Mule Runtime 高可用性 (HA) クラスターの概要
|
このバージョンの Mule は、拡張サポートが終了する 2023 年 5 月 2 日にその すべてのサポートが終了しました。 このバージョンの Mule を使用する CloudHub には新しいアプリケーションをデプロイできなくなります。許可されるのはアプリケーションへのインプレース更新のみになります。 標準サポートが適用されている最新バージョンの Mule 4 にアップグレードすることをお勧めします。これにより、最新の修正とセキュリティ機能強化を備えたアプリケーションが実行されます。 |
| CloudHub でのクラスタリングの場合、アプリケーションを拡大し、高可用性を提供するためにワーカーを共有または二重化する方法の詳細は、「クラスタリング」を参照してください。 |
Mule Enterprise Edition は拡張可能なクラスタリングをサポートし、アプリケーションの高可用性 (HA) を実現しています。
クラスターとは、ユニットとして機能する Mule Runtime Engine のセットです。言い換えると、クラスターとは複数のノード (Mule Runtime Engine) で構成された仮想サーバーです。クラスター内のノードは分散された共有メモリグリッドを通じて通信を行い、情報を共有します。つまり、データがさまざまなマシンのメモリ間で複製されます。
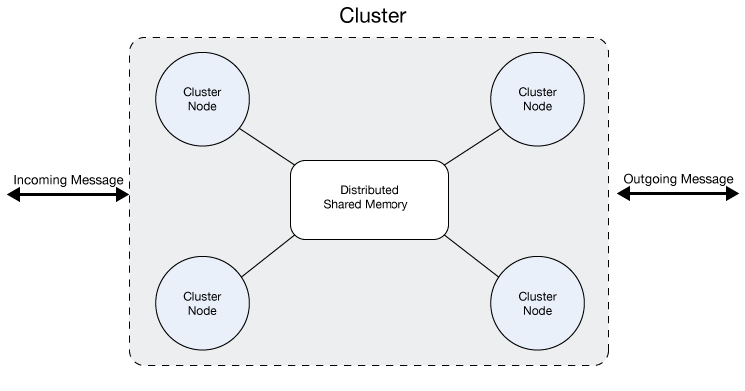
| この機能の価格については、カスタマーサービス担当者にお問い合わせください。 |
クラスタリングの利点
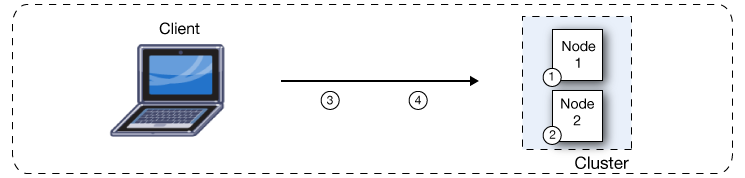
デフォルトでは、Mule Runtime Engine のクラスタリングにより、システムの高可用性を実現できます。障害や計画的なダウンタイムが原因で Mule Runtime Engine ノードが使用不可になった場合、クラスター内の別のノードがワークロードを引き継ぎ、既存のイベントおよびメッセージの処理を続行できます。次の図は、2 ノードのクラスターによる受信メッセージの処理を示しています。処理負荷がノード間で分散されているのがわかります。ノード 1 がメッセージ 1 を処理するのと同時に、ノード 2 はメッセージ 2 を処理します。
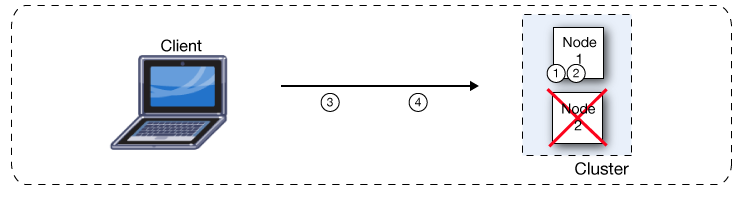
一方のノードで障害が発生した場合、もう一方の障害の発生していないノードが障害の発生しているノードの作業を引き継ぎます。次の図で示しているように、ノード 2 で障害が発生した場合、ノード 1 はメッセージ 1 とメッセージ 2 の両方を処理します。
Mule Runtime Engine のクラスターではすべてのノードが同時にメッセージを処理するため、クラスターによってパフォーマンスおよび拡張性も向上します。単一ノードのインスタンスと比較すると、クラスターのほうがサポートできるユーザーも多く、ワークロードを複数のノードで共有するかノードをクラスターに追加することで、アプリケーションのパフォーマンスも向上できます。
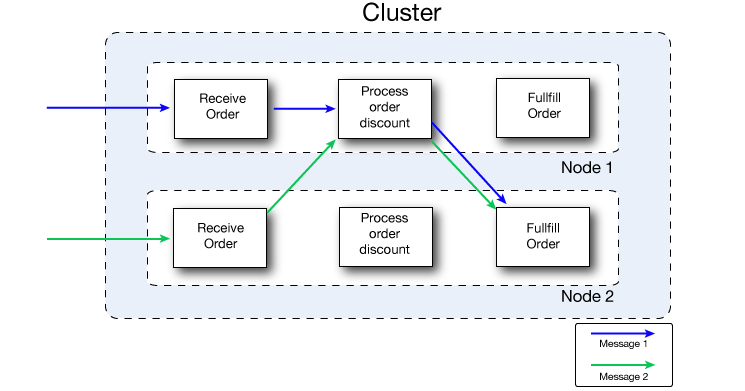
次の図では、ワークロードの共有をより詳しく示しています。両方のノードが受注処理に関するメッセージを処理します。ただし、一方のノードの負荷が大きい場合、その処理の 1 つ以上のステップの処理をもう一方のノードに移動できます。ここでは、割引処理ステップの処理がノード 1 に移動され、受注ステップの処理がノード 2 に移動されています。
自動フェールオーバーによる高可用性、パフォーマンスの向上、拡張性の向上以外に、Mule Runtime Engine のクラスタリングには次のような利点があります。
-
ファイル、データベース、FTP ソースなどのリソースへのアクセスの自動調整。
