Veeva Vault Connector 1.2 の追加設定情報
Veeva Vault Connector は次の操作と設定をサポートしています。
ドキュメント
ドキュメントレンディション
Vault オブジェクト
VQL クエリ
選択リスト
監査
Spark メッセージング
Invoke Rest API
Connector Configuration (コネクタ設定)

「接続設定」の手順に従います。
Create Documents
Create Documents 操作を使用すると、CSV または JSON 形式で提供されたドキュメントメタデータを使用して 1 つまたは複数のドキュメントを作成できます。ドキュメントファイルを、作成したドキュメントに添付するドキュメントコンテンツと共に Vault FTP サーバー位置にアップロードしていることを確認します。
Create Documents の設定

| 項目 | 説明 |
|---|---|
Metadata Format (メタデータ形式) |
[CSV] または [JSON] を選択して、ドキュメントメタデータの形式を指定します。 |
Document Metadata (ドキュメントメタデータ) |
CSV または JSON 形式の必須のメタデータが含まれているドキュメントメタデータのペイロード。ペイロードの形式が、[Metadata Format (メタデータ形式)] 項目で指定された形式であることを確認します。 |
入力 |
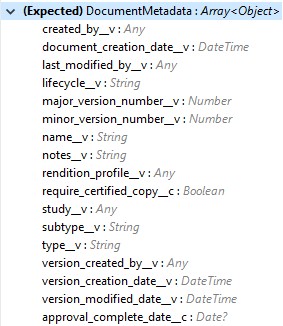
次は、Vault でのドキュメントの作成に必要なドキュメントメタデータを示しています。Vault で必要とされる必須メタデータがペイロードに含まれていることを確認します。
|
Output (出力) |
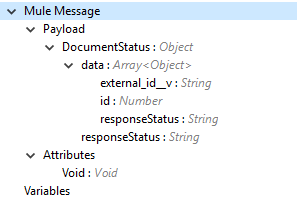
Create Documents 操作の出力状況または Vault からの応答。
注意: 操作の応答状況 (SUCCESS または FAILURE) については、「コネクタ操作の SUCCESS および FAILURE 応答」を参照してください。 |
Get Documents
Get Documents 操作を使用すると、選択したドキュメント種別、サブタイプ、分類に基づいてドキュメントの詳細を取得できます。選択した種別、サブタイプ、分類を使用して、この操作でドキュメントプロパティメタデータをフェッチし、VQL クエリを動的にビルドします。その後、この VQL クエリが Vault で実行され、ドキュメントの詳細が取得されます。この操作の後に For-Each/Splitter 要素を配置して、各ドキュメントのデータ (ページ) を順次フェッチします。
この操作では、Mule 標準ページネーションに基づくページングメカニズムが提供されます。詳細は、「ストリーミングおよびページネーション」を参照してください。
ドキュメント種別、サブタイプ、分類は省略可能です。何も選択しない場合、API (/api/{version}/metadata/objects/documents/properties) を使用してドキュメントプロパティメタデータがフェッチされ、[Document Properties (ドキュメントプロパティ)] リストに追加または挿入されたドキュメントメタデータプロパティに基づいて VQL クエリがビルドされます。メタデータプロパティが提供されていない場合、クエリ可能なすべてのドキュメントプロパティが VQL で使用され、実行されます。
Get Documents の設定
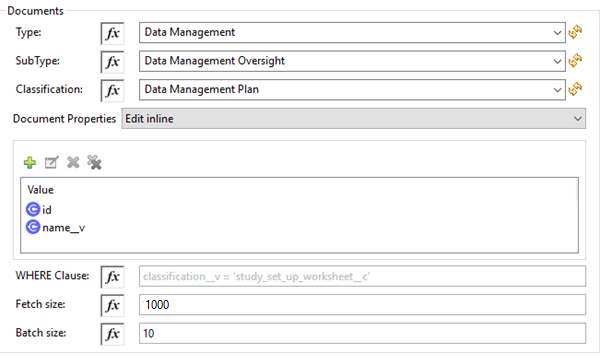
| 項目 | 説明 |
|---|---|
Type (種別) (省略可能) |
更新アイコン ( |
Subtype (サブタイプ) (省略可能) |
更新アイコン ( |
Classification (分類) (省略可能) |
更新アイコン ( |
Document Properties (ドキュメントプロパティ) (省略可能) |
ビジネス要件に従ってドキュメントプロパティを挿入します。このプロパティは、Vault で実行する VQL クエリをビルドするために使用されます。 |
WHERE Clause (Where 句) |
ビジネス要件に従って VQL WHERE 句 (キーワード WHERE を使用しない) 条件を挿入すると、WHERE 句が追加され、Vault で実行する VQL クエリが動的にビルドされます。例: |
Fetch Size (フェッチサイズ) |
1 ページあたりのレコード数を指定します。デフォルトは値 1000 です。 |
Batch Size (バッチサイズ) |
バッチごとのページ数を指定します。デフォルトは値 10 です。 |
Input (入力) |
なし |
Output (出力) |
Vault から取得したクエリ可能なドキュメントプロパティのリストが表示されます。ドキュメントプロパティリストが提供されている場合、指定したプロパティの詳細が取得され、操作の出力に表示されます。デフォルトは、クエリ可能なすべてのプロパティのリストです。 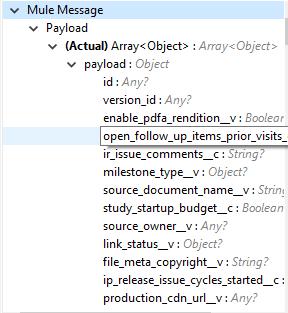
|
Delete Documents
Delete Documents 操作を使用すると、Bulk API を CSV または JSON 形式の入力メタデータと共に使用して 1 つまたは複数のドキュメントを削除できます。
Delete Documents の設定

| 項目 | 説明 |
|---|---|
Metadata Format (メタデータ形式) |
[CSV] または [JSON] を選択して、ドキュメントメタデータの形式を指定します。 |
Document Metadata (ドキュメントメタデータ) |
