Formats
DataWeave supports different types of data formats. Each format has an associated reader and a writer, and in some cases custom types are allowed. Each reader and writer defines configuration properties for customization.
Java
Canonical Model
The mapping between Java objects to DataWeave types is quite simple:
| Java Type | DataWeave Type |
|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Metadata property class
Java developers use the 'class' metadata key as hint for what class needs to be created and sent as an input. If this is not explicitly defined, DataWeave tries to infer from the context or it assigns it the default values:
-
java.util.HashMap for objects
-
java.util.ArrayList for lists
%dw 1.0
%type user = :object { class: "com.anypoint.df.pojo.User"}
%output application/xml
---
{
name : "Mariano",
age : 31
} as :userThe above code defines the type of the required input as an instance of 'com.anypoint.df.pojo.User'.
:enum
In order to put an enum value in a java.util.Map, the DataWeave java module defines a custom type called :enum. It allows you to specify that a given string should be handled as the name of a specified enum type. It should always be used with the class property with the java class name of the enum.
CSV
Canonical Model
CSV content is modeled in DataWeave as a list of objects, where every record is an object and every field in it is a property. For example:
Name,Last Name
Mariano, De achaval
Leandro, Shokida[
{
Name: "Mariano",
"Last Name": " De achaval"
},
{
Name: "Leandro",
"Last Name": " Shokida"
}
]Reader Properties (for CSV)
In CSV you can assign any special character as the indicator for separating fields, toggling quotes, or escaping quotes. Make sure you know what special characters are being used in your input, so that DataWeave can interpret it correctly.
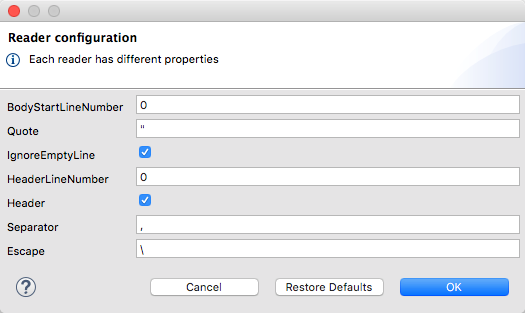
When you define an input of type CSV, there are a few optional parameters you can add in the XML definition of your Mule project to customize how the data is parsed.
| Parameter | Type | Default | Description |
|---|---|---|---|
separator |
char |
, |
Character that separates one field from another |
quote |
char |
" |
Character that delimits the field values |
escape |
char |
\ |
Character used to escape occurrences of the separator or quote character within field values |
bodyStartLineNumber |
number |
0 |
The line number where the body starts. |
ignoreEmptyLine |
boolean |
true |
defines if empty lines are ignored |
header |
boolean |
true |
Indicates if the first line of the output shall contain field names |
headerLineNumber |
number |
0 |
the line number where the header is located |
|
When When |
You can set theses properties through the XML of your Mule project:
<dw:transform-message metadata:id="33a08359-5085-47d3-aa5f-c7dd98bb9c61"
doc:name="Transform Message">
<dw:input-payload
<!-- Boolean that defines if the first line in the data contains headers -->
<dw:reader-property name="header" value="false" />
<!-- Character that separates fields, `','` by default -->
<dw:reader-property name="separator" value="," />
<!-- Character that defines quoted text, `" "` by default -->
<dw:reader-property name="quote" value=""" />
<!-- Character that escapes quotes, `\` by default -->
<dw:reader-property name="escape" value="\" />
</dw:input-payload>
<dw:set-payload>
<![CDATA[
%dw 1.0
%output application/java
---
// Your transformation script goes here
]]>
</dw:set-payload>
</dw:transform-message>Alternatively, you can set the properties through the UI of the Transform Message component:
Writer Properties (for CSV)
When you define an output of type CSV, there are a few optional parameters you can add to the output directive to customize how the data is parsed:
| Parameter | Type | Default | Description |
|---|---|---|---|
separator |
char |
, |
Character that separates one field from another |
encoding |
string |
The character set to be used for the output |
|
quote |
char |
" |
Character that delimits the field values |
escape |
char |
\ |
Character used to escape occurrences of the separator or quote character within field values |
lineSeparator |
string |
system line ending default |
line separator to be used. An important use case is the conversion of a Windows line ending to a Unix line ending. Examples: "\r\n" (for Windows), "\n" (for Unix) |
header |
boolean |
true |
Indicates if the first line of the output shall contain field names |
quoteHeader |
boolean |
false |
Indicates header values should be quoted |
quoteValues |
boolean |
false |
Indicates if every value should be quoted whether or not it contains special characters within |
All of these parameters are optional. A CSV output directive might for example look like this:
%output text/csv separator=";", header=false, quoteValues=true, lineSeparator="\n"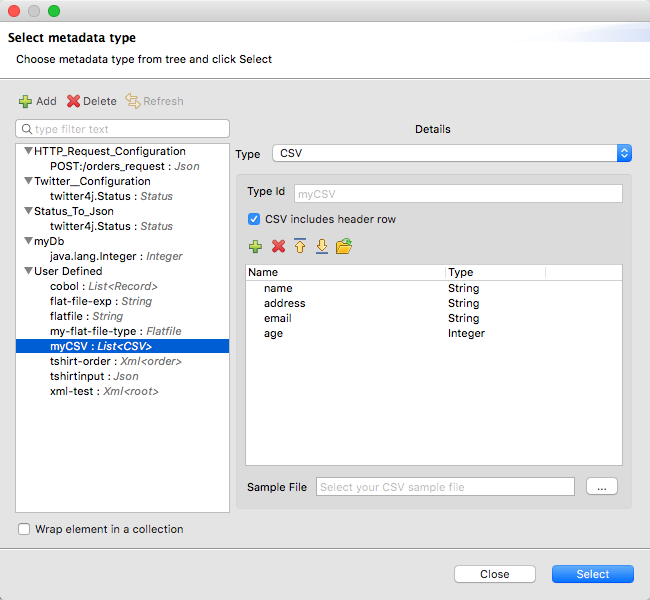
Excel
Canonical Model
An excel workbook is a sequence of sheets, in DataWeave this is mapped to an object where each sheet is a key. Only one table is allowed per excel sheet. A table is expressed as an array of rows. A row is an object where its keys are the columns and the values the cell content.
For example:
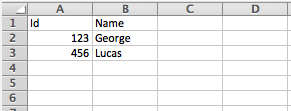
%output application/xlsx header=true
---
{
Sheet1: [
{
Id: 123,
Name: George
},
{
Id: 456,
Name: Lucas
}
]
}Reader Properties (for Excel)
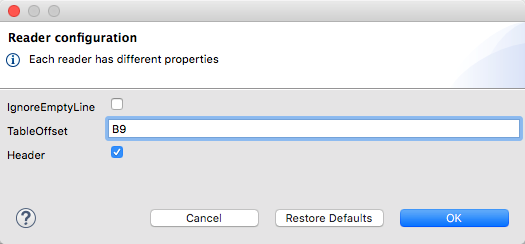
When you define an input of type excel, there are a few optional parameters you can add in the XML definition of your Mule project to customize how the data is parsed.
