HL7 EDI Connector 4.0
HL7 EDI 用 Anypoint Connector (HL7 EDI Connector) を使用すると、リストとマップを使用して、HL7 ER7 メッセージを DataWeave 互換の表現との間で変換できます。
リリースノート: リリースノート
Exchange: HL7 EDI Connector
始める前に
このドキュメントは、読者が HL7、Mule、Anypoint Connector、Anypoint Studio、Mule フロー、Mule グローバル要素に精通していることを前提としています。
互換性情報については、リリースノートを参照してください。リリースノートへのリンクは、このドキュメントの「関連情報」セクションに含まれます。
本番環境で使用するには、HL7 EDI Connector のライセンスを購入する必要があります。
POM ファイル情報
<dependency>
<groupId>com.mulesoft.connectors</groupId>
<artifactId>mule-hl7-extension</artifactId>
<version>4.0.3</version>
<classifier>mule-plugin</classifier>
</dependency>バージョン 4.0.3 を使用しているバージョンに置き換えます。バージョンを指定するには、Anypoint Exchange を参照して [Dependency Snippets (連動関係スニペット)] をクリックします。
このコネクタの新機能
HL7 EDI Connector 4.0.0 で使用するデータ構造は、Mule 3.x で使用する 3.x バージョンのデータ構造とは異なります。
コネクタの 3.x バージョンでは、複合コンポーネントは使用時に効果的にインライン化されるため、複合コンポーネント内でネストされた個々の要素には、包含するセグメントに基づいてキーが与えられ、それらの要素は、セグメントを表すマップから直接参照されます。
コネクタの 4.x バージョンでは、各複合コンポーネントは代わりに子のマップによって表され、複合内の値には複合識別子に基づくキーが含まれます。
この構造の変更により、包含するセグメントまたはセグメント内の位置に関係なく、複合コンポーネント内のデータで一貫したマッピングを使用できます。
Studio プロジェクトへのコネクタの追加
Anypoint Studio には、Studio プロジェクトにコネクタを追加する 2 つの方法があります。 Studio タスクバーの Exchange ボタンから追加するか、[Mule Palette (Mule パレット)] ビューから追加します。
Exchange を使用してコネクタを追加する
-
Studio で Mule プロジェクトを作成します。
-
Studio タスクバーの左上にある Exchange アイコン (X) をクリックします。
-
Exchange で、[Login (ログイン)] をクリックし、Anypoint Platform のユーザー名とパスワードを指定します。
-
Exchange で、「HL7」を検索します。
-
コネクタを選択して [Add to project (プロジェクトに追加)] をクリックします。
-
画面の指示に従ってコネクタをインストールします。
Studio でコネクタに追加する
-
Studio で Mule プロジェクトを作成します。
-
[Mule Palette (Mule パレット)] ビューで、[(X) Search in Exchange ((X) Exchange 内を検索)] をクリックします。
-
[Add Modules to Project (モジュールをプロジェクトに追加)] で、検索項目に「HL7」と入力します。
-
[Available modules (使用可能なモジュール)] で、このコネクタの名前をクリックします。
-
[Add (追加)] をクリックします。
-
[Finish (完了)] をクリックします。
スキーマの作成
実装に従ってメッセージを記述するスキーマを作成します。
EDI スキーマ言語
HL7 EDI では、ESL (EDI スキーマ言語) と呼ばれる YAML 形式を使用して EDI スキーマを表します。 基本 ESL は、構造 (HL7 用語のメッセージ構造)、グループ、セグメント、複合、および要素の観点で ER7 メッセージの構造を定義します。HL7 の各バージョン (v2.1、v2.2、v2.3.1、v2.3、v2.4、v2.5、v2.5.1、v2.6、2.7、 2.7.1、2.8、2.8.1) の ESL には、2 つの異なる形式があります。
-
標準 HL7。上記の HL7 バージョンごとに必須または省略可能な状況、データ型、項目の長さ、反復数を使用します。
-
可変 HL7。すべてのセグメントおよび値の項目は省略可能で、低レベルのデータ型はすべて単純な文字列として処理され、項目の長さと反復数は強制されません。
コネクタで提供されるメッセージ構造のスキーマ定義の詳細は、HL7 スキーマリストを参照してください。
HL7 スキーマ定義をデータに合わせてカスタマイズするには、スキーマ定義を直接コピーして編集するか、コンソールツールを使用して 1 つ以上のサンプルドキュメントに基づいて簡単なスキーマを生成することができます。また、他の EDI 形式と同様に HL7 のオーバーレイスキーマを使用することもできますが、HL7 定義の複雑さのためこのオプションはお勧めできません。
また、独自のスキーマをゼロから定義することもできます。 詳細は、「EDI スキーマ言語リファレンス」を参照してください。
|
YAML では、リストとキー-値ペアのセットの組み合わせが使用されます。必須項目が存在する場合、値の順序は重要ではありません。数字で構成される可能性があっても文字列として解釈するように意図される値は、引用符 (単一引用符または二重引用符) で囲みます (そうしないと、YAML パーサーは値を数値として処理するため)。インデントを使用して、リストのネストを示します。 読みやすくすることを目的として、ここで示している ESL 構造では、同じ定義の一部であるリストの前に、すべての簡単なキー-値ペアを定義しています。 |
スキーマ定義のコピーと編集