Mule Runtime Engine クラスターは、どのノード (Mule Runtime Engine) がデータソースからの通信を処理するかを自動的に管理します。 -
クラスター内の処理の自動負荷分散。
フローを一連のステップに分割してこれらのステップを VM などのコネクタと接続すると、各ステップはキューに入り、クラスターが有効になります。続いて、Mule Runtime Engine のクラスターが任意のノードで各ステップを処理し、ノード間で負荷がより効率的に分散されます。 -
アラートの生成。
ノードがダウンした場合やノードが復活したときに表示されるアラートをセットアップできます。
| クラスターのすべての Mule Runtime Engine はアクティブにメッセージを処理します。各 Mule ノードは内部でも拡張可能です。単一のノードでも複数のコアを活用することで拡張できます。Mule は複数のコアを使用する場合であっても、クラスターでは単一のノードとして動作します。 |
クラスターによって解決される同時実行の問題
クラスターとしてバインドされていない複数のサーバーで構成されたサーバーグループがある場合、次のような問題が存在する可能性があります。サーバーをクラスターとしてグループ化すれば、こうした問題に頭を悩ませることはありません。
-
ファイルベースのコネクタ。
すべての Mule インスタンスは同じ Mule ファイルフォルダーに同時にアクセスするため、ファイル処理が重複することもあれば、ファイルが Mule アプリケーションによって削除または変更された場合には障害が発生する可能性もあります。 -
マルチキャストコネクタ。
すべての Mule インスタンスは同じ TCP 要求を受けてから重複メッセージを処理します。 -
JMS トピック。
すべての Mule インスタンスは同じ JMS トピックに接続するため、非クラスタリング Mule インスタンスを水平方向に拡張した場合、メッセージの処理が反復される場合もあります。 -
JMS request-reply (要求-返信)/request-response (要求-応答)。
すべての Mule インスタンスは同じ応答キューでメッセージをリスンします。これは、Mule インスタンスが送信した要求に相関していない応答を受け取る可能性があり、結果として不正な応答になったりフローがタイムアウトにより失敗したりする場合があることを意味します。 -
冪等性再配信ポリシー。
同じ要求が異なる Mule インスタンスによって受信された場合、冪等性は機能しません。複製されたメッセージは使用できません。 -
Salesforce ストリーミング API。
同じアプリケーションの複数のインスタンスをデプロイした場合、API は単一コンシューマーしかサポートしていないため、失敗します。接続されているインスタンスが停止またはクラッシュした場合のフェールオーバーのサポートはありません。
前提条件
-
クラスターには少なくとも 2 個の Mule Runtime Engine が必要であり、それぞれを異なるマシンで実行する必要があります。
-
Mule 高可用性 (HA) では、クラスターのノード間の同期を維持するために、サーバー間に信頼性の高いネットワーク接続が必要です。
-
Mule クラスターをセットアップするには次のポートを開いたままにしておく必要があります: ポート
5701 とポート 54327。 -
マルチキャストを使用するためにクラスターを設定する場合は、マルチキャスト IP アドレス:
224.2.2.3 を有効にする必要があります。. マルチキャストは、新しいクラスターメンバーの検出に使用されます。
高可用性
高可用性とは、そこで実行されるアプリケーションのダウンタイムを防止するようにコンピューターシステムをデザインする方法です。一部のシステムでは 1 台のサーバーでダウンタイムが発生しても、アプリケーションはアプリケーションのエンドユーザーに対するサービスに提供を中断することなくもう 1 台のサーバーでスムーズに実行し続けることができるように、複数のサーバーを使用しています。