| Parameter | Type | Default | Description |
|---|---|---|---|
header |
boolean |
true |
defines if the excel tables contain headers. When set to false, column names are used. (A, B, C, …) |
ignoreEmptyLine |
boolean |
true |
defines if empty lines are ignored |
tableOffset |
string |
A1 |
The position of the first cell of the tables |
These properties can be either set via the XML of your Mule project:
<dw:transform-message metadata:id="33a08359-5085-47d3-aa5f-c7dd98bb9c61"
doc:name="Transform Message">
<dw:input-payload
<!-- Boolean that defines if the first line in the data contains headers -->
<dw:reader-property name="header" value="true" />
<!-- Boolean that defines if empty lines are ignored -->
<dw:reader-property name="ignoreEmptyLine" value="false" />
<!-- Defines that defines what cell to start reading from. In this case Column A is ignored, and all rows above 9 -->
<dw:reader-property name="tableOffset" value="B9" />
</dw:input-payload>
<dw:set-payload>
<![CDATA[
%dw 1.0
%output application/java
---
// Your transformation script goes here
]]>
</dw:set-payload>
</dw:transform-message>Or via the UI of the Transform Message component:
Writer Properties (for Excel)
When you define an output of type excel, there are a few optional parameters you can add to the output directive to customize how the data is parsed:
| Parameter | Type | Default | Description |
|---|---|---|---|
header |
boolean |
true |
defines if the excel tables contain headers. When there are no headers, column names are used. (A, B, C, …) |
ignoreEmptyLine |
boolean |
true |
defines if empty lines are ignored |
tableOffset |
string |
A1 |
The position of the first cell of the tables |
All of these parameters are optional. An excel output directive might for example look like this:
%output application/xlsx header=true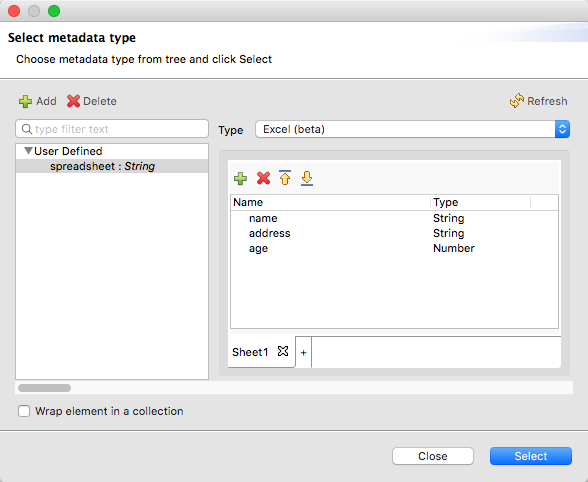
XML
Canonical Model
The XML data-structure is mapped to DataWeave objects that may contain other objects as values to their keys. Repeated keys are supported. For example:
<users>
<company>MuleSoft</company>
<user name="Leandro" lastName="Shokida"/>
<user name="Mariano" lastName="Achaval"/>
</users>{
users: {
company: "MuleSoft",
user @(name: "Leandro",lastName: "Shokida"): "",
user @(name: "Mariano",lastName: "Achaval"): ""
}
}Reader Properties (for XML)
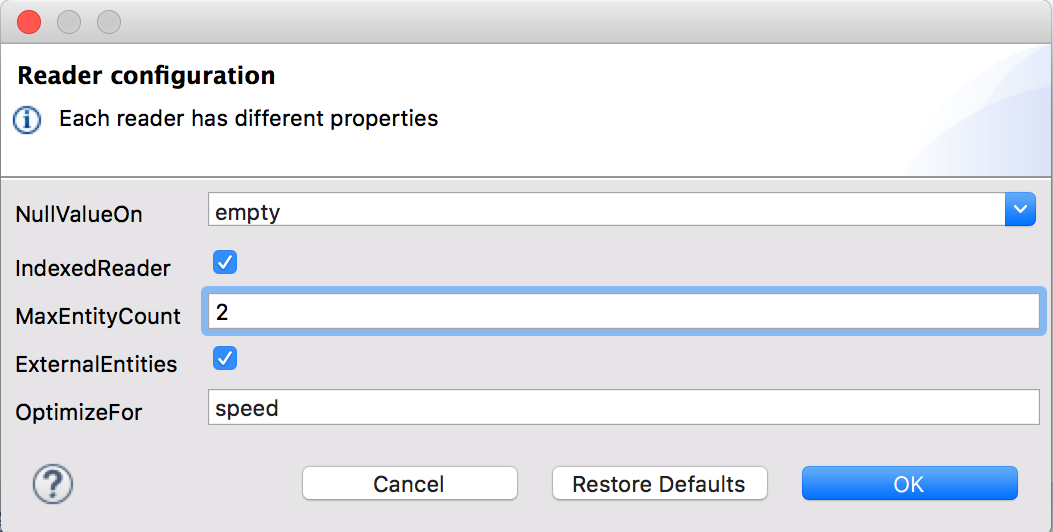
When you define an input of type XML, there are a few optional parameters you can add in the XML definition of your Mule project to customize how the data is parsed.