HL7 スキーマ定義は hl7-schemas-4.0.0.jar 内で配布されます。これは、HL7 EDI Connector 更新サイト内に組み込まれているか、標準の MuleSoft Enterprise Maven リポジトリ (グループ ID の com.mulesoft.connectors の下) にもあります。この JAR ファイルからメッセージ構造スキーマをコピーして、特定のニーズに合わせて編集できます。
セグメントレベルでの変更のみが必要な場合は、メッセージ構造スキーマをコピーするだけで済みます。セグメント定義の変更が必要な場合は、同じバージョンの basedefs.esl スキーマもコピーする必要があります。このファイルにセグメント、複合、および要素の定義が含まれるためです。
「EDI スキーマ言語リファレンス」では、HL7 EDI Connector を含め、すべての EDI Connector で使用される ESL スキーマ構造の概要が説明されています。 スキーマ定義の構造については、このドキュメントを参照してください。
標準の v2.5.1 ADT_A05 メッセージ構造の HL7 メッセージ構造スキーマの例を次に示します。
form: HL7
version: '2.5.1'
imports: [ '/hl7/v2_5_1/basedefs.esl' ]
id: 'ADT_A05'
name: 'ADT_A05'
data:
- { idRef: 'MSH', position: '01', usage: M }
- { idRef: 'SFT', position: '02', usage: O, count: '>1' }
- { idRef: 'EVN', position: '03', usage: M }
- { idRef: 'PID', position: '04', usage: M }
- { idRef: 'PD1', position: '05', usage: O }
- { idRef: 'ROL', position: '06', usage: O, count: '>1' }
- { idRef: 'NK1', position: '07', usage: O, count: '>1' }
- { idRef: 'PV1', position: '08', usage: M }
- { idRef: 'PV2', position: '09', usage: O }
- { idRef: 'ROL', position: '10', usage: O, count: '>1' }
- { idRef: 'DB1', position: '11', usage: O, count: '>1' }
- { idRef: 'OBX', position: '12', usage: O, count: '>1' }
- { idRef: 'AL1', position: '13', usage: O, count: '>1' }
- { idRef: 'DG1', position: '14', usage: O, count: '>1' }
- { idRef: 'DRG', position: '15', usage: O }
- groupId: 'PROCEDURE'
count: '>1'
usage: O
items:
- { idRef: 'PR1', position: '17', usage: M }
- { idRef: 'ROL', position: '18', usage: O, count: '>1' }
- { idRef: 'GT1', position: '20', usage: O, count: '>1' }
- groupId: 'INSURANCE'
count: '>1'
usage: O
items:
- { idRef: 'IN1', position: '22', usage: M }
- { idRef: 'IN2', position: '23', usage: O }
- { idRef: 'IN3', position: '24', usage: O, count: '>1' }
- { idRef: 'ROL', position: '25', usage: O, count: '>1' }
- { idRef: 'ACC', position: '27', usage: O }
- { idRef: 'UB1', position: '28', usage: O }
- { idRef: 'UB2', position: '29', usage: O }これは、セグメントグループ PROCEDURE および INSURANCE を含む ADT_A05 メッセージ構造を構成するセグメントのリストを示しています。この例は標準定義 (可変バージョンではない) のため、必須のセグメント (usage: M) および省略可能なセグメント (usage: O) が含まれます。次に、HL7 で使用される使用方法コードのフルセットを示します。
-
C: 条件付き (省略可能と同等) -
M: 必須 -
O: 省略可能 -
U: 未使用 (読み取り時に警告なしで受け入れるが、読み取りから渡されるデータには存在せず、書き込み時には無視される)
セグメントまたはグループの出現可能な数は count の値によって提供されます。デフォルトでは、この値は 1 に設定されます。
メッセージ構造からセグメントを削除する場合や、セグメント要件を必須から省略可能 (またはその逆) に変更する場合は、スキーマのコピーに変更を加えて、その変更バージョンをアプリケーションで容易に使用できます。
元のメッセージ構造定義に含まれないセグメントを追加することもできます。このためには、まず、位置の値をスキーマ内の既存のすべてのセグメント定義行およびグループ定義行から削除する必要があります。これを行わない場合、追加したセグメント以降のすべてを採番し直す必要があります。 明示的な位置番号を削除した場合、セグメントとグループに位置番号が順次割り当てられます。また、ほとんどの用途で、HL7 EDI Connector アプリケーションはこの番号を参照しません。
標準 HL7 セグメントをメッセージ構造に追加するには、適切な場所の idRef 行でそのセグメントを参照します。HL7 はインポート時に参照される basedefs.esl ファイルから定義を取得します。
