationRoute, @Alias("aggregationComplete") AggregationCompleteRoute onAggregationCompleteRoute, RouterCompletionCallback completionCallback) throws ModuleException { // impl... }このアプローチにはいくつかの問題があります。
-
GroupBasedAggregatoParameterGroup オブジェクトはモジュールの型カタログで複雑な型を定義しますが、この型はモジュールのドメインモデルに対して実際のセマンティックな意味を持ちません。
この型は、モジュールの作成に使用したプログラミング言語のグッドプラクティスに基づいて作成された便宜上の内部型に過ぎません。そのため、この型をカタログに含める意味はありません。
-
-
型がカタログに記載されているため、モジュールの API の一部となります。
したがって、この型を変更したり、他の型に置き換えたりすると、下位互換性の問題が発生します。
-
複雑なオブジェクトは、Studio や Flow Designer で優れたユーザーエクスペリエンスを実現するのに不向きです。
これらの問題はすべて 1 つの根本原因に起因しています。モジュールの構造は、使用するプログラミング言語の微妙な違いを反映したり、その影響を受けたりするべきではありません (ここで XML SDK を使用していればこの問題は発生しなかったことに注意してください)。
生成されるモジュールで副作用を生むことなく POJO でパラメーターをまとめるには、@ParameterGroup アノテーションを使用してください。
public void aggregateByGroup( @ParameterGroup( name = "Aggregator config") GroupBasedAggregatorParameterGroup aggregatorParameters, @Alias("incrementalAggregation") @Optional IncrementalAggregationRoute incrementalAggregationRoute, @Alias("aggregationComplete") AggregationCompleteRoute onAggregationCompleteRoute, RouterCompletionCallback completionCallback) throws ModuleException { // implemented as privileged operation in GroupBasedAggregatorOperationsExecutor }このアノテーションは、メソッドの引数としてインラインで指定されたかのように、POJO を開いて中のパラメーターを公開します。ユーザーや型カタログの観点からは GroupBasedAggregatoParameterGroup は存在せず、単に操作で複数の文字列パラメーターが定義されているようにしか見えません。ただし、それでも開発者は Java POJO を活用する必要があります。
-
Mule DSL での子要素の適用
POJO パラメーターの別のユースケースは、Mule DSL で特定のパラメーターを子要素として表示する場合です。たとえば、次の Email Connector の例を見てください。
<email:send config-ref="${sender-config}" fromAddress="juan.desimoni@mulesoft.com" subject="Email Subject"> <email:to-addresses> <email:to-address value="sebastian.elizalde@mulesoft.com"/> </email:to-addresses> <email:body contentType="text/plain"> <email:content>Email Content</email:content> </email:body> </email:send><email:body> は、content パラメーターと contentType パラメーターを含む POJO です。Email Connector は非常に複雑であるため、Mule DSL では本文を子要素として表示することで読みやすさを改善できます。
この目的で POJO を使用する場合でも、上の例と同じ問題が発生しますが、ここでも @ParameterGroup アノテーションを使用することで解決できます。