CSV または JSON 形式 ([Metadata Format (メタデータ形式)] で指定された値と同じ形式) の必須のメタデータが含まれているドキュメントメタデータのペイロード。 |
入力 |
次は、Vault でのドキュメントの削除に必要なドキュメントメタデータのリストを示しています。 
|
Output (出力) |
Delete Documents 操作の出力状況または Vault からの応答。 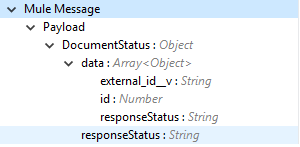
注意: 操作の応答状況 (SUCCESS または FAILURE) については、「コネクタ操作の SUCCESS および FAILURE 応答」を参照してください。 |
Update Documents
Update Documents 操作を使用すると、CSV または JSON 形式でペイロードに提供された編集可能なメタデータを使用して、一括ドキュメントを更新できます。
Update Documents の設定

| 項目 | 説明 |
|---|---|
Metadata Format (メタデータ形式) |
[CSV] または [JSON] を選択して、ドキュメントメタデータの形式を指定します。 |
Document Metadata (ドキュメントメタデータ) |
CSV または JSON 形式の編集可能な必須のメタデータが含まれているドキュメントメタデータのペイロード。ペイロードの形式は、[Metadata Format (メタデータ形式)] 項目で指定された形式である必要があります。 |
入力 |
次は、Vault でドキュメントを更新するための編集可能なドキュメントメタデータのリストです。ペイロードにはこの Vault の編集可能なメタデータのみが含まれている必要があります。 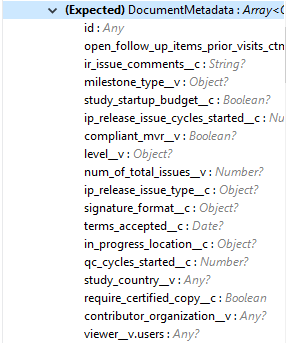
|
Output (出力) |
Create Documents 操作の出力状況または Vault からの応答。 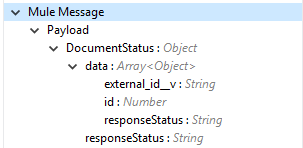
|
Export Documents
Export Documents 操作を使用すると、Vault の FTP ステージングサーバーにエクスポートするための一連のドキュメントを照会できます。Async スコープを使用して、ドキュメント ID を含むペイロードを渡すことで、Export Documents 操作を個別の非同期フローで使用することをお勧めします。
非同期で使用した場合、メインフローのプロセスが続行されている間、操作は個別のフロースレッドで実行され、指定されたポーリング間隔を待機し、ジョブが正常に終了するまでジョブの状況をポーリングします。
エクスポートされたドキュメントは、フォルダーの FTP ステージング領域に保存されます。その階層構造は次のとおりです。
{root}/{userId}/{jobId}/{documentIds}/{versions}。
ジョブの結果を応答として返す Export Documents 操作の例を次に示します。
[
{
"file": "/41601/249051/0_1/TestDocument.docx",
"user_id__v": 1885110,
"id": 249051,
"responseStatus": "SUCCESS",
"minor_version_number__v": 1,
"major_version_number__v": 0
},
{
"file": "/41601/249050/0_1/TestDocument.docx",
"user_id__v": 1885110,
"id": 249050,
"responseStatus": "SUCCESS",
"minor_version_number__v": 1,
"major_version_number__v": 0
},
{
"file": "/41601/249052/0_1/TestDocument.docx",
"user_id__v": 1885110,
"id": 249052,
"responseStatus": "SUCCESS",
"minor_version_number__v": 1,
"major_version_number__v": 0
}
]
前述の例は次の属性を示しています。
-
file
形式は "/{jobId}/{documentId}/{major-minor-version}/{filename}" です。これは、Vault FTP サーバーのステージング領域の絶対ファイルパス位置です。 -
user_id__v
コネクタ内でログイン情報が設定されているユーザーの Vault システムでのユーザー ID。フォルダーが Vault FTP サーバーのステージング領域のルート位置に作成され、その下にエクスポートされたファイルが配置されます。フォルダーは、文字「u」のプレフィックスを持つユーザー ID の名前を使用して作成されます。例:
/uXXXXXXX/{jobId}/{documentId}/{major-minor-version}/{filename}\) -
id
エクスポートされたドキュメントファイルのドキュメント ID。 -
major_version_number__v
エクスポートされたドキュメントファイルのメジャーバージョン番号。 -
minor_version_number__v
エクスポートされたドキュメントファイルのマイナーバージョン番号。
Export Documents の設定
| 項目 | 説明 |
|---|---|
Metadata Format (メタデータ形式) |
[CSV] または [JSON] を選択して、CSV または JSON 形式で指定したドキュメント ID のメタデータを受け入れます。 |