次の部分的な例は、ADT_A05 メッセージ構造に追加された CON セグメントを示しています。
form: HL7
version: '2.5.1'
imports: [ '/hl7/v2_5_1/basedefs.esl' ]
id: 'ADT_A05'
name: 'ADT_A05'
data:
- { idRef: 'MSH', usage: M }
- { idRef: 'SFT', usage: O, count: '>1' }
- { idRef: 'EVN', usage: M }
- { idRef: 'PID', usage: M }
- { idRef: 'PD1', usage: O }
- { idRef: 'CON', usage: O, count: '>1' }
- { idRef: 'NTE', usage: O }
- { idRef: 'ROL', usage: O, count: '>1' }
- { idRef: 'NK1', usage: O, count: '>1' }
- { idRef: 'PV1', usage: M }
- { idRef: 'PV2', usage: O }
- { idRef: 'CON', usage: O, count: '>1' }
- { idRef: 'ROL', usage: O, count: '>1' }
...メッセージ構造で標準以外のセグメントを定義する場合、セグメント定義をスキーマに追加します。この場合、セグメント内のすべてのコンポーネントをリストする必要があるため、単にセグメント構造を変更するよりも複雑です。これを最も簡単に開始する方法は、似た標準 HL7 セグメントを見つけて、その標準セグメントで使用されている定義を basedefs.esl ファイルからコピーすることです。次に、メッセージ構造定義の後にセグメントキーを追加し、その後に 1 つ以上のセグメント定義を追加します。
サンプルメッセージを使用したスキーマの簡略化
HL7 標準定義は非常に複雑です。多くの場合、セグメントには 20 個以上のコンポーネントと多くのコンポーネント複合が含まれ、さらにそれら自体が多くのサブコンポーネントに分割されています。メッセージの DataSense ビューにはこのすべてのサブコンポーネントを含める必要があるため、これにより HL7 のマッピングが困難になる可能性があります。
実際には、HL7 のほとんどのユーザーは HL7 標準定義全体のごくわずかな部分のみを入力しています。この方法を利用するには、HL7 EDI Connector が提供するコンソールベースの Java ツールを使用し、メッセージで通常使用されないコンポーネントを除外して、スキーマ定義を簡素化することができます。
このスキーマ簡素化ツールは hl7-simplify-4.0.0.jar として配布されます。これは、標準の MuleSoft Enterprise Maven リポジトリ (グループ ID の com.mulesoft.connectors の下) にあります。
これは、入力としてメッセージ構造スキーマと 1 つ以上のサンプルメッセージ (別々のファイル) を取得し、1 つ以上のサンプルメッセージに含まれるセグメントとコンポーネントのみに縮小される出力スキーマを生成します。
このツールを使用するには、JAR をダウンロードし、コマンドラインコンソールを開いて次のように入力します。
java -jar hl7-simplify-4.0.0.jar {input-schema} {output-schema} {sample1} {sample2} ...各項目は次のとおりです。
-
input-schema は、メッセージを読み取るために使用されるメッセージ構造スキーマで、ファイルまたは提供されるスキーマへのクラスパス参照になります (例:/hl7/v2_5_1/ADT_A05.esl パス)。 -
output-schema は、簡略化されたスキーマ出力のファイルパスです。 -
sample1…n は、サンプルメッセージへのファイルパスです。
保存されているサンプルメッセージファイルの行末が行頭復帰 (CR) になっていることを確認します (これが HL7 セグメントの必須の区切り文字であるため)。通常、テキストエディターではオペレーティングシステムのデフォルトの行末が使用されますが、この行末は適切ではない可能性があります。
次に、このツールを使用して生成された簡略化されたスキーマの部分的な例を示します。
form: HL7
version: '2.5.1'
structures:
- id: 'SIU_S12'
name: 'SIU_S12'
data:
- { idRef: 'MSH', position: '01', usage: O }
- { idRef: 'SCH', position: '02', usage: O }
- groupId: 'PATIENT'
count: '>1'
usage: O
items:
- { idRef: 'PID', position: '06', usage: O }
- { idRef: 'PV1', position: '08', usage: O }
- groupId: 'RESOURCES'
count: '>1'
usage: O
items:
- { idRef: 'RGS', position: '14', usage: O }
- groupId: 'SERVICE'
count: '>1'
usage: O
items:
- { idRef: 'AIS', position: '16', usage: O }
- groupId: 'GENERAL_RESOURCE'
count: '>1'
usage: O
items:
- { idRef: 'AIG', position: '20', usage: O }
- groupId: 'LOCATION_RESOURCE'
count: '>1'
usage: O
items:
- { idRef: 'AIL', position: '24', usage: O }
- groupId: 'PERSONNEL_RESOURCE'
count: '>1'
usage: O
items:
- { idRef: 'AIP', position: '28', usage: O }
segments:
- id: 'AIG'
name: 'Appointment Information - General Resource'
varTag: 'AIG'
values:
- { idRef: 'SI', name: 'Set ID - AIG', usage: O }
- { idRef: 'varies', name: 'Segment Action Code', usage: U, count: '>1' }
- { idRef: 'CE_2', name: 'Resource ID', usage: O }
- { idRef: 'varies', name: 'Resource Type', usage: U, count: '>1' }
- { idRef: 'varies', name: 'Resource Group', usage: U, count: '>1' }
- { idRef: 'varies', name: 'Resource Quantity', usage: U, count: '>1' }
- { idRef: 'varies', name: 'Resource Quantity Units', usage: U, count: '>1' }
- { idRef: 'TS', name: 'Start Date/Time', usage: O }
- id: 'AIL'
name: 'Appointment Information - Location Resource'
varTag: 'AIL'
values:
- { idRef: 'SI', name: 'Set ID - AIL', usage: O }
- { idRef: 'varies', name: 'Segment Action Code', usage: U, count: '>1' }
- { idRef: 'PL', name: 'Location Resource ID', usage: O, count: '>1' }
- { idRef: 'CE', name: 'Location Type-AIL', usage: O }
- { idRef: 'varies', name: 'Location Group', usage: U, count: '>1' }
- { idRef: 'TS', name: 'Start Date/Time', usage: O }
- id: 'AIP'
name: 'Appointment Information - Personnel Resource'
varTag: 'AIP'
values:
- { idRef: 'SI', name: 'Set ID - AIP', usage: O }
- { idRef: 'varies', name: 'Segment Action Code', usage: U, count: '>1' }
- { idRef: 'XCN_2', name: 'Personnel Resource ID', usage: O, count: '>1' }
- { idRef: 'CE_1', name: 'Resource Type', usage: O }
- { idRef: 'varies', name: 'Resource Group', usage: U, count: '>1' }
- { idRef: 'TS', name: 'Start Date/Time', usage: O }
...
composites:
- id: 'CE'
name: 'Coded Element'
values:
- { idRef: 'ST', name: 'Identifier', usage: O }
- { idRef: 'ST', name: 'Text', usage: O }
- id: 'CE_1'
name: 'Coded Element'
values:
- { idRef: 'ST', name: 'Identifier', usage: O }
- id: 'CE_2'
name: 'Coded Element'
values:
- { idRef: 'ST', name: 'Identifier', usage: O }
- { idRef: 'ST', name: 'Text', usage: O }
- { idRef: 'ID', name: 'Name of Coding System', usage: O }
...セグメントの未使用のコンポーネントをセグメント定義から単に削除することはできません (ただし、そのコンポーネントがセグメントの末尾にある場合を除く)。そのため、簡素化ツールでは、そのコンポーネントを varies データ型で置換し、Usage: U (未使用) としてマークします。この場合、varies は元のコンポーネントと同じ回数反復されますが、DataWeave に表示されるデータの DataSense ビューには表示されません。
スキーマ簡素化ツールは、メッセージに含まれるデータを確認するときに、コンテキスト内の複合の各出現箇所を処理します。同じ複合でも使用方法が異なると、サンプルに異なる値が含まれる可能性があります。この場合、複合は異なる識別子で複数回定義されます。 上記の例の CE 複合は、これを示しています。
簡素化されたスキーマでは、元のスキーマのセグメント位置が保持されます。 セグメントキー (コネクタ設定オプションの 1 つ) で位置プレフィックスを使用しない限り、この位置の値は HL7 EDI Connector では使用されないため、簡素化されたスキーマから必要に応じてこの位置の値を削除できます。
HL7 スキーマの場所の確認
コネクタを使用するには、プロジェクト内のスキーマの場所を認識しておく必要があります。標準の HL7 スキーマを使用し、何もカスタマイズしていない場合、標準スキーマの場所は /hl7/{version}/{message structure}.esl のパターンに従い、可変スキーマの場所は /hl7lax/{version}/{message structure}.esl のパターンに従います。