| Parameter | Type | Default | Description |
|---|---|---|---|
|
string |
speed |
specifies the strategy to be used by the reader. Posible values = memory/speed |
|
string |
'empty' |
If a tag with empty or blank text should be read as null. |
|
boolean |
true |
Picks which reader modality to use. The indexed reader is faster but uses up a greater amount of memory, whilst the unindexed reader is slower but uses up less memory |
|
integer |
1 |
Limits the number of times that an entity can be referenced within the XML code. This is included to guard against denial of service attacks. |
|
boolean |
false |
Defines if references to entities that are defined in a file outside the XML are accepted as valid. It’s recommended to avoid these for security reasons as well. |
|
|
|
Enable or disable DTD support. Disabling skips (and does not process) internal and external subsets. Valid Options are |
These properties can be either set via the XML of your Mule project:
<dw:transform-message metadata:id="33a08359-5085-47d3-aa5f-c7dd98bb9c61"
doc:name="Transform Message">
<dw:input-payload
<!-- specifies the strategy to be used by the reader -->
<dw:reader-property name="optimizeFor" value="speed" />
<!-- If a tag with empty or blank text should be read as null. -->
<dw:reader-property name="nullValueOn" value="empty" />
</dw:input-payload>
<dw:set-payload>
<![CDATA[
%dw 1.0
%output application/xml
---
// Your transformation script goes here
]]>
</dw:set-payload>
</dw:transform-message>Or via the UI of the Transform Message component:
Writer Properties (for XML)
When you define an output of type XML, there are a few optional parameters you can add to the output directive to customize how the data is parsed:
| Parameter | Type | Default | Description |
|---|---|---|---|
|
boolean |
true |
Defines if the XML code will be indented for better readability, or if it will be compressed into a single line |
|
string |
|
Defines whether an empty XML child element appears as single self-closing tag or with an opening and closing tag. The value |
|
string |
UTF-8 |
The character set to be used for the output |
|
number |
153600 |
The size of the buffer writer |
|
string |
When the writer should use inline close tag. Possible values = |
|
|
string |
Possible values = |
|
|
boolean |
true |
Defines if the XML declaration will be included in the first line |
%output application/xml indent=false, skipNullOn="attributes"The inlineCloseOn parameter defines if the output is structured like this (by default):
<someXml>
<parentElement>
<emptyElement1></emptyElement1>
<emptyElement2></emptyElement2>
<emptyElement3></emptyElement3>
</parentElement>
</someXml>or like this (set with a value of "empty"):
<payload>
<someXml>
<parentElement>
<emptyElement1/>
<emptyElement2/>
<emptyElement3/>
</parentElement>
</someXml>
</payload>Skip Null On (for XML)
You can specify whether your transform generates an outbound message that contains fields with "null" values, or if these fields are ignored entirely. This can be set through an attribute in the output directive named skipNullOn, which can be set to three different values: elements, attributes, or everywhere.
When set to: * elements: A key:value pair with a null value is ignored. * attributes: An XML attribute with a null value is skipped. * everywhere: Apply this rule to both elements and attributes.
Defining a Metadata Type (for XML)
In the Transform Message component, you can define a XML type through the following methods:
-
By Providing a sample file
-
By pointing to a schema file
Custom Types
:cdata
XML defines a custom type named :cdata, it extends from string and is used to identify a CDATA XML block.
It can be used to tell the writer to wrap the content inside CDATA or to check if the input string arrives inside a CDATA block. :cdata inherits from the type :string.
%dw 1.0
%output application/xml
---
{
users:
{
user : "Mariano" as :cdata,
age : 31 as :cdata
}
}<?xml version="1.0" encoding="UTF-8"?>
<users>
<user><![CDATA[Mariano]]></user>
<age><![CDATA[31]]></age>
</users>JSON
Canonical Model
JSON data-structures are mapped to DataWeave data-structures in a straight forward way as they share a lot of similarities.
Writer Properties (for JSON)
When you define an output of type JSON, there are a few optional parameters you can add to the output directive to customize how the data is parsed:
| Parameter | Type | Default | Description |
|---|---|---|---|
|
boolean |
true |
Defines if the JSON code will be indented for better readability, or if it will be compressed into a single line |
|
string |
UTF-8 |
The character set to be used for the output |
|
number |
153600 |
The size of the buffer writer |
|
string |
When the writer should use inline close tag. Possible values = empty/none |
|
|
string |
Possible values = |
|
|
boolean |
false |
JSON language doesn’t allow duplicate keys with one same parent, this usually raises an exception. If set to true, the output contains a single key that points to an array containing all the values assigned to it. |
%output application/json indent=false, skipNullOn="elements"Skip Null On (for JSON)
You can specify whether this generates an outbound message that contains fields with "null" values, or if these fields are ignored entirely. This can be set through an attribute in the output directive named skipNullOn, which can be set to three different values: elements, attributes, or everywhere.