クラスターのデザインと管理
Anypoint Runtime Manager は、Mule インスタンスのクラスターをセットアップしてアプリケーションをデプロイしてクラスターで実行できるようにします。クラスターおよび個別のノードの状況に関する情報を監視することもできます。クラスタリングを行うと、複数のサーバーを 1 台として容易に管理できます。
| クラスター管理についての詳細は、Runtime Manager の「Managing Servers (サーバーの管理)」を参照してください。 |
Mule クラスターは、2 つ以上の Mule Runtime Engine、またはノードで構成され、グループにまとめられて単一ユニットとして扱われます。初期設定の場合、クラスターの拡張は 8 個の Mule Runtime Engine までにすることをお勧めします。
Anypoint Runtime Manager を使用すれば、クラスター内のすべての Mule Runtime Engine を単一の Mule Runtime Engine であるかのようにデプロイ、監視、および停止することができます。
次に示すように、クラスター内のすべてのノードはメモリを共有します。
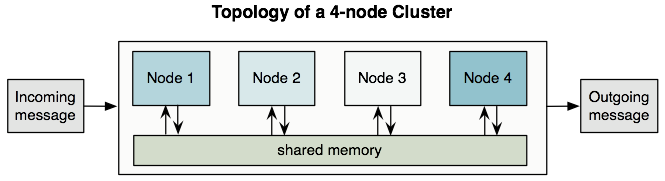
Mule は active-active (アクティブ-アクティブ) モデルを使用して Mule Runtime Engine をクラスタリングします。active-passive (アクティブ-パッシブ) モデルに対するこのモデルのメリットは、アプリケーションがすべてのノードで実行され、メッセージ処理をクラスター内の他のノードと分け合うことで、処理を効率化できることです。
プライマリノードの違い
active-active (アクティブ-アクティブ) モデルでは、プライマリノードはありません。ただし、いずれかのノードがプライマリポーリングノードの役割を果たします。つまり、他のノードがそのソースからのメッセージを読み取らないように、ソースをプライマリポーリングノードのみで使用するように設定できます。
この機能は、ソース種別に応じて異なります。
-
スケジューラーソース: プライマリポーリングノードでのみ実行されます。
-
他のソース:
primaryNodeOnly 属性で定義されます。そのコネクタの primaryNodeOnly のデフォルト値を調べるには、各コネクタのドキュメントを確認してください。JMS の設定例:<flow name="jmsListener"> <jms:listener config-ref="config" destination="listen-queue" primaryNodeOnly="true"/> <logger message="#[payload]"/> </flow>
Queues
Mule Runtime Engine (ノード) 間で負荷分散を行うために明示的に VM キューをセットアップできます。そのため、アプリケーションフロー全体に子フローのシーケンスが含まれる場合、クラスターは連続する各子フローをその時点で使用可能な任意の Mule Runtime Engine に割り当てることができます。下で示しているように、クラスターはアプリケーションフローの VM エンドポイントを通過するときに複数のノードで単一メッセージを処理することもできます。
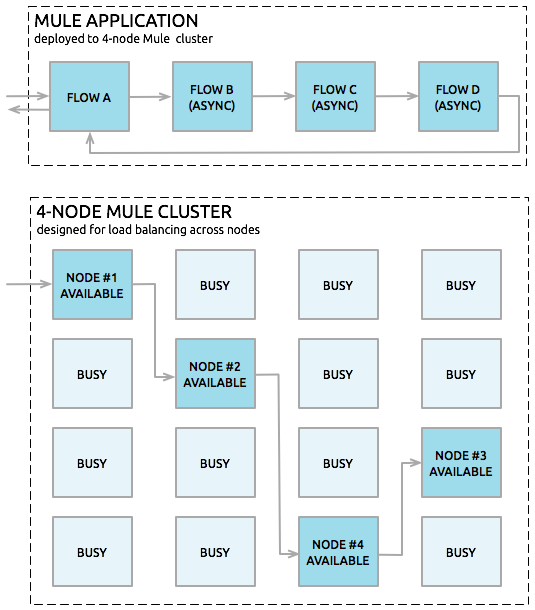
高信頼性アプリケーション
高信頼性アプリケーションと言えるには、以下の要件を満たす必要があります。
-
メッセージの損失の許容がゼロであること
-
インテグレーションエンジン (Mule) が信頼できること
-
個別の接続の信頼性が高いこと