たとえば、2.5.1 バージョンおよび ADT_A01 メッセージ構造を使用している場合、標準バージョン (必須の値、データ型、長さ/反復数を含む) のスキーマの場所は /hl7/v2_5_1/ADT_A01.esl、可変バージョンのスキーマの場所は /hl7lax/v2_5_1/ADT_A01.esl になります。
1 つ以上のカスタムスキーマを使用している場合、それらを src/main/mule 内のディレクトリの下に配置し、${app.home} を使用して場所を参照する必要があります。
たとえば、ADT_A01 スキーマを src/main/mule/mypartner/ADT_A01.esl に配置した場合、スキーマの場所は ${app.home}/mypartner/ADT_A01.esl になります。
Mule Runtime Engine は自動的に src/main/mule を参照し、${app.home} 値を含む場所があるかどうかを確認します。
イベントおよびメッセージとメッセージ構造のマップ
(提供されているスキーマのように別々のスキーマ定義内か、1 つのファイル内かに関係なく) 複数のメッセージ構造スキーマを使用してコネクタを設定する場合、HL7 のイベントおよびメッセージ種別からメッセージ構造へのマッピングの定義が必要になる場合があります。
HL7 は、MSG 種別の複合構造である MSH-09 のコンポーネント値でメッセージ種別を定義します。HL7 EDI Connector は、このコンポーネント値を使用して、以下のルールに従って、受信メッセージの処理に使用する構造スキーマを見つけます。
-
MSG-01 メッセージコードの値が
ACK の場合、定義済みの ACK スキーマを常に使用します。 -
MSG-03 メッセージ構造の値 (ADT_A01 などの値) が存在する場合、その ID のスキーマ構造を使用します。
-
それ以外の場合、イベントおよびメッセージからメッセージ構造への設定済みのマップを使用して、指定されたトリガーイベント (MSG-02) およびメッセージコード (MSG-01) の値からメッセージ構造を特定します。
[Event and Message to Message Structure Map (イベントおよびメッセージとメッセージ構造のマップ)] は、省略可能な設定パラメーターです。 これは、サポートされる各メッセージコードから実際のメッセージ構造へのマップに対する各イベント種別からのマップで構成される YAML ファイルである必要があります。
このサンプルは次のようになります。
A01: { XYZ: ADT_A01, ACK: ACK }
A02: { XYZ: ADT_A02, ACK: ACK }
A03: { XYZ: ADT_A03, ACK: ACK }
A04: { XYZ: ADT_A01, ACK: ACK }
A05: { XYZ: ADT_A05, ACK: ACK }
A06: { XYZ: ADT_A06, ACK: ACK }
A07: { XYZ: ADT_A06, ACK: ACK }
A08: { XYZ: ADT_A01, ACK: ACK }HL7 のバージョンごとに、イベント種別およびメッセージコードからメッセージ構造への異なるマッピングセットを定義します。デフォルトのマッピングは、標準 HL7 スキーマ定義と同じ JAR 内の event-message.yaml という名前のファイルで提供されます。
これらのマッピング定義には、実際のメッセージ構造スキーマと同じパス種別を使用します。
Anypoint Studio 7 で Mule プロジェクトを作成する
コネクタをインストールし、(必要に応じて) スキーマをカスタマイズしたら、コネクタの使用を開始できます。実装規定ごとに個別の設定を作成します。
-
キャンバスの下部にある [Global Elements (グローバル要素)] タブをクリックし、[Create (作成)] をクリックします。
-
[Choose Global Type (グローバル種別の選択)] ウィザードで、検索条件を使用して [HL7 EDI: Configuration (HL7 EDI: 設定)] を見つけて選択し、[OK] をクリックします。
-
[OK] をクリックして、グローバルコネクタ設定を保存します。
-
Studio の [Message Flow (メッセージフロー)] タブに戻ります。
General Options (一般オプション)
[general options (一般オプション)] では、HL7 メッセージの読み取りと書き込みの両方に適用される設定を定義できます。
-
HL7 character encoding (HL7 文字エンコード) - メッセージの書き込みでは常に使用され、メッセージの読み取りでは MSH-18 (文字セット) で別のエンコードが指定されていない場合に使用されます。
-
Disable numeric prefixes for data keys (データキーの数値プレフィックスを無効化) - このオプションはデフォルトで true になっています。true では、セグメントデータの数値プレフィックスが無効になります。HL7 EDI Connector 3.0.0 で定義されたマッピングとの互換性を確保する場合にのみこのオプションを無効にします。
-
Manually create or edit the list of schemas (スキーマのリストを手動で作成または編集)。
ビジュアルエディターでの HL7 ID の設定
独自のメッセージヘッダー (MSH) アプリケーションと施設 ID、および取引パートナーを HL7 EDI Connector 設定で指定できます。
HL7 メッセージを書き込むときに、設定した値を使用して名前空間 ID、ユニバーサル ID、およびユニバーサル ID 種別を提供します。設定した値は受信メッセージ内で検証されます。受信メッセージを制限しない場合、これを空白のままにして、書き込み操作時に送信メッセージの値を設定するか、実際の送信メッセージの値を設定します。書き込み操作時に設定された値は、コネクタ設定を上書きし、メッセージに直接設定された値は、コネクタ設定と書き込み操作時に設定されたすべての値を上書きします。
Studio ではこの値は [Global Element Properties (グローバル要素のプロパティ)] で設定されます。
-