When set to: * elements: A key:value pair with a null value is ignored. * attributes: An XML attribute with a null value is skipped. * everywhere: Apply this rule to both elements and attributes.
Flat File
Reader Properties (for Flat File)
When you define an input of type Flat File, there are a few optional parameters you can add in the XML definition of your Mule project to customize how the data is parsed.
| Flat file in DataWeave supports files of up to 15 MB, and the memory requirement is roughly 40 to 1. For example, a 1-MB file requires up to 40 MB of memory to process, so it’s important to consider this memory requirement in conjunction with your TPS needs for large flat files. This is not an exact figure; the value might vary according to the complexity of the mapping instructions. |
Flat file reader properties are the same as the COBOL copybook reader properties. See Reader Properties (for Copybook).
These properties can be set through the XML of your Mule project:
<dw:input-payload mimeType="text/plain" >
<dw:reader-property name="schemaPath" value="myschema.esl"/>
<dw:reader-property name="structureIdent" value="structure1"/>
</dw:input-payload>Alternatively, you can set them through the UI of the Transform Message component.
Schemas with type Binary or Packed don’t allow for line breaks to be detected, so setting recordParsing to "lenient"` will only allow long records to be handled, but not short ones. These schemas also currently only work with certain single-byte character encodings (so not with UTF-8 or any multibyte format).
|
Writer Properties (for Flat File)
When you define an output of type Flat File there are a few optional parameters you can add to the output directive to customize how the data is written:
Flat file writer properties are the same as the COBOL copybook writer properties. See Writer Properties (for Copybook).
%dw 1.0
%output text/plain schemaPath="src/main/resources/test-data/QBReqRsp.esl", structureIdent=“QBResponse"
---
payload|
See DataWeave Flat File or EDI Schemas for instructions and examples on how to create the required schema file. |
Fixed Width
Fixed Width types are technically considered a type of Flat File format, but when you select this option, the Transform Message component offers you settings that are better tailored to the needs of this format.
| Fixed width in DataWeave supports files of up to 15 MB, and the memory requirement is roughly 40 to 1. For example, a 1-MB file requires up to 40 MB of memory to process, so it’s important to consider this memory requirement in conjunction with your TPS needs for large fixed width files. This is not an exact figure; the value might vary according to the complexity of the mapping instructions. |
Reader Properties (for Fixed Width)
When you define an input of type Fixed Width, there are a few optional parameters you can add in the XML definition of your Mule project to customize how the data is parsed.
Fixed Width reader properties are the same as the COBOL copybook reader properties. See Reader Properties (for Copybook).
These properties can be either set via the XML of your Mule project:
<dw:input-payload mimeType="text/plain" >
<dw:reader-property name="schemaPath" value="myschema.ffd"/>
<dw:reader-property name="structureIdent" value="structure1"/>
</dw:input-payload>Or via the UI of the Transform Message component
Writer Properties (for Fixed Width)
When you define an output of type Fixed Width, there are a few optional parameters you can add to the output directive to customize how the data is written:
Fixed Width writer properties are the same as the COBOL copybook writer properties. See Writer Properties (for Copybook).