トランザクション性として知られる機能はアプリケーションイベントシーケンスを追跡し、それぞれのメッセージ処理ステップが正常に完了するようにします。そのため、失われたり不正に処理されたりするメッセージはありません。何らかの理由でステップが失敗した場合、トランザクションメカニズムが以前の処理イベントをすべてロールバックし、メッセージ処理シーケンスを再開します。
JMS、VM、JDBC などのコネクタにより、ビルトイントランザクションサポートが提供されるため、メッセージが確実に処理されるようになります。たとえば、トランザクションがコミットされた後でのみメッセージを JMS サーバーから削除するようにインバウンド JMS 接続エンドポイントでトランザクションを設定できます。この方法により、処理フロー中にエラーが発生した場合、元のメッセージは再処理できる状態で保持されます。
トランザクションをサポートする異種コネクタ間でメッセージを移動するには、XA トランザクションを使用する必要があります。これにより、Mule Runtime Engine はすべての異種コネクタの関連付けられたトランザクションを単一ユニットとしてコミットするようになります。
コネクタのクラスターサポート
すべての Mule Connector がクラスター内でサポートされます。コネクタごとにインバウンドトラフィックにアクセスする方法が異なるため、このサポートの詳細は異なります。一般に、アウトバウンドトラフィックはクラスター内外で同じように機能します。Mule Runtime は 3 つの基本的な種別のコネクタをサポートしています。
ソケットベースのコネクタ
ソケットベースのコネクタは Mule が所有するネットワークソケットに送信された入力を読み取ります。例としては TCP、UDP、HTTP[S] などがあります。
ソケットベースのコネクタは以下に示しているようにクラスター内でサポートされます。
-
クラスタリングされた各 Mule Runtime は異なるネットワークノードで実行されるため、各インスタンスはそのノードに送信されたソケットベースのトラフィックのみを受信します。受信したソケットベースのトラフィックは、クラスタリングされたインスタンス間で分散するためにクラスタリングと負荷分散を実行する必要があります。
-
ソケットベースのコネクタへの出力は特定のホスト/ポートの組み合わせに書き込まれます。ホスト/ポートの組み合わせが外部ホストの場合、特に考慮事項はありません。ローカルホストのポートの場合、クラスター間でより効率的にトラフィックを分散するために、代わりにロードバランサーでそのポートを使用することを検討してください。
リスナーベースのコネクタ
リスナーベースのコネクタは同時の複数アクセサーを十分にサポートするプロトコルを使用してデータを読み取ります。例としては、JMS や VM があります。
リスナーベースのコネクタは以下に示しているようにクラスター内でサポートされます。
-
リスナーベースのコネクタは複数のリーダーおよびライターを完全にサポートしています。入力にも出力にも特に考慮事項はありません。
-
クラスターでは、VM Connector キューが共有のクラスター全体のリソースである点に注意してください。クラスターは VM Connector キューへのアクセスを自動的に同期します。そのため、任意のクラスターノードで VM キューに書き込まれたメッセージを処理できます。これにより、VM はクラスターノード間でワークを共有するのに最適です。
リソースベースのコネクタ
リソースベースのコネクタは複数の同時アクセサーは使用可能だがリソースの使用をネイティブに調整しないリソースからデータを読み取ります。リソースベースのコネクタの例としては、ファイル、FTP、SFTP、メール、JDBC などがあります。
リソースベースのコネクタは以下に示しているようにクラスター内でサポートされます。
-