@Summary("Sends an email message") @Throws(SendErrorTypeProvider.class) public void send(@Connection SenderConnection connection, @Config SMTPConfiguration configuration, @Placement(order = 1) @ParameterGroup(name = "Settings") EmailSettings settings, @Placement(order = 2) @ParameterGroup(name = "Body", showInDsl = true) EmailBody body, @Placement(order = 3) @ParameterGroup(name = "Attachments") AttachmentsGroup attachments) {例を見ると分かるように、@ParameterGroup アノテーションには showInDsl 属性があり、内部パラメーターを子要素として表示するように DSL に指示できます。
-
グローバル要素の定義
もう 1 つのユースケースは、別のコンポーネントから参照される (設定ではなく) グローバル要素の定義です。
たとえば、File Connector にはマッチャーという概念があります。マッチャーは、ファイルを処理すべきか無視すべきかを決定するために使用されるルールのセットです。マッチャーは、<file:list> 操作で、またはコネクタで定義されている任意のメッセージソースで使用できます。
異なるフローで完全に同じマッチャーが必要になることもあるため、グローバルマッチャーを定義して後で参照するための機能がコネクタに用意されています。次に例を示します。
<file:matcher name="matcher" filenamePattern="*.txt"/> <flow name="listenTxtOnly"> <file:listener config-ref="file" directory="withMatcher" matcher="matcher" autoDelete="true"> <scheduling-strategy> <fixed-frequency frequency="1000"/> </scheduling-strategy> </file:listener> <flow-ref name="processTxtFile"/> </flow>これらの場合には、@ParameterGroup アノテーションを使用せずにマッチャーパラメーターを POJO として定義する意味があります。このケースでは、実装の詳細ではなく機能のコアピースであるため、マッチャーの概念をコネクタの型カタログに含めても問題はありません。
ただし、1 つだけ注意すべき点があります。マッチャーを実装するクラスがグローバル要素として使用されるということを宣言する必要があります。
@Alias("matcher") @TypeDsl(allowTopLevelDefinition = true) public class LocalFileMatcher { /** * Files created before this date are rejected. */ @Parameter @Summary("Files created before this date are rejected.") @Optional private LocalDateTime createdSince; /** * Files created after this date are rejected */ @Parameter @Summary("Files created after this date are rejected") @Optional private LocalDateTime createdUntil; ... } -
DSL の意思決定
まとめとして、POJO とパラメーターグループの使用方法を決定するプロセスを支援するシンプル名フローチャートを示します。
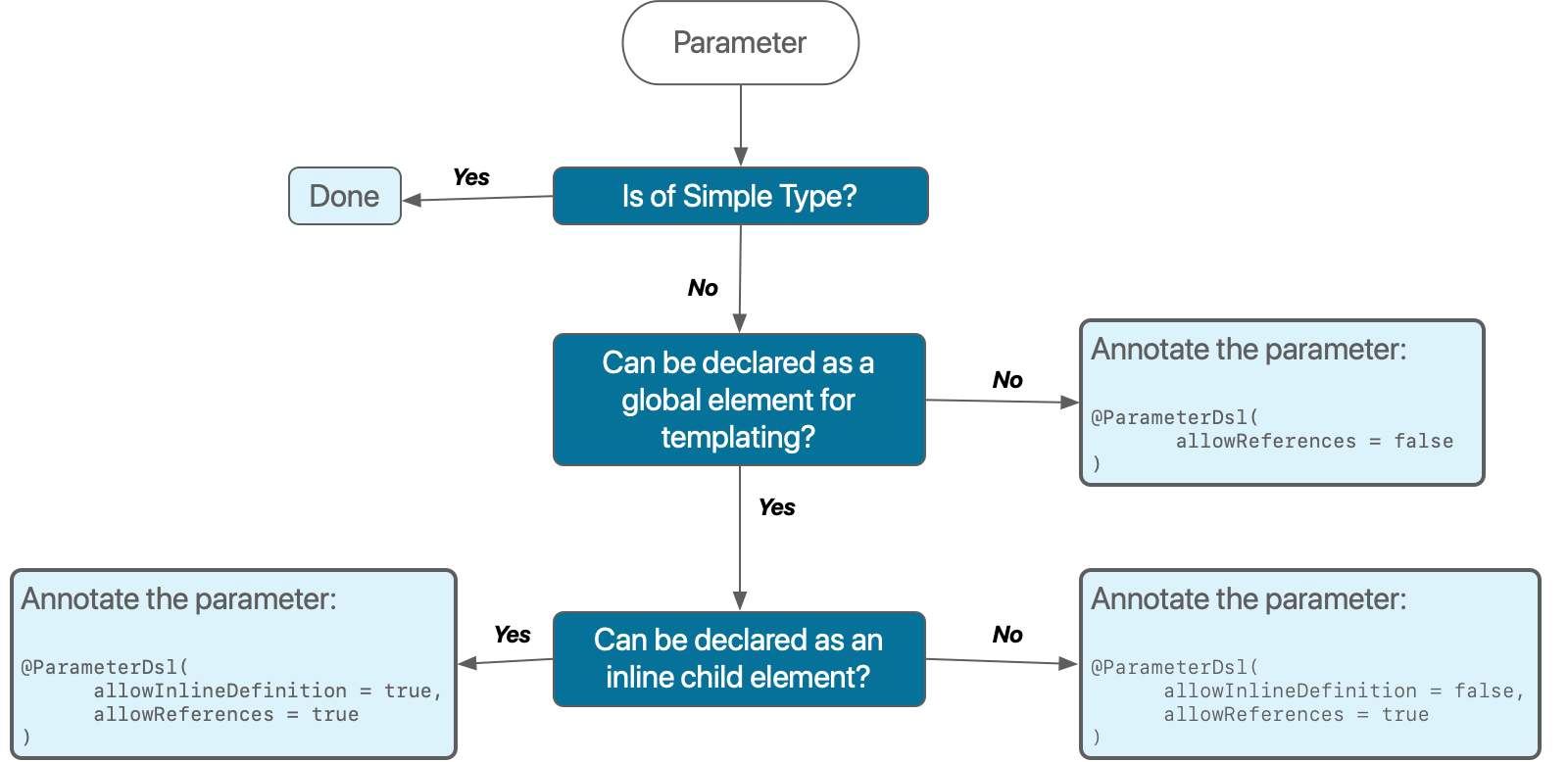
-
equals メソッドと hashCode メソッドの実装
動的設定が正しく機能するためには、POJO パラメーターまたはパラメーターグループで使用する Java クラスで equals メソッドと hashCode メソッドを実装する必要があります。
既存の設定で POJO パラメーターが使用されていない場合でも、将来のランタイム機能がこれらのメソッドに依存する可能性があるため、設定には equals メソッドと hashCode メソッドが必要です。次の Database Connector のクラスの例には、equals メソッドと hashcode メソッドが実装される様子が示されています。
/**
* Pooling configuration for JDBC Data Sources capable of pooling connections
*
* @since 1.0
*/
@Alias("pooling-profile")
public class DbPoolingProfile implements DatabasePoolingProfile {
/**
* Maximum number of connections a pool maintains at any given time
*/
@Parameter
@Optional(defaultValue = "5")
@Placement(order = 1)