%dw 1.0
%output text/plain schemaPath="src/main/resources/test-data/QBReqRsp.esl", encoding="UTF-8"
---
payload|
See DataWeave Flat File or EDI Schemas for instructions and examples on how to create the required schema file. |
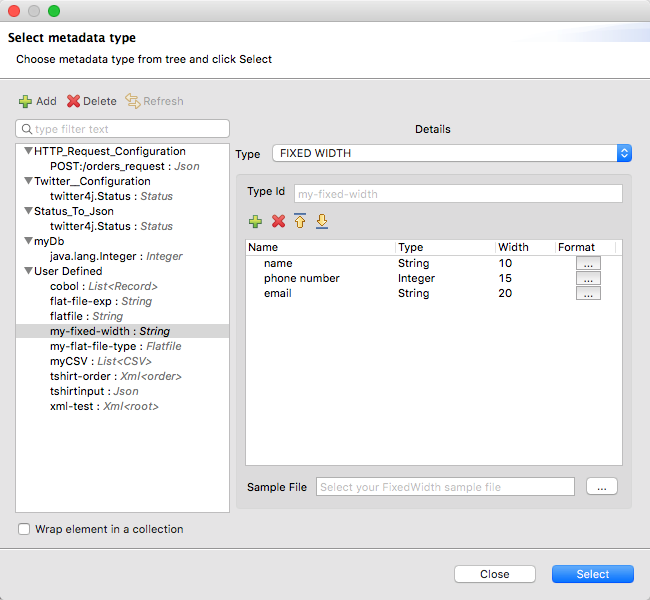
Defining a Metadata Type
In the Transform Message component, you can define a Fixed Width type through the following methods:
-
By Providing a sample file
-
By pointing to a [flat file] schema file
-
Via a graphical editor that allows you to set up each field manually
COBOL Copybook
Copybook types are technically considered a type of Flat File format, but when you select this option, the Transform Message component offers you settings that are better tailored to the needs of the COBOL Copybook format.
| Cobol copybook in DataWeave supports files of up to 15 MB, and the memory requirement is roughly 40 to 1. For example, a 1-MB file requires up to 40 MB of memory to process, so it’s important to consider this memory requirement in conjunction with your TPS needs for large copybook files. This is not an exact figure; the value might vary according to the complexity of the mapping instructions. |
Importing a Copybook Definition
When you import a Copybook definition, the Transform Message component converts
the definition to a flat file schema that you can reference with schemaPath
property.
To import a copybook definition:
-
Right-click the input payload in the Transform component in Studio, and select Set Metadata to open the Set Metadata Type dialog.
Note that you need to create a metadata type before you can import a copybook definition.
-
Provide a name for your copybook metadata, such as
copybook. -
Select the Copybook type from the Type drop-down menu.
-
Import your copybook definition file.
-
Click Select.
For example, assume that you have a copybook definition file
(mailing-record.cpy) that looks like this:
01 MAILING-RECORD.
05 COMPANY-NAME PIC X(30).
05 CONTACTS.
10 PRESIDENT.
15 LAST-NAME PIC X(15).
15 FIRST-NAME PIC X(8).
10 VP-MARKETING.
15 LAST-NAME PIC X(15).
15 FIRST-NAME PIC X(8).
10 ALTERNATE-CONTACT.
15 TITLE PIC X(10).
15 LAST-NAME PIC X(15).
15 FIRST-NAME PIC X(8).
05 ADDRESS PIC X(15).
05 CITY PIC X(15).
05 STATE PIC XX.
05 ZIP PIC 9(5).
-
Copybook definitions must always begin with a
01entry. A separate record type is generated for each01definition in your copybook (there must be at least one01definition for the copybook to be usable, so add one using an arbitrary name at the start of the copybook if none is present). If there are multiple01definitions in the copybook file, you can select which definition to use in the transform from the dropdown list. -
COBOL format requires definitions to only use columns 7-72 of each line. Data in columns 1-5 and past column 72 is ignored by the import process. Column 6 is a line continuation marker.