Document Metadata (ドキュメントメタデータ) |
ドキュメントメタデータのペイロードには、CSV または JSON 形式のドキュメント ID が含まれます。ペイロードの形式は、[Metadata Format (メタデータ形式)] 項目で指定された形式である必要があります。 |
ソース |
(省略可能) ソースファイルを除外するには、 |
Renditions (レンディション) |
(省略可能) レンディションを含めるには、 |
All Versions (すべてのバージョン) |
(省略可能) すべてのバージョンまたは最新バージョンを含めるには、 |
Polling Interval (ポーリング間隔) |
(省略可能) ジョブが正常に終了するまで、指定した間隔 (秒単位) で Vault をポーリングします。デフォルトは 30 秒です。 |
Input (入力) |
Vault から FTP ステージングサーバーへのドキュメントのエクスポートに必要な入力ドキュメントメタデータ。Vault で必要とされる必須メタデータがペイロードに含まれていることを確認します。 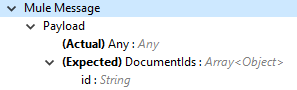
|
Output (出力) |
ドキュメントのエクスポートジョブの状況応答が [Output (出力)] タブの下に表示されます。 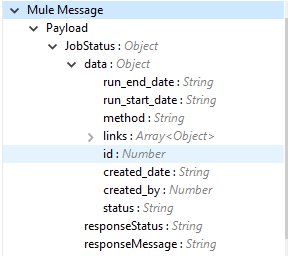
注意: 操作の応答状況 (SUCCESS または FAILURE) については、「コネクタ操作の SUCCESS および FAILURE 応答」を参照してください。 |
Create Document Renditions
Create Document Renditions 操作を使用すると、ドキュメントレンディションを一括で追加できます。この操作を使用する前に Vault が移行モードになっている必要があります。標準の UTF-8 でエンコードされた値を含む、最大サイズ 1 GB の CSV 入力データを取り込みます。
Create Document Renditions の設定

| 項目 | 説明 |
|---|---|
Metadata Format (メタデータ形式) |
[CSV] または [JSON] を選択して、ドキュメントメタデータの形式を指定します。 |
Document Metadata (ドキュメントメタデータ) |
CSV または JSON 形式の必須のメタデータが含まれているドキュメントメタデータのペイロード。ペイロードの形式は、[Metadata Format (メタデータ形式)] 項目で指定された形式である必要があります。 |
Input (入力) |
ペイロードで必要なドキュメントメタデータが [Input (入力)] タブの下に表示されます。 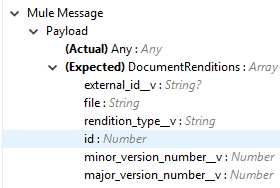
|
Output (出力) |
操作の出力または応答が [Output (出力)] タブの下に表示されます。 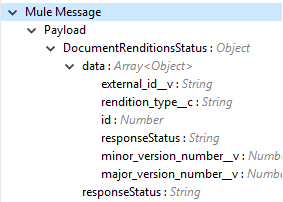
注意: 操作の応答状況 (SUCCESS または FAILURE) については、「コネクタ操作の SUCCESS および FAILURE 応答」を参照してください。 |
Get Document Renditions Types
Get Document Renditions Types 操作を使用すると、ドキュメントレンディション種別の詳細を取得できます。
Get Document Renditions Types の設定

| 項目 | 説明 |
|---|---|
Document Metadata (ドキュメントメタデータ) |
CSV または JSON 形式のドキュメント ID がペイロードに含まれます。 |
Input (入力) |
ペイロードで必要なドキュメント ID がドキュメントレンディションの詳細の取得操作の [Input (入力)] タブの下に表示されます。
|
Output (出力) |
次のような操作の出力または応答が [Output (出力)] タブの下に表示されます。
注意: 操作の応答状況 (SUCCESS または FAILURE) については、「コネクタ操作の SUCCESS および FAILURE 応答」を参照してください。 |
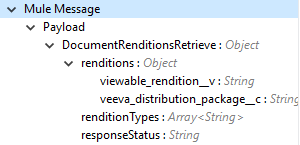
Delete Document Renditions
Delete Document Renditions 操作を使用すると、CSV または JSON 形式の入力メタデータを使用して、ドキュメントレンディションを一括で削除できます。
Delete Document Renditions の設定

| 項目 | 説明 |
|---|---|
Metadata Format (メタデータ形式) |
[CSV] または [JSON] を選択して、ドキュメントメタデータの形式を指定します。 |
Document Metadata (ドキュメントメタデータ) |
CSV または JSON 形式 ([Metadata Format (メタデータ形式)] 項目で指定された形式) の必須のメタデータが含まれているドキュメントメタデータのペイロード。 |
Input (入力) |
Vault でのドキュメントの作成に必要なドキュメントメタデータ。Vault で必要とされる必須メタデータがペイロードに含まれていることを確認します。 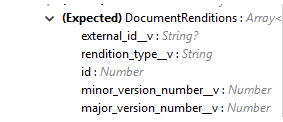
|
Output (出力) |
Delete Document Renditions 操作の出力状況または Vault からの応答。 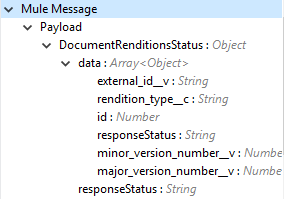