自分の ID パラメーターは、取引パートナーリレーションの自分側を識別します。
自分の ID 設定:
Mule Application Namespace ID (MSH-03/HD-01 when sending, MSH-05/HD-01 when receiving) Mule Application Universal ID (MSH-03/HD-02 when sending, MSH-05/HD-02 when receiving) Mule Application Universal ID Type (MSH-03/HD-03 when sending, MSH-05/HD-03 when receiving) -
パートナーの ID パラメーターは、取引パートナーを識別します。
パートナーの ID 設定:
Partner Application Namespace ID (MSH-03/HD-01 when receiving, MSH-05/HD-01 when sending) Partner Application Universal ID (MSH-03/HD-02 when receiving, MSH-05/HD-02 when sending) Partner Application Universal ID Type (MSH-03/HD-03 when receiving, MSH-05/HD-03 when sending)
パーサーオプションの設定
必要に応じて、次のオプションを設定できます。
-
HL7 メッセージバージョンを検証する。
-
イベントおよびメッセージからメッセージ構造へのマッピングパス (受信したメッセージに MSH-09 および MSG-03 メッセージ構造値が常に含まれていない限り、複数のメッセージ構造を使用する場合、必須)。
-
必須の処理 ID (本番の
P など、受信メッセージで必要とされる特定の処理 ID を指定)。 -
汎用の拡張セグメント名のパターン (項目値のマップとして拡張セグメントを処理できる)。
-
必須値がない場合に失敗する。
-
値の長さが許容範囲を超える場合に失敗する。
-
無効な文字が値に含まれる場合に失敗する。
-
値の反復が多すぎる場合に失敗する。
-
不明なセグメントがメッセージに含まれる場合に失敗する。
-
メッセージ内のセグメントの順序が不適切な場合に失敗する。
-
未使用のセグメントがメッセージに含まれる場合に失敗する。
-
セグメントの反復が多すぎる場合に失敗する。
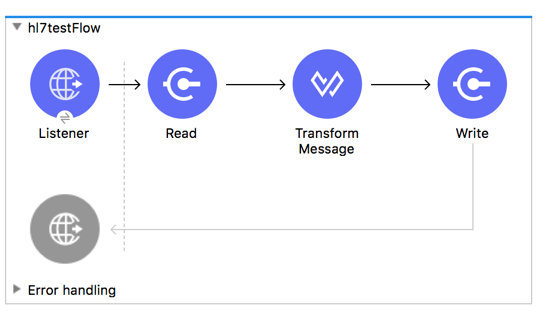
例: HL7 Studio
以下の XML から次のフローを読み込むことができます。
<?xml version="1.0" encoding="UTF-8"?>
<mule xmlns:ee="http://www.mulesoft.org/schema/mule/ee/core"
xmlns:hl7="http://www.mulesoft.org/schema/mule/hl7"
xmlns:http="http://www.mulesoft.org/schema/mule/http"
xmlns="http://www.mulesoft.org/schema/mule/core"
xmlns:doc="http://www.mulesoft.org/schema/mule/documentation"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://www.mulesoft.org/schema/mule/core
http://www.mulesoft.org/schema/mule/core/current/mule.xsd
http://www.mulesoft.org/schema/mule/http
http://www.mulesoft.org/schema/mule/http/current/mule-http.xsd
http://www.mulesoft.org/schema/mule/hl7
http://www.mulesoft.org/schema/mule/hl7/current/mule-hl7.xsd
http://www.mulesoft.org/schema/mule/ee/core
http://www.mulesoft.org/schema/mule/ee/core/current/mule-ee.xsd">
<http:listener-config name="HTTP_Listener_config"
doc:name="HTTP Listener config" >
<http:listener-connection host="localhost" port="8081" />
</http:listener-config>
<hl7:config name="HL7_Extension_Config" doc:name="HL7 Extension Config" identKeys="true">
<hl7:schemas >
<hl7:schema value="/hl7/v2_5_1/ADT_A05.esl" />
<hl7:schema value="/hl7/v2_5_1/ADT_A01.esl" />
</hl7:schemas>
</hl7:config>
<flow name="hl7testFlow" >
<http:listener doc:name="Listener" config-ref="HTTP_Listener_config" path="/hl7"/>
<hl7:read doc:name="Read" config-ref="HL7_Extension_Config"/>
<ee:transform doc:name="Transform Message" >
<ee:message >
<ee:set-payload ><![CDATA[%dw 2.0
output application/java
---
{
Delimiters: payload.Delimiters,
Id: payload.Id
}]]></ee:set-payload>
</ee:message>
</ee:transform>