Mule HA クラスタリングは自動的にクラスター内のノードのみについて各リソースへのアクセスを調整するため、クラスタリングされたインスタンスのうち 1 つだけが一度に各リソースにアクセスするようになります。そのため、通常はリソースベースのコネクタから読み取られたメッセージをすぐに VM キューに書き込むことをお勧めします。これにより、他のクラスターノードがメッセージの処理に参加できます。
クラスター内のノードとして同じリソースにアクセスする他のアプリケーション (クラスター外の Mule アプリケーションまたは Mule 以外のアプリケーション) を実行する場合は、これらのリソースをロックするロジックを実装する必要があります。
たとえば、複数のプログラムがファイルの読み取り、変更、そして削除を行うことで、同じ共有ディレクトリのファイルを処理しているとします。これらのプログラムは明示的なアプリケーションレベルのロッキング戦略を使用して、同じファイルが複数回処理されないようにする必要があります。
-
リソースベースのクラスタリングされたコネクタへの書き込みには特に考慮事項はありません。
-
ファイルベースのコネクタ (ファイル、FTP、SFTP) に書き込むときに、Mule は一意のファイル名を生成します。
-
JDBC に書き込むときに、Mule は一意のキーを生成できます。
-
メールの作成は、実質的にはリソースベースではなくリスナーベースです。
-
クラスタリングと信頼性の高いアプリケーション
高可用性アプリケーションは、メッセージの損失の許容がゼロである必要があります。つまり、基礎となる Mule とその個別の接続の信頼性が高い必要があります。クラスターで十分に信頼できるアプリケーションをビルドするためのツールは「信頼性パターン」で見つかります。
アプリケーションで非トランザクションコネクタを使用している場合、信頼性パターンに従ってください。これらのパターンにより、メッセージが受け入れられて正常に処理されるか、「失敗」応答を生成してクライアントが再試行できるようになります。
アプリケーションで JMS、VM、JDBC などのトランザクションコネクタを使用している場合は、トランザクションを使用します。トランザクションコネクタに対する Mule のビルトインサポートにより、こうしたコネクタを使用するアプリケーションで信頼性の高いメッセージングを実現できます。
これらのアクションは、クラスタリングされていないアプリケーションにも適用できます。
クラスタリングとネットワーキング
単一のデータセンターのクラスタリング
クラスターノード間で信頼性のある接続を確立するには、クラスターのすべてのノードを同じ LAN に配置する必要があります。VPN を通じて接続された異なるデータセンターなど、地理的に離れた場所にノードが含まれるクラスターを実装することも可能ですが、お勧めはしません。
ネットワークの中断や、メッセージの重複などの意図しない結果を招く可能性を下げるためには、すべてのクラスターノードを同じ LAN に配置するのが最もお勧めです。
分散型データセンターのクラスタリング
WAN ネットワークを使用してクラスターノードをリンクすると、外部ルーターやファイアウォールなど、障害が発生する可能性のあるポイントが多くなり、クラスターノード間で適切に同期が行われないおそれがあります。これはパフォーマンスに影響を及ぼすだけでなく、アプリケーションにおける副作用の可能性を考慮に入れる必要も生じます。たとえば、2 つのクラスターノードがネットワークリンクの障害による切断後に再接続した場合、次回の同期プロセスでメッセージが 2 回処理される可能性があり、重複が発生して、アプリケーションロジックで処理する必要が生じます。
異なるデータセンターに配置されたクラスターのノードを使用でき、必ずしも同じ LAN に配置されている必要はありませんが、いくつか制限事項がある点に注意してください。