注意: 操作の応答状況 (SUCCESS または FAILURE) については、「コネクタ操作の SUCCESS および FAILURE 応答」を参照してください。 |
Create Object Records
Create Object Records 操作を使用すると、CSV または JSON 形式で提供されたオブジェクトメタデータを使用して、選択した Vault オブジェクトの一括オブジェクトレコードを作成できます。
Create Object Records の設定

| 項目 | 説明 |
|---|---|
Object Name (オブジェクト名) |
VeevaVault 更新アイコン ( |
Metadata Format (メタデータ形式) |
[CSV] または [JSON] を選択し、指定した形式でオブジェクトメタデータを受け入れます。 |
Object Metadata (オブジェクトメタデータ) |
CSV または JSON 形式の必須のメタデータが含まれているオブジェクト項目のペイロード。ペイロードの形式が、[Metadata Format (メタデータ形式)] 項目で指定された形式であることを確認します。 |
Input (入力) |
次は、オブジェクトレコードの作成に必要なオブジェクトメタデータのリストを示しています。 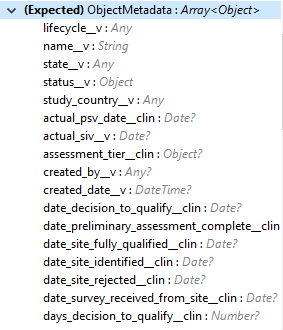
|
Output (出力) |
作成したオブジェクトレコードに関する、操作の出力または Vault から取得した応答。 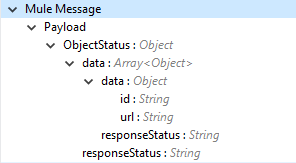
注意: 操作の応答状況 (SUCCESS または FAILURE) については、「コネクタ操作の SUCCESS および FAILURE 応答」を参照してください。 |
Get Object Records
Get Object Records 操作を使用すると、オブジェクトメタデータ項目を使用してオブジェクトレコードの詳細を取得し、VQL クエリを動的にビルドして Vault で実行し、オブジェクトの詳細を取得できます。この操作の後に For-Each/Splitter 要素を配置して、各オブジェクトレコード (ページ) を順次フェッチします。
この操作では、Mule 標準ページネーションに基づくページングメカニズムが提供されます。詳細は、「ストリーミングおよびページネーション」を参照してください。
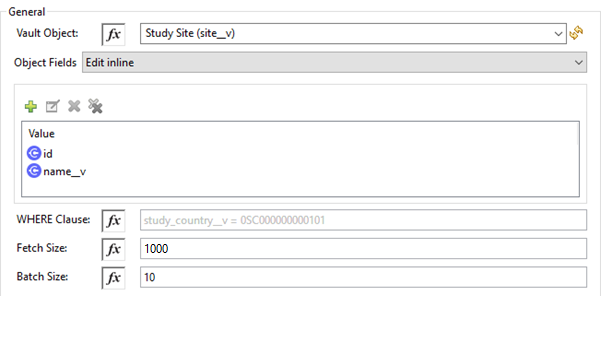
Get Object Records の設定
| 項目 | 説明 |
|---|---|
Vault Object (Vault オブジェクト) |
更新アイコン ( |
Object Fields (オブジェクト項目) |
(省略可能) ビジネス要件に従ってオブジェクト項目を挿入します。この項目は、Vault で実行する VQL クエリをビルドするために使用されます。 |
WHERE Clause (Where 句) |
ビジネス要件に従って VQL |
Fetch Size (フェッチサイズ) |
1 ページあたりのレコード数を指定します。デフォルトは値 1000 です。 |
Batch Size (バッチサイズ) |
バッチごとのページ数を指定します。デフォルトは値 10 です。 |
Input (入力) |
なし |
Output (出力) |
オブジェクト項目リストに追加するオブジェクトレコード項目のリスト。オブジェクト項目リストが提供されている場合、指定した項目の詳細が出力として返されます。デフォルトは、すべての項目のリストです。 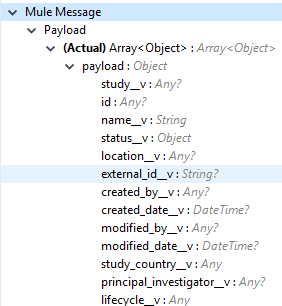
|
Delete Object Records の設定
| 項目 | 説明 |
|---|---|
Object Name (オブジェクト名) |
更新アイコン ( |
Metadata Format (メタデータ形式) |
[CSV] または [JSON] を選択し、指定した形式でドキュメントメタデータを受け入れます。 |
Object Metadata (オブジェクトメタデータ) |
CSV または JSON 形式の必須のメタデータが含まれているオブジェクト項目のペイロード。ペイロードの形式が、[Metadata Format (メタデータ形式)] 項目で指定された形式と同じであることを確認します。 |
Input (入力) |
オブジェクトレコードの削除に必要なオブジェクトメタデータのリスト。 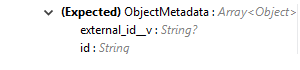
|
Output (出力) |
削除したオブジェクトレコードに関する、操作の出力または Vault から取得した応答。 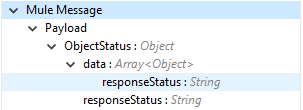
注意: 操作の応答状況 (SUCCESS または FAILURE) については、「コネクタ操作の SUCCESS および FAILURE 応答」を参照してください。 |
Update Object Records
Update Object Records 操作を使用すると、指定した Vault オブジェクトのオブジェクトレコードを更新できます。
Update Object Records の設定
| 項目 | 説明 |
|---|---|
Object Name (オブジェクト名) |
更新アイコン ( |
Metadata Format (メタデータ形式) |
[CSV] または [JSON] を選択し、指定した形式でオブジェクトメタデータを受け入れます。 |
Object Metadata (オブジェクトメタデータ) |
CSV または JSON 形式の必須のメタデータが含まれているオブジェクト項目のペイロード。ペイロードの形式が、[Metadata Format (メタデータ形式)] 項目で指定された形式と同じであることを確認します。 |