@Expression(NOT_SUPPORTED)
private int maxPoolSize = 5;
/**
* Minimum number of connections a pool maintains at any given time
*/
@Parameter
@Optional(defaultValue = "0")
@Placement(order = 2)
@Expression(NOT_SUPPORTED)
private int minPoolSize = 0;
/**
* Determines how many connections at a time to try to acquire when the pool is exhausted
*/
@Parameter
@Optional(defaultValue = "1")
@Placement(order = 3)
@Expression(NOT_SUPPORTED)
private int acquireIncrement = 1;
/**
* Determines how many statements are cached per pooled connection. Setting this to zero will disable statement caching
*/
@Parameter
@Optional(defaultValue = "5")
@Placement(order = 4)
@Expression(NOT_SUPPORTED)
private int preparedStatementCacheSize = 5;
/**
* The amount of time a client trying to obtain a connection waits for it to be acquired when the pool is
* exhausted. Zero (default) means wait indefinitely
*/
@Parameter
@Optional(defaultValue = "0")
@Placement(order = 5)
@Expression(NOT_SUPPORTED)
private int maxWait = 0;
/**
* A {@link TimeUnit} which qualifies the {@link #maxWait}.
*/
@Parameter
@Optional(defaultValue = "SECONDS")
@Placement(order = 6)
@Expression(NOT_SUPPORTED)
private TimeUnit maxWaitUnit;
/**
* Determines how many seconds a Connection can remain pooled but unused before being discarded.
* Zero means idle connections never expire.
*/
@Parameter
@Optional(defaultValue = "0")
@Placement(order = 7)
@Expression(NOT_SUPPORTED)
private int maxIdleTime;
@Parameter
@Optional
@Placement(tab = ADVANCED_TAB, order = 8)
@Expression(NOT_SUPPORTED)
@Summary("Additional properties used to configure pooling profile.")
private Map<String, Object> additionalProperties = emptyMap();
//getters...
@Override
public int hashCode() {
return Objects.hash(minPoolSize, maxPoolSize, acquireIncrement, preparedStatementCacheSize, maxWaitUnit, maxWait);
}
@Override
public boolean equals(Object obj) {
if (this == obj) {
return true;
}
if (!(obj instanceof DbPoolingProfile)) {
return false;
}
DbPoolingProfile that = (DbPoolingProfile) obj;
return maxPoolSize == that.maxPoolSize &&
minPoolSize == that.minPoolSize &&
acquireIncrement == that.acquireIncrement &&
preparedStatementCacheSize == that.preparedStatementCacheSize &&
maxWait == that.maxWait &&
maxWaitUnit == that.maxWaitUnit;
}
}