When you import the schema, the Transform component converts the copybook file
to a flat file schema that it stores in the src/main/resources/schema folder
of your Mule project. In flat file format, the copybook definition above looks
like this:
form: COPYBOOK
id: 'MAILING-RECORD'
values:
- { name: 'COMPANY-NAME', type: String, length: 30 }
- name: 'CONTACTS'
values:
- name: 'PRESIDENT'
values:
- { name: 'LAST-NAME', type: String, length: 15 }
- { name: 'FIRST-NAME', type: String, length: 8 }
- name: 'VP-MARKETING'
values:
- { name: 'LAST-NAME', type: String, length: 15 }
- { name: 'FIRST-NAME', type: String, length: 8 }
- name: 'ALTERNATE-CONTACT'
values:
- { name: 'TITLE', type: String, length: 10 }
- { name: 'LAST-NAME', type: String, length: 15 }
- { name: 'FIRST-NAME', type: String, length: 8 }
- { name: 'ADDRESS', type: String, length: 15 }
- { name: 'CITY', type: String, length: 15 }
- { name: 'STATE', type: String, length: 2 }
- { name: 'ZIP', type: Integer, length: 5, format: { justify: ZEROES, sign: UNSIGNED } }
After importing the copybook, you can use the schemaPath property to reference
the associated flat file through the output directive. For example:
output application/flatfile schemaPath="src/main/resources/schemas/mailing-record.ffd"
Supported Copybook Features
Not all copybook features are supported by the COBOL Copybook format in DataWeave. In general, the format supports most common usages and simple patterns, including:
-
USAGE of DISPLAY, BINARY (COMP), COMP-5 (Mule 3 support: Version 3.9.3 and later), and PACKED-DECIMAL (COMP-3). For character encoding restrictions, see Character Encodings.
-
PICTURE clauses for numeric values consisting only of:
-
'9' - One or more numeric character positions
-
'S' - One optional sign character position, leading or trailing
-
'V' - One optional decimal point
-
'P' - One or more decimal scaling positions
-
-
PICTURE clauses for alphanumeric values consisting only of 'X' character positions
-
Repetition counts for '9', 'P', and 'X' characters in PICTURE clauses (as in
9(5)for a 5-digit numeric value) -
OCCURS DEPENDING ON with controlVal property in schema. Note that if the control value is nested inside a containing structure, you need to manually modify the generated schema to specify the full path for the value in the form "container.value".
-
REDEFINES clause (used to provide different views of the same portion of record data). See REDEFINES Support. (Mule 3 support: Version 3.9.3 and later)
Unsupported features include:
-
Alphanumeric-edited PICTURE clauses
-
Numeric-edited PICTURE clauses, including all forms of insertion, replacement, and zero suppression
-
Special level-numbers:
-
Level 66 - Alternate name for field or group
-
Level 77 - Independent data item
-
Level 88 - Condition names (equivalent to an enumeration of values)
-
-
REDEFINES clause for Mule 3.9.2 and earlier
-
SIGN clause at group level (only supported on elementary items with PICTURE clause)
-
USAGE of COMP-1 or COMP-2 and of clause at group level (only supported on elementary items with PICTURE clause). For Mule 3.9.2 and earlier, COMP-5 is not supported.
-
VALUE clause (used to define a value of a data item or conditional name from a literal or another data item)
-
SYNC clause (used to align values within a record)
REDEFINES Support
Mule 3 support: Version 3.9.3 and later
REDEFINES facilitates dynamic interpretation of data in a record. When you import a copybook with REDEFINES present, the generated schema uses a special grouping with the name '*' (or '*1', '*2', and so on, if multiple REDEFINES groupings are present at the same level) to combine all the different interpretations. You use this special grouping name in your DataWeave expressions just as you use any other grouping name.
Use of REDEFINES groupings has higher overhead than normal copybook groupings, so MuleSoft recommends that you remove REDEFINES from your copybooks where possible before you import them into Studio.
Character Encodings
BINARY (COMP), COMP-5 (Mule 3 support: Version 3.9.3 and later), or PACKED-DECIMAL (COMP-3) usages are only supported with single-byte character encodings, which use the entire range of 256 potential character codes. UTF-8 and other variable-length encodings are not supported for these usages (because they’re not single-byte), and ASCII is also not supported (because it doesn’t use the entire range). Supported character encodings include ISO-8859-1 (an extension of ASCII to full 8 bits) and other 8859 variations and EBCDIC (IBM037).
REDEFINES (Mule 3 support: Version 3.9.3 and later) requires you to use a single-byte-per-character character encoding for the data, but any single-byte-per-character encoding can be used unless BINARY (COMP), COMP-5, or PACKED-DECIMAL (COMP-3) usages are included in the data.
Common Copybook Import Issues
The most common issue with copybook imports is a failure to follow the COBOL standard for input line regions. The copybook import parsing ignores the contents of columns 1-6 of each line, and ignores all lines with an '*' (asterisk) in column 7. It also ignores everything beyond column 72 in each line. This means that all your actual data definitions need to be within columns 8 through 72 of input lines.