Input (入力) |
オブジェクトレコードの作成に必要なオブジェクトメタデータのリスト。 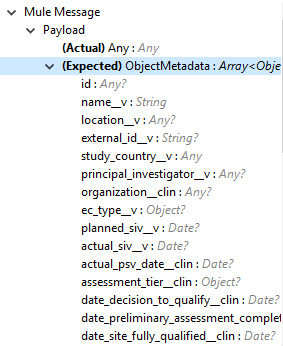
|
Output (出力) |
操作の [Output (出力)] タブの下に、更新されたオブジェクトのオブジェクト状況が出力として表示されるか、Vault から取得した応答が表示されます。 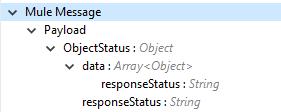
注意: 操作の応答状況 (SUCCESS または FAILURE) については、「コネクタ操作の SUCCESS および FAILURE 応答」を参照してください。 |
Query
Query 操作を使用すると、指定した VQL クエリを Vault で実行し、ページ分割されたデータ入力ストリームで結果を取得できます。Query 操作の後に For-Each/Splitter 要素を配置して、各レコードを順次フェッチします。
注意: VQL クエリで LIMIT と OFFSET を指定しないでください。これらのパラメーターは内部に組み込まれています。
この操作では、Mule 標準ページネーションに基づくページングメカニズムが提供されます。詳細は、「ストリーミングおよびページネーション」を参照してください。
Query の設定
| 項目 | 説明 |
|---|---|
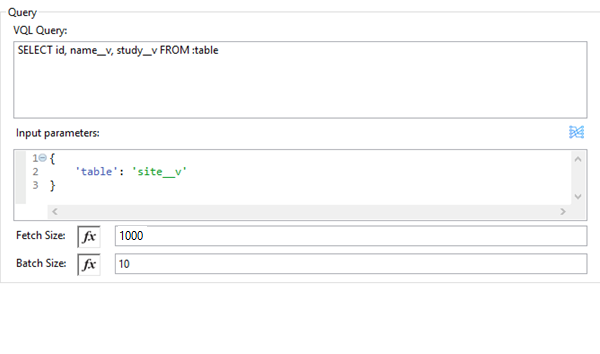
VQL クエリ |
Vault に送信する VQL クエリを入力します。 注意: VQL クエリで |
Input Parameters (入力パラメーター) |
この入力パラメーターで、パラメーターを VQL クエリに動的に渡します。パラメーターは名前-値のペアである必要があります。ペイロードまたは変数の値を渡すことができます。次に例を示します。 #[
{
'table': 'site__v',
}
]
デフォルトパラメーターは |
Fetch Size (フェッチサイズ) |
1 ページあたりのレコード数を指定します。デフォルトは値 1000 です。 |
Batch Size (バッチサイズ) |
バッチごとのページ数を指定します。デフォルトは値 10 です。 |
Input (入力) |
なし |
Output (出力) |
指定した VQL クエリ項目が操作の [Output (出力)] タブに表示されます。指定した VQL クエリが返され、結果にはページ分割されたデータが含まれます。 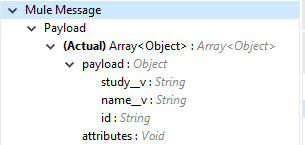
|
入力パラメーターを使用した VQL クエリの保護
Vault からドキュメント、オブジェクト、ワークフロー情報を取得するには Query 操作を使用します。その操作の主な概念は、VQL クエリを提供し、DataWeave を使用してパラメーターを提供することです。
前述の例では、入力パラメーターはキー - 値のペアで提供されます。このペアは、DataWeave スクリプトを埋め込むことで作成できます。このキーをコロン文字 (:) と組み合わせて、名前によりパラメーター値を参照します。VQL クエリでパラメーターを使用するには、この方法をお勧めします。
別の方法として、<veevavault:vql>SELECT id, namev, studyv FROM documents WHERE name__v = #[payload] </veevavault:vql> を直接記述できますが、これは非常に危険なため、お勧めできません。
入力パラメーターを使用して SELECT ステートメントの WHERE 句を設定する利点は次のとおりです。
-
クエリが VQL インジェクション攻撃の影響を受けなくなる。
-
コネクタが他の方法では不可能な最適化を実行でき、アプリケーションの全体的なパフォーマンスが向上する。

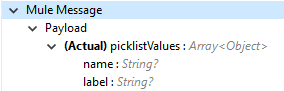
Get Audit Details
Get Audit Detail 操作を使用すると、指定した監査種別の監査の詳細を取得できます。この操作では、Mule 標準ページネーションに基づくページングメカニズムが提供されます。
詳細は、「ストリーミングおよびページネーション」を参照してください。
Get Audit Details の設定
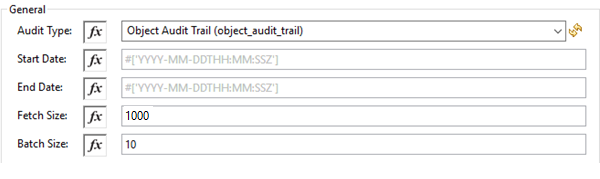
| 項目 | 説明 |
|---|---|
Audit Type (監査種別) |
更新アイコン ( |
Start date (開始日) |
(省略可能) 監査情報を取得する開始日を指定します。この日付は過去 30 日を超えることはできません。日付は |
End date (終了日) |
(省略可能) 監査情報を取得する終了日を指定します。この日付は過去 30 日を超えることはできません。日付は |
Fetch Size (フェッチサイズ) |
1 ページあたりのレコード数を指定します。デフォルトは値 1000 です。 |
Batch Size (バッチサイズ) |
バッチごとのページ数を指定します。デフォルトは値 10 です。 |
Input (入力) |
なし |
Output (出力) |
次のように、選択した監査種別の詳細が Vault からページネーション形式で取得されます。各レコードをフェッチするには、必ず 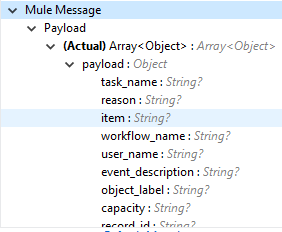
|
Spark Validator
Spark Validator 操作では、署名と公開キーを使用して、Vault からトリガーされた Spark メッセージの検証と確認を行います。検証と確認が正常に終了したら、Spark メッセージを Mule フローでビジネス要件に従ってさらに処理できます。詳細は、「 Spark メッセージングの機能およびセットアップ」を参照してください。