<hl7:write doc:name="Write" config-ref="HL7_Extension_Config"/>
</flow>
</mule>XML での HL7 ID の設定
独自のメッセージヘッダー (MSH) アプリケーションと施設 ID、および取引パートナーを HL7 EDI Connector 設定で指定できます。
HL7 メッセージを書き込むときに、設定した値を使用して名前空間 ID、ユニバーサル ID、およびユニバーサル ID 種別を提供します。設定した値は受信メッセージ内で検証されます。受信メッセージを制限しない場合、これを空白のままにして、書き込み操作時に送信メッセージの値を設定するか、実際の送信メッセージの値を設定します。書き込み操作時に設定された値は、コネクタ設定を上書きし、メッセージに直接設定された値は、コネクタ設定と書き込み操作時に設定されたすべての値を上書きします。
-
自分の ID パラメーターは、取引パートナーリレーションの自分側を識別します。
自分の ID パラメーター:
appNamespaceIdSelf="<value>" appUniversalIdSelf="<value>" appUniversalIdTypeSelf="<value>" -
パートナーの ID パラメーターは、取引パートナーを識別します。
パートナーの ID パラメーター:
appNamespaceIdPartner="<value>" appUniversalIdPartner="<value>" appUniversalIdTypePartner="<value>"
パーサーオプションの設定
必要に応じて、次のオプションを設定できます。
| XML 値 | Visual Studio オプション |
|---|---|
eventMessageMap="/hl7/v2_5_1/event-message.yaml" |
イベントおよびメッセージからメッセージ構造へのマッピングパス (受信したメッセージに MSH-09 および MSG-03 メッセージ構造値が常に含まれていない限り、複数のメッセージ構造を使用する場合、必須)。 |
genericExtensionPattern="Z.." |
汎用の拡張セグメント名の Java 正規パターン (項目値のマップとして拡張セグメントを処理できる)。 |
invalidCharacterInValueFail="true" |
無効な文字が値に含まれる場合に失敗する。 |
missingRequiredValueFail="true" |
必須値がない場合に失敗する。 |
processingId="PRODUCTION" |
必須の処理 ID (本番の |
segmentOutOfOrderFail="true" |
メッセージ内のセグメントの順序が不適切な場合に失敗する。 |
unknownSegmentFail="true" |
不明なセグメントがメッセージに含まれる場合に失敗する。 |
unusedSegmentPresentFail="true" |
未使用のセグメントがメッセージに含まれる場合に失敗する。 |
validateHL7Version="true" |
HL7 メッセージバージョンを検証する。 |
valueLengthErrorFail="true" |
値の長さが許容範囲を超える場合に失敗する。 |
wrongSegmentsRepeatsFail="true" |
セグメントの反復が多すぎる場合に失敗する。 |
wrongValuesRepeatsFail="true" |
値の反復が多すぎる場合に失敗する。 |
スキーマの場所の設定
Anypoint Studio XML ビューでスキーマの場所を設定できます。
Anypoint Studio で、[Configuration XML (設定 XML)] をクリックして XML ビューに切り替え、含めるすべてのスキーマのリストが含まれるように、ドキュメント種別ごとに < http://edischema[edi:schema]> 要素を追加して HL7 EDI 設定を変更します。
<hl7-edi:config name="HL7_EDI__Configuration" identKeys="true" doc:name="HL7 EDI: Configuration">
<hl7-edi:schemas>
<hl7-edi:schema>hl7/v2_6/ADT_A01.esl</hl7-edi:schema>
</hl7-edi:schemas>
</hl7-edi:config>HL7 EDI のグローバル要素を作成したら、メッセージ構造、操作、肯定応答を設定します。
HL7 メッセージ構造
HL7 Connector は、正規の ER7 メッセージ構造から HL7 ドキュメントを読み込んだり、正規の ER7 メッセージ構造に HL7 ドキュメントを書き込んだりします。この構造は、DataWeave またはコードを使用して操作できる Java マップおよびリストの階層として表されます。トランザクションごとに、スキーマで定義される独自の構造があります。
HL7 メッセージには、次のキーがあります。
| キー名 | 説明 |
|---|---|
ACK (参照のみ) |
入力データに応答して生成された ACK メッセージ。MSA-01 肯定応答コード値は、パーサー設定に基づきます。肯定応答を送信するには、「肯定応答の送信」セクションを参照してください。 |
Data (参照/更新) |
実際のデータにリンクするメッセージ構造 ID 値に一致するキーを持つメッセージデータのラッパー。これにより、異なるメッセージをメタデータに含めて DataWeave マッピングで処理できます。 |
Delimiters (参照/更新) |
メッセージで使用する区切り文字。文字列内の文字は位置に基づいて次の順序で解釈されます。(コンポーネントの区切り文字)、(反復の区切り文字)、(エスケープ文字)、(サブコンポーネントの区切り文字)。 |
Errors (参照のみ) |
入力メッセージに関連付けられたエラーのリスト。HL7 メッセージの読み取りと検証に関する以下のセクションの HL7Error 構造の説明を参照してください。 |
Id |
メッセージ構造 ID。 |
MSH (参照のみ) |
受信した MSH セグメントデータへのリンク。 |
Name (参照のみ) |
メッセージ構造名。 |