Tabs in the input are not expanded because there is no defined standard for tab positions. Each tab character is treated as a single space character when counting copybook input columns.
Indentation is ignored when processing the copybook, with only level-numbers treated as significant. This is not normally a problem, but it means that copybooks might be accepted for import even though they are not accepted by COBOL compilers.
Both warnings and errors might be reported as a result of a copybook import. Warnings generally tell of unsupported or unrecognized features, which might or might not be significant. Errors are notifications of a problem that means the generated schema (if any) will not be a completely accurate representation of the copybook. You should review any warnings or errors reported and decide on the appropriate handling, which might be simply accepting the schema as generated, modifying the input copybook, or modifying the generated schema.
Reader Properties (for Copybook)
When you define an input of type Copybook, there are a few optional parameters you can add in the XML definition of your Mule project to customize how the data is parsed.
| Parameter | Type | Default | Description |
|---|---|---|---|
|
Boolean |
|
Error if required value missing.
Valid options: |
|
String |
|
Fill character used to represent missing values. To represent missing values in the input data, you can use:
|
|
String |
|
Expected separation between lines/records:
|
|
String |
None |
Schema definition. Location in your local disk of the schema file used to parse your input. |
|
String |
None |
Segment identifier in the schema for fixed width or copybook schemas (only needed when parsing a single segment/record definition and if the schema includes multiple segment definitions). |
|
String |
None |
Structure identifier in the schema for flat file schemas (only needed when parsing a structure definition, and if the schema includes multiple structure definitions). |
|
Boolean |
|
Truncate COBOL
copybook DEPENDING ON values to length used. Valid options: |
|
Boolean |
|
Use the |
Note that schemas with type Binary or Packed don’t allow for line break
detection, so setting recordParsing to lenient only allows long records
to be handled, not short ones. These schemas only work with
certain single-byte character encodings
(so not with UTF-8 or any multibyte format).
These properties can be either set via the XML of your Mule project:
<dw:input-payload mimeType="text/plain" >
<dw:reader-property name="schemaPath" value="myschema.ffs"/>
<dw:reader-property name="segmentIdent" value="structure1"/>
</dw:input-payload>Or via the UI of the Transform Message component
Schemas with type Binary or Packed don’t allow for line breaks to be detected, so setting recordParsing to "lenient"` will only allow long records to be handled, but not short ones. These schemas also currently only work with certain single-byte character encodings (so not with UTF-8 or any multibyte format).
|
Writer Properties (for Copybook)
When you define an output of type copybook, you can customize the way data is written by adding optional parameters to the output directive:
| Parameter | Type | Default | Description |
|---|---|---|---|
|
String |
None |
Encoding to be used by this writer,
such as |
|
Boolean |
|
Error if a required value is missing.
Valid options: |
|
String |
|
Fill character used to represent missing values:
|
|
String |
System property |
Record separator line break. Mule 3 support: Version 3.9.2 and later. Valid options:
Note that in Mule versions 4.0.4 and older, |
|
String |
None |
Schema definition. Path where the schema file to be used is located. |
|
String |
None |
Segment identifier in the schema for fixed width or copybook schemas (only needed when writing a single segment/record definition, and if the schema includes multiple segment definitions). |
|
String |
None |
Structure identifier in schema for flat file schemas (only needed when writing a structure definition and if the schema includes multiple structure definitions). |
|
Boolean |
|
Trim string values longer than the field
length by truncating trailing characters. Valid options: |
|
Boolean |
|
Truncate DEPENDING ON COBOL
copybook values to length used. Valid options: |
|
Boolean |
|
Use the |
%dw 1.0
%output text/plain schemaPath="src/main/resources/test-data/QBReqRsp.esl", structureIdent=“QBResponse"
---
payload|
See DataWeave Flat File or EDI Schemas for instructions and examples on how to create the required schema file. |
Defining a Metadata Type
In the Transform Message component, you can define a Fixed Width type through the following methods:
-
By pointing to a [flat file] schema file
| See Flat File Schemas for more detailed instructions on how to write the required schema. |