Spark Validator 操作の結果には、Spark 属性 (省略可能) と Spark メッセージ (Vault から受信した場合) が含まれます。
注意: Vault から Spark メッセージをトリガーする前に、Veeva Vault サポートのサポートチケットを申請して、Spark メッセージの再送信または再試行の間隔を必ず増やしてください (例: 10 秒)。デフォルトでは 3 秒として設定されていますが、この時間は、Spark Validator でメッセージの検証と確認を完了するのに必要な時間を下回っています。
注意: Veeva Systems によると、公開キー (00001.pem) の期限は 2 年ごとに切れます。ユーザーは有効期限に関する通知を事前に受け取ります。Mule アプリケーションフローでこの操作を使用している場合は、公開キーの有効期限後に、[Public Key Path (公開キーのパス)] 項目で設定されたパスから公開キーファイルを削除する必要があります。キーの削除を実行している間に新しい公開キーが作成されます。これを行わない場合、Spark メッセージの検証が INVALID_SPARK_MESSAGE として失敗します。Spark メッセージの検証を正常に終了するには、デフォルトのパスで CloudHub にデプロイされた Mule アプリケーションを再起動する必要があります。
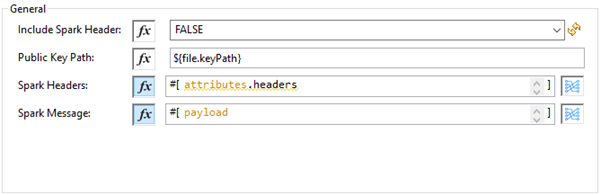
Spark Validator の設定
| 項目 | 説明 |
|---|---|
Include Spark Header (Spark ヘッダーを含める) |
Vault から受信した Spark ヘッダーを Spark Validator 出力に含めるためのフラグ。デフォルトは |
Public Key Path (公開キーのパス) |
署名付きの受信 Spark メッセージを確認するために使用する公開キー (00001.pem) ファイルの保存場所へのパス。デフォルトは、 |
Spark Headers (Spark ヘッダー) |
Vault から受信した Spark ヘッダー。デフォルトは、 |
Spark Message (Spark メッセージ) |
Vault から受信した Spark メッセージ本文。デフォルトは |
Input (入力) |
Spark Validator で必要とされる入力。 image::veevavault-connector-spark-validator-input.png[image,width=285,height=330] |
Output (出力) |
Spark Validator 操作から返された出力。 image::veevavault-connector-spark-validator-output.png[image,width=280,height=265] |
Invoke Rest API
Invoke Rest API 操作を使用すると、Veeva Vault Rest API を呼び出すことができます。応答は、ヘッダーで指定されている Accept 値に応じて JSON (デフォルト) または XML 形式で返されます。
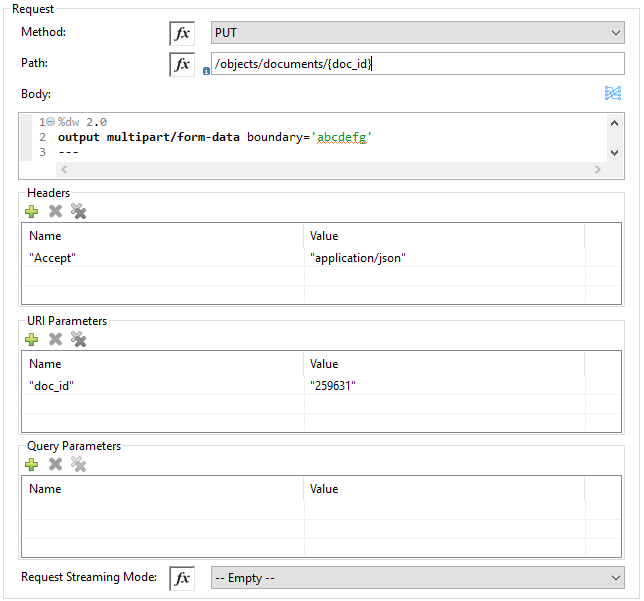
Invoke Rest API の設定
| 項目 | 説明 |
|---|---|
Method (メソッド) |
Veeva Vault Rest API を呼び出すメソッド。デフォルトは GET です。 |
Path (パス) |
Veeva Vault Rest API を呼び出す URI パス。例: |
Body (本文) |
Veeva Rest API を呼び出す要求と一緒に送信する本文。デフォルトは #[payload] です。 |
Headers (ヘッダー) |
要求と一緒に送信するキー-値形式のヘッダー。要求でヘッダーが必要ない場合は空白にしてください。デフォルトは空のリストです。 |
URI Parameters (URI パラメーター) |
パスの値を解決するためのキー-値形式の URI パラメーター。パスに URI パラメーターがない場合は空白にしてください。デフォルトは空のリストです。 |
Query Parameters (クエリパラメーター) |
要求と一緒に送信するキー-値形式のクエリパラメーター。要求でクエリパラメーターが必要ない場合は空白にしてください。デフォルトは空のリストです。 |
Request Streaming Mode (要求ストリーミングモード) |
要求でストリーミングモードを使用するかどうか。デフォルトでは、ペイロードの種別がストリームの場合、ストリーミングを使用して要求が送信されます。ドロップダウンリストからストリーミングオプションを選択します。 |
Input (入力) |
なし |
Output (出力) |
[Headers (ヘッダー)] セクションで指定されているヘッダーの Accept 値に応じて JSON (デフォルト) または XML 形式で返される応答。 |
Invoke Rest API 操作の典型的な用途は、デフォルトの GET メソッドを使用した Veeva Vault Rest API の呼び出しです。デフォルトでは、GET メソッドは要求でペイロードを送信しないため、HTTP 要求の本文は空です。他のメッセージでは、要求の本文としてメッセージペイロードが送信されます。
要求の送信後、コネクタはヘッダーで指定されている Accept 値に応じて JSON (デフォルト) または XML 形式で返される応答を受信します。ペイロードは、アプリケーションのフローの次の要素に渡されます。
パラメーターの追加