個々のメッセージには、メッセージのセグメントに一致するキーを持つ独自のマップがあります。たとえば、ACK メッセージでメッセージ構造 ID の ACK を使用すると、送信または受信された ACK メッセージのデータは、データマップに ACK 値として含まれます。ACK メッセージ自体はマップです。メッセージのセグメントおよびグループは、位置キーを持つマップ (シングルトンインスタンスの場合) またはマップのリスト (反復インスタンスの場合) として表されます。
スキーマ定義に含まれないデータで汎用処理が使用される特殊なケースは 2 つあります。1 つ目は、HL7 値が varies 型のケースです。これらの値は、コンポーネントとサブコンポーネントの任意の構造で構成されたり、反復されたりする可能性があるため、パーサーは各 varies 型のマップ表現のリストを使用します。各マップのキーは、値の解析時に生成されます。このキーは、各ネストレベルで使用される 2 桁の数値を伴う標準 HL7 値の名前と一致します。
そのため、たとえば、OBX-05 検査値の単純なテキスト値では、マップでキー OBX-05 が使用されます。2 つのコンポーネントが存在する場合は、キー OBX-05-01 と OBX-05-02 が使用されます。
パーサーオプションで設定されたパターンに一致するタグを持つ拡張セグメントは、セグメント全体の 1 つのマップ内にのみあるという点を除き、varies 値と同じような構造です。
拡張セグメントデータを含むマップは、キー ExtensionSegs を持つリスト内の基本メッセージマップに追加されます。拡張セグメントのマップには、実際の拡張セグメントデータの他に 2 つのキーが含まれます。
| キー | 説明 |
|---|---|
Ident |
拡張セグメント ID (タグ)。 |
Position |
メッセージ構造内のセグメントの位置 (2 桁文字列)。これは、スキーマで定義されている、直前に定義されたセグメントの位置と同じです。ZVN 拡張セグメントが ADT_A01 メッセージ構造の EVN セグメントの後に使用される場合、ZVN の位置は 03) になります。 |
ネストされたグループで拡張セグメントが使用されている場合、それらのセグメントを格納するリストは、そのグループを表すマップに含まれます。拡張セグメントは、パーサーによって作成されたリストの位置で並び替えられますが、書き込み時の位置でも並び替えられます。
肯定応答の送信
ACK (肯定応答) メッセージは、メッセージをアプリケーションで受信したことをメッセージ送信者に肯定応答できる HL7 メッセージです。ACK メッセージは、read 操作時に生成されたデータを出力メッセージとして Data キーで ACK メッセージに設定する点を除き、他の HL7 メッセージの書き込みと同じです。
次に例を示します。
<hl7-edi:read config-ref="HL7_EDI__Configuration1" doc:name="HL7 EDI"/>\
...
<dw:transform-message doc:name="Create Outgoing Message">
<dw:set-payload><![CDATA[%dw 1.0
%output application/java
---
{
Name: "ACK",
MSH: payload.ACK.MSH,
Id: "ACK",
Data: {
ACK: payload.ACK
}
}]]></dw:set-payload>
</dw:transform-message>
<hl7-edi:write config-ref="HL7_EDI__Configuration" messageStructure="InMessage" doc:name="ACK"/>
...
<file:outbound-endpoint responseTimeout="10000" doc:name="File" path="output" outputPattern="ack.edi"/>生成された ACK メッセージには、元のメッセージの送信者に送り返すようにセットアップされた MSH データが含まれるため、送信を実行するためにデータを変更する必要はありません。
ACK メッセージスキーマを設定に含める場合、そのスキーマは ACK メッセージの受信と生成の両方で使用されます。ACK スキーマを指定しない場合、デフォルトでは標準 hl7/v2_5_1/ACK.esl スキーマが使用されます。
HL7 ER7 メッセージの読み取りおよび検証
HL7 メッセージを読み取り方法は、次のとおりです。
-
パレットで HL7 EDI を検索し、HL7 EDI 構成要素をフローにドラッグします。
-
プロパティビューから、以前に作成したコネクタ設定を選択して、
Read 操作を選択します。この操作は、HL7 スキーマで記述された構造にバイトストリームを読み取ります。
HL7 EDI は、読み取り時にメッセージ構造を検証します。 メッセージの検証には、MSH の構文やコンテンツ、およびメッセージのすべてのコンポーネントセグメントのチェックが含まれます。 通常、エラーは記録および累積されて、生成された ACK メッセージでレポートされます。このメッセージは、生成されたデータ構造で提供されます。 エラーがなくても、致命的でないエラーがあっても、すべてのメッセージは出力メッセージマップの一部として渡されて処理されます。 入力データの読み取りでエラーになると、例外がスローされる可能性があります。
受信データマップで入力されるエラーデータでは、HL7Error クラスの参照のみ JavaBean が使用されます。これには、次のプロパティがあります。
| プロパティ | 説明 |
|---|---|
|
エラーの原因となったセグメントの入力内の開始値 0 のインデックス。 |
|
エラーの結果として、関連付けられているメッセージが拒否されたことを意味する致命的なエラーのフラグ。 |
|
HL7 標準 (ERR-3 値) で定義されているさまざまなエラー種別の列挙。 |
|
指定されたエラー種別の HL7 標準で定義されているエラーコード。 |
|
エラーの説明 |
Read 演算子は、Errors キーを使用して省略可能なリストとしてエラーデータを返します。