この動作を防ぐには、Quorum プロトコルを有効にする必要があります。このプロトコルは、ノードの 1 つのセットがデータの処理を続行し、他のセットが再接続されるまで共有データに関して何も実行しないようにするために使用されます。基本的に、切断が発生した場合、ノードが最も多い方のみが稼働し続けます。たとえば、2 つのデータセンターがあり、一方は 3 つのノードがあり、もう一方には 2 つのノードがあるとします。2 つのノードがあるデータセンターで接続の問題が発生した場合、ノードが 3 つのデータセンターが機能し続け、もう一方のデータセンターは停止します。ノードが 3 つのデータセンターがオフラインになった場合、どちらのノードも機能しなくなります。こうした機能停止を防ぐには、少なくとも 3 つの同じ数のノードを持つデータセンターでクラスターを作成する必要があります。2 つのデータセンターがクラッシュすることは考えにくいため、1 つのデータセンターがオフラインになっても、クラスターは常に機能し続けることになります。
| 機能するのに十分なノードがクラスターパーティションにない場合、外部システムコールに対しては引き続き反応しますが、オブジェクトストアを経由したすべての操作は失敗し、データ生成できなくなります。 |
クラスタリングと負荷分散
TCP 要求 (この場合、TCP には SSL/TLS、UDP、Multicast、HTTP、HTTPS が含まれる) に対応するために Mule クラスターが使用される場合、クラスタリングされたインスタンス間で要求を分散するためにある程度の負荷分散が必要になります。さまざまなソフトウェアのロードバランサーが使用できますが、そのうちの 2 つを紹介します。
-
オープンソースの HTTP サーバーおよびリバースプロキシである Nginx。HTTP(S) の負荷分散に NGINX の
HttpUpstreamModule を使用できます。 -
Apache Web サーバー。これは HTTP(S) ロードバランサーとしても使用できます。
TCP と HTTP または HTTPS トラフィックの両方をルーティングできるハードウェアのロードバランサーも多数あります。
高パフォーマンス用のクラスタリング
このセクションは、オンプレミスデプロイメントにのみ適用されます。高パフォーマンスの実装は CloudHub と Pivotal Cloud Foundry で異なります。
これらの各デプロイメントについての詳細は、「デプロイメント戦略」を参照してください。
(信頼性ではなく) 高パフォーマンスが最大目標の場合は、パフォーマンスプロファイルを使用してパフォーマンスが最大になるように Mule クラスターまたは各アプリケーションを設定できます。クラスター内で特定のアプリケーションのパフォーマンスプロファイルを実装することで、デプロイメントの拡張性を最大にすると同時に、パフォーマンスおよび信頼性の要件が異なるアプリケーションを同じクラスターにデプロイすることができます。コンテナレベルで設定したパフォーマンスプロファイルは、そのコンテナ内のすべてのアプリケーションに適用されます。アプリケーションレベルの設定はコンテナレベルの設定より優先されます。
パフォーマンスプロファイルの設定には 2 つの効果があります。
-
分散キューが無効になり、代わりにローカルキューを使用して共有データグリッドにおけるデータの逐次化/非逐次化および分散を防止します。
-
バックアップなしでオブジェクトストアを実装し、複製を防止します。
コンテナレベルでパフォーマンスプロファイルを設定するには、次のコマンドを mule-cluster.properties、システムプロパティ (コマンドラインから)、または wrapper.conf に追加します。
mule.cluster.storeprofile=performance
個別のアプリケーションレベルでパフォーマンスプロファイルを設定するには、以下で示しているように、設定ラッパー内にプロファイルを追加します。
-
パフォーマンスストアプロファイル
<mule> <configuration> <cluster:cluster-config> <cluster:performance-store-profile/> </cluster:cluster-config> </configuration> </mule>