デフォルトでは、Invoke Rest API 操作は Mule メッセージペイロードを要求の本文として送信しますが、これは DataWeave スクリプトまたは式を使用してカスタマイズできます。要求の本文に加えて、以下を設定できます。
-
ヘッダー
-
クエリパラメーター
-
URI パラメーター
ヘッダー
[General (一般)] > [Request (要求)] > [Query Parameters (クエリパラメーター)] で、プラスアイコン (+) をクリックしてヘッダーを要求に追加します。たとえば、ヘッダー名 HeaderName1 および HeaderName2 とヘッダー値 HeaderValue1 および HeaderValue2 を追加します。
DataWeave 式を使用できます。例:
#[{'HeaderName1' : 'HeaderValue1', 'HeaderName2' : 'HeaderValue2'}].
URI パラメーター
要求のパスにプレースホルダー (/objects/documents/{doc_id} など) を使用する場合は、URI パラメーターを設定します。URI パラメーターを設定するには、[Path (パス)] 項目にプレースホルダーを中括弧で囲んで入力します。[URI Parameters (URI パラメーター)] を選択し、[+] をクリックして名前と値を入力します。
クエリパラメーター
[General (一般)] > [Request (要求)] > [Query Parameters (クエリパラメーター)] で、プラスアイコン (+) をクリックしてパラメーターを要求に追加します。パラメーターの名前と値を入力するか、DataWeave 式を使用して名前と値を定義します。
POST 要求での form (フォーム) パラメーターの送信
POST 要求でパラメーターを送信する方法:
-
[General (一般)] > [Request (要求)] で、POST メソッドを選択します。
-
[Body (本文)] に、Mule メッセージのペイロードを入力します。
例を示します。
-
application/x-www-form-urlencoded で送信するパラメーターの名前と値を入力します。
#[output application/x-www-form-urlencoded --- {'key1':'value1', 'key2':'value2'}] -
multipart/form-data では、ヘッダーの Content-Type 値に DataWeave 出力と同じ境界属性値が含まれていることを確認してください。例:
multipart/form-data; boundary=abcdefg。%dw 2.0 output multipart/form-data boundary='abcdefg' --- { parts: { file: { headers: { "Content-Disposition": { "name": "file", "filename": attributes.fileName }, "Content-Type": payload.^mimeType }, content : payload }, name__v: { headers: { }, content: 'Test Document' }, type__v: { headers: { }, content: 'Trial Management' }, subtype__v: { headers: { }, content: 'Meetings' }, classification__v: { headers: { }, content: 'Kick-off Meeting Material' }, lifecycle__v: { headers: { }, content: 'Base Doc Lifecycle' }, study__v: { headers: { }, content: '0ST000000000301' }, comments__c: { headers: { }, content: 'Test Document' } } }
-
コネクタ操作の SUCCESS および FAILURE 応答
Veeva Vault Connector 操作の応答は、Veeva Vault API の成功または失敗応答とエラーに基づきます。
コネクタは SUCCESS 応答を HIGH LEVEL で返し、SUCCESS または FAILURE を LOW LEVEL で返します。つまり、コネクタ操作が正常に終了しても、要求に渡された関連のない一部のデータのために一部のドキュメントまたはオブジェクトレコードの作成または更新が失敗していることがあります。
例
SUCCESS を含む SUCCESS 応答:
{
"responseStatus": "SUCCESS",
"data": [{
"id": 239026,
"name__v": "E22611234--38483",
"responseStatus": "SUCCESS"
},
{
"id": 239025,
"name__v": "Kick-off Meeting Material Updated12341234--81032",
"responseStatus": "SUCCESS"
}
]
}
FAILURE を含む SUCCESS 応答:
{
"data": [
{
"external_id__v": "TEST-238924",
"rendition_type__v": "imported_rendition__c",
"id": 238924,
"responseStatus": "FAILURE",
"minor_version_number__v": 1,
"errors": [
{
"type": "INVALID_DATA",
"message": "Document not found [238924/0/1]."
