Spike Control Policy
Policy Name |
Spike Control |
Summary |
Regulates API traffic |
Category |
Quality of Service |
First Omni Gateway version available |
v1.0.0 |
Returned Status Codes |
|
429 - The number of requests by HTTP APIs exceeded the configured limit. Request rejected after specified number of reattempts. |
Summary
The Spike Control policy regulates your API request traffic by limiting the number of messages processed by an API. The policy ensures that the number of messages processed within a specified time does not exceed the limit that you configure. If the number is exceeded, the request is queued for retry based on you have configured the policy.
Configuring Policy Parameters
The Spike Control policy does not perform quota enforcement. The configuration parameters are restricted to protect the API and backend. Therefore, to ensure maximum performance, configure these parameters to the lowest possible value.
Omni Gateway Local Mode
When you apply the policy via declarative configuration files, Refer to the following policy definition and table of parameters:
- policyRef:
name: spike-control-flex
config:
maximumRequests: <int> // REQUIRED, default: 1
timePeriodInMilliseconds: <int> // REQUIRED, default: 1000
delayTimeInMillis: <int> // REQUIRED, default: 1000
delayAttempts: <int> // REQUIRED, default: 1
queuingLimit: <int> // OPTIONAL, default: 0
exposeHeaders: <bool> // OPTIONAL, default: false
| Parameter | Required or Optional | Default Value | Description |
|---|---|---|---|
|
Required |
1 |
Number of allowed requests in the time window |
|
Required |
1000 |
Time window size |
|
Required |
1000 |
The amount of time for which each request is retained before retrying, in the event there is no quota remaining |
|
Required |
1 |
The number of times a request is retried before it is rejected |
|
Optional |
0 |
The number of requests that can be queued at the any given time |
|
Optional |
|
Enable it only for internal APIs. Allows the policy to return information about the algorithm behavior in the X-RateLimit headers |
Managed Omni Gateway and Omni Gateway Connected Mode
When you apply the policy from the UI, the following parameters are displayed:
| Element | Description | Required |
|---|---|---|
Number of Reqs |
The number of requests allowed (in milliseconds) in the specified window |
Yes |
Time Period |
The number of milliseconds, within which a request must be processed |
Yes |
Delay Time in Milliseconds |
The amount of time for which each request is retained before retrying (in milliseconds) in case there is no quota remaining |
Yes |
Delay Attempts |
The number of times a request is retried before it is rejected |
Yes |
Queuing Limit |
The number of requests that can be queued at the any given time |
No |
Expose Headers |
Enable it only for internal APIs, allows the policy to return information about the algorithm behavior in the X-RateLimit headers |
No |
Method & Resource conditions |
The option to add configurations to only a select few or all methods and resources of the API |
Yes |
To enforce request quotas, see the Rate Limiting: SLA-Based Policy and Rate Limiting Policy.
How This Policy Works
The Spike Control policy uses a Sliding Window Algorithm which reduces spikes in traffic and protects the gateway instance. The window self-adjusts its display size to accommodate results over time.
If the current window has no remaining request quota, without closing the connection to the client, the Spike Control policy allows requests to be queued for processing later. For your policy to queue the requests, you must configure the policy parameters, as shown in the following example:
-
Time Period: 1 second -
Number of Reqs: 2 -
Delay Time in Milliseconds: 499 milliseconds -
Delay Attempts: 1 -
Queuing Limit: 5
Queuing a request requires retaining a thread and an HTTP connection. When you specify a Queuing Limit for the policy, the parameter protects the gateway from running out of resources and ensures that the API does not fail in case of an attack.
Request Timelines
The following diagram illustrates the lifespan of each request accepted by the algorithm, using the configuration defined in the previous section:
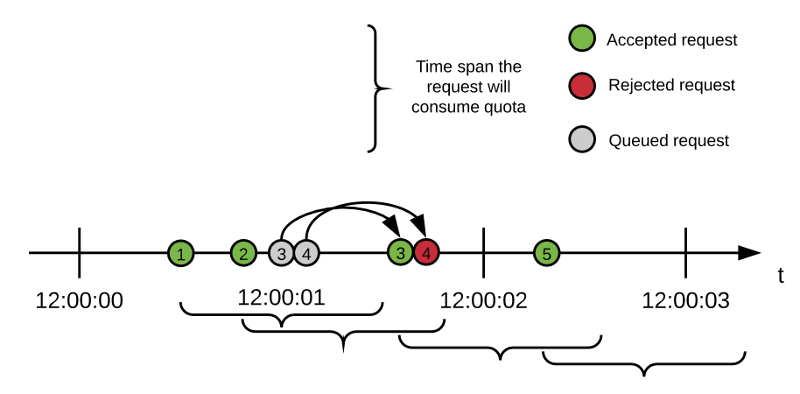
-
The first two requests are accepted and the available quota is now 0.
The quota increases to 1 after one second (the
window sizevalue) passes from request #1. -
Request #3 arrives.
Because no quota is available, the request is queued for 499 milliseconds.
-
Request #4 arrives.
Because there still is no quota available, the request is queued for 499 milliseconds.
-
Shortly before request #3 is retried, request #1 ages a second and its quota is released because it falls out of the window.
-
Quota is now 1, and request #3 is reprocessed successfully.
Quota returns to 0 until request #2 ages 1 second.
-
Request #4 delay concludes and it must be reprocessed.
Request #4 is rejected. Requests #2 and #3 have not aged a second yet and there is no quota available. Request #4 have no more delays.
-
Request #5 arrives.
Because request #2 has already aged more than a second, the request is accepted.
This example illustrates request delays and how queuing regulates spikes in traffic. In high-contention scenarios, the backend continues to function properly (it serves no more than X requests in the last Y milliseconds).
Users querying the API might still see their requests being served, but with higher latency. The exact configuration for the policy depends exclusively on your API and its throughput.
FAQ
When does the sliding window start?
The window starts with the first request after the policy is successfully applied.
What type of window does the algorithm use?
The algorithm uses a sliding window that monitors transactions for the amount of time that you configure in the policy.
What happens when the quota is exhausted?
When the request quota is exhausted, the Spike Control policy queues the request and retries as configured. The request is rejected if no quota is remaining after several retries. Quota for other requests is available only after the first request exceeds the time limit configured in the policy; in this way, requests are processed in cycles.
Can I configure multiple windows?
No. The Spike Control policy ensures that the backend server does not serve more requests than it can handle. If you need accountability, use either Rate-Limiting SLA or Rate Limit policies instead.
What does each response header mean?
Each response header has information about the current state of the request:
-
X-Ratelimit-Remaining: The amount of quota currently available
-
X-Ratelimit-Limit: The maximum available requests per window
-
X-Ratelimit-Reset: The remaining time, in milliseconds, until the oldest request ages enough to fall outside of the sliding window.
If quota is still available, the header is set to 0 (zero) because the algorithm can still serve new requests.
By default, the X-RateLimit headers are disabled in the response. You can enable these headers by selecting Expose Headers when you configure the policy.
When should I use Rate Limiting instead of Rate Limiting SLA or Spike Control?
Use Rate Limiting and Rate-Limiting SLA policies for accountability and to enforce a hard limit to a group (using the identifier in Rate Limiting) or to a client application (using Rate Limiting-SLA). If you want to protect your backend, use the Spike Control policy instead.