アプリケーションレベルの設定はコンテナレベルの設定より優先されます。高パフォーマンス用にコンテナを設定するが、そのコンテナ内の 1 つ以上の個別のアプリケーションでは信頼性を優先するには、こうしたアプリケーションに次のコードを含めます。
-
信頼性ストアプロファイル
<mule> <configuration> <cluster:cluster-config> <cluster:reliable-store-profile/> </cluster:cluster-config> </configuration> </mule>
|
負荷分散をサポートしないエンドポイントで負荷が大きい場合、パフォーマンスプロファイルを適用するとパフォーマンスが低下する場合もあります。非同期処理戦略、ロードバランサーがない JMS トピック、マルチキャスト、または HTTP Connector でファイルベースのコネクタを使用している場合、大量のメッセージが単一ノードに入るとボトルネックが発生する可能性があるため、こうしたアプリケーションのパフォーマンスプロファイルを無効にしたほうがパフォーマンスが向上する場合があります。 |
稼働状態を保つためにクラスターで必要なマシンの最小数を定義することもできます。この設定により、パフォーマンス全体での一貫性が改善されます。
FIPS モードでのクラスタリング
FIPS モードでのクラスタリングを有効にするには、Mule Runtime を FIPS モードで実行する必要があります。詳細は、「FIPS コンプライアンスサポート」を参照してください。
FIPS モードで実行している場合、クラスター用のキーを定義する必要があります。このキーは、mule.cluster.network.encryption.key プロパティ (wrapper.conf またはシステムプロパティ) を設定して定義できます。FIPS モードでクラスタリングされた環境を使用していて暗号化キーを設定していないと、アプリケーションはデプロイに失敗し、Cluster key must be defined in FIPS mode. というメッセージが表示されます。. 暗号化キーを定義してすべての通信を暗号化するために FIPS モードで実行する必要はありません。しかし、Runtime を FIPS モードで実行している場合は、暗号化キーを定義する必要があります。
暗号化キーを定義すると、クラスターノード間のすべての通信は定義されたキーと AES 暗号化アルゴリズムを使用して暗号化されます。
ベストプラクティス
クラスタリングに関しては多くの推奨事項があります。例を挙げます。
-
できるだけアプリケーションを一連のステップに整理し、各ステップがメッセージを 1 つのトランザクションストアから別のトランザクションストアに移動するようにします。
-
アプリケーションで非トランザクションコネクタからのメッセージを処理する場合、信頼性パターンを使用して VM や JMS ストアなどのトランザクションストアに移動します。
-
トランザクションを使用してトランザクションコネクタからのメッセージを処理します。これにより、エラーが発生した場合、メッセージが再処理されるようになります。
-
VM や JMS Connector で使用するような分散ストアを使用します。こうしたストアはクラスター全体に対して使用可能です。これは、ファイル、FTP、JDBC などのコネクタで使用する非分散ストアよりも優れています。こうしたストアは一度に単一のノードによって読み取られます。
-
VM Connector を使用して最適なパフォーマンスを得ます。クラスター全体が終了した後にデータを保存する必要があるアプリケーションに JMS Connector を使用します。
-
高信頼性アプリケーションを作成するには信頼性パターンを実装します。