}
],
"major_version_number__v": 0
},
{
"external_id__v": "TEST-238925",
"rendition_type__v": "imported_rendition__c",
"id": 238925,
"responseStatus": "FAILURE",
"minor_version_number__v": 1,
"errors": [
{
"type": "INVALID_DATA",
"message": "Document not found [238925/0/1]."
}
],
"major_version_number__v": 0
}
],
"responseStatus": "SUCCESS"
}
Veeva Vault API で FAILURE 応答が返されると、Veeva Vault 操作で例外がスローされます。次に例を示します。
ERROR を含む FAILURE 応答
{
"responseStatus": "FAILURE",
"errors": [
{
"type": "INVALID_DATA",
"message": "Unknown relationship [reviewer__v]"
}
]
}
Veeva Vault API から FAILURE 応答を受信すると、コネクタ操作で例外がスローされ、Mule フロー内の Error Handling コンポーネントでキャッチされます。
********************************************************************************** Message : An error occurred from the Veeva Vault API. Error Code: INVALID_DATA. Original Error Message: Unknown relationship [reviewer__v]. Error type : VEEVAVAULT:INVALID_DATA **********************************************************************************
エラー処理コンポーネントでキャッチされるエラーコードを次に示します。
-
VEEVAVAULT:API_LIMIT_EXCEEDED
-
VEEVAVAULT:ATTRIBUTE_NOT_SUPPORTED
-
VEEVAVAULT:INACTIVE_USER
-
VEEVAVAULT:INVALID_DATA
-
VEEVAVAULT:INVALID_DOCUMENT
-
VEEVAVAULT:INSUFFICIENT_ACCESS
-
VEEVAVAULT:MALFORMED_URL
-
VEEVAVAULT:METHOD_NOT_SUPPORTED
-
VEEVAVAULT:NO_PERMISSION
-
VEEVAVAULT:OPERATION_NOT_ALLOWED
-
VEEVAVAULT:PARAMETER_REQUIRED
ストリーミングおよびページネーション
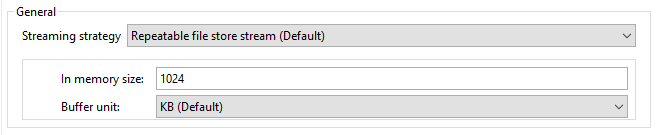
コネクタ内のすべての操作 (Download Document を除く) が、操作の出力に基づく各結果を含むペイロードとして InputStream を返します。このため、デフォルトでは、Mule ではストリーミング戦略が適用されます。詳細は、Mule ストリーミング戦略を参照してください。ストリーミング戦略の設定項目は、コネクタ操作の [Advanced (詳細)] タブにあります。
コネクタ内の次の操作では、Mule 標準ページネーションに基づくページネーションメカニズムが提供されます。
ページ分割操作を使用していますが、必ず For-Each/Splitter 要素を配置して各オブジェクト (メタデータは JSON 形式) を一度に取得してください。ページネーション操作には、[Fetch Size (フェッチサイズ)] 項目と [Batch Size (バッチサイズ)] 項目があります。
-
Fetch Size (フェッチサイズ)
フェッチサイズは、1 つのページで取得できるレコードの制限数です。操作は、フェッチサイズの数の JSON オブジェクトレコードを含むページを返します。
場合によって、Veeva API でレコードサイズに基づいてフェッチサイズ (各ページのレコード数) が自動計算され、その計算で標準レコードサイズを超えることがあります。操作は、各ページで計算されたレコード数を返します。 -
Batch Size (バッチサイズ)
バッチサイズは各バッチで返されるページ数であり、各ページにはフェッチサイズの数のレコードが含まれます。操作はバッチごとに多数のレコード (JSON 形式のメタデータ) を返し、計算は次の例のように行われます。
Fetch Size set as *1000* Batch Size set as *10* If the total records in the vault are *100,000*, then: Number of pages = Total records/Fetch Size = 100000/1000 = 100 pages. Number of pages per batch = Number of pages/Batch Size = 100/10 = 10 pages per batch. Number of Records per batch = Number of pages per batch * Fetch Size = 10 * 1000 = 10,000 records. Therefore, the number of records returned per batch would be 10,000 records.
反復可能ストリームはバッファサイズをバイト単位で測定します。オブジェクトを処理するときに、ランタイムはインスタンス数を使用してバッファサイズを測定します。
反復不可能ストリームのコネクタ操作では、ストリームはバッチごとのレコード数として返されます。反復可能ストリームでは、すべてのレコードが一度に返されるため、反復可能自動ページングでメモリ内のバッファサイズを計算する場合は、メモリ不足にならないように、各インスタンスが使用するメモリ量を見積もる必要があります。
次のステップ
コネクタの設定が完了したら、例を試すことができます。