COBOL Copybook Format
MIME Type: application/flatfile
ID: flatfile
A COBOL copybook is a type of flat file that describes the layout of records and fields in a COBOL data file.
The Transform Message component provides settings for handling the COBOL copybook format. For example, you can import a COBOL definition into the Transform Message component and use it for your Copybook transformations.
| COBOL copybook in DataWeave supports files of up to 15 MB, and the memory requirement is roughly 40 to 1. For example, a 1-MB file requires up to 40 MB of memory to process, so it’s important to consider this memory requirement in conjunction with your TPS needs for large copybook files. This is not an exact figure; the value might vary according to the complexity of the mapping instructions. |
Importing a Copybook Definition
When you import a Copybook definition, the Transform Message component converts the definition to a flat file schema that you can reference with schemaPath property.
To import a copybook definition:
-
Right-click the input payload in the Transform component in Studio, and select Set Metadata to open the Set Metadata Type dialog.
Note that you need to create a metadata type before you can import a copybook definition.
-
Provide a name for your copybook metadata, such as
copybook. -
Select the Copybook type from the Type drop-down menu.
-
Import your copybook definition file.
-
Click Select.
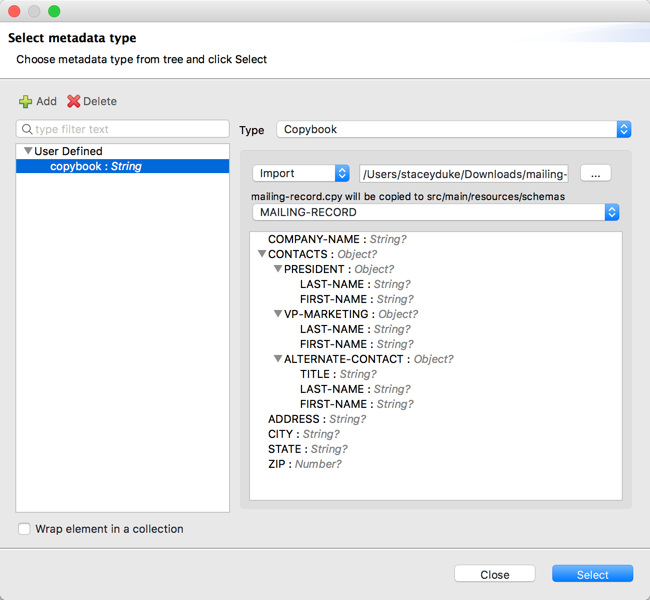 Figure 1. Importing a Copybook Definition File
Figure 1. Importing a Copybook Definition File
For example, assume that you have a copybook definition file
(mailing-record.cpy) that looks like this:
01 MAILING-RECORD.
05 COMPANY-NAME PIC X(30).
05 CONTACTS.
10 PRESIDENT.
15 LAST-NAME PIC X(15).
15 FIRST-NAME PIC X(8).
10 VP-MARKETING.
15 LAST-NAME PIC X(15).
15 FIRST-NAME PIC X(8).
10 ALTERNATE-CONTACT.
15 TITLE PIC X(10).
15 LAST-NAME PIC X(15).
15 FIRST-NAME PIC X(8).
05 ADDRESS PIC X(15).
05 CITY PIC X(15).
05 STATE PIC XX.
05 ZIP PIC 9(5).
-
Copybook definitions must always begin with a
01entry. A separate record type is generated for each01definition in your copybook (there must be at least one01definition for the copybook to be usable, so add one using an arbitrary name at the start of the copybook if none is present). If there are multiple01definitions in the copybook file, you can select which definition to use in the transform from the dropdown list. -
COBOL format requires definitions to only use columns 7-72 of each line. Data in columns 1-5 and past column 72 is ignored by the import process. Column 6 is a line continuation marker.
When you import the schema, the Transform component converts the copybook file
to a flat file schema that it stores in the src/main/resources/schema folder
of your Mule project. In flat file format, the copybook definition above looks
like this:
form: COPYBOOK
id: 'MAILING-RECORD'
values:
- { name: 'COMPANY-NAME', type: String, length: 30 }
- name: 'CONTACTS'
values:
- name: 'PRESIDENT'
values:
- { name: 'LAST-NAME', type: String, length: 15 }
- { name: 'FIRST-NAME', type: String, length: 8 }
- name: 'VP-MARKETING'
values:
- { name: 'LAST-NAME', type: String, length: 15 }
- { name: 'FIRST-NAME', type: String, length: 8 }
- name: 'ALTERNATE-CONTACT'
values:
- { name: 'TITLE', type: String, length: 10 }
- { name: 'LAST-NAME', type: String, length: 15 }
- { name: 'FIRST-NAME', type: String, length: 8 }
- { name: 'ADDRESS', type: String, length: 15 }
- { name: 'CITY', type: String, length: 15 }
- { name: 'STATE', type: String, length: 2 }
- { name: 'ZIP', type: Integer, length: 5, format: { justify: ZEROES, sign: UNSIGNED } }
After importing the copybook, you can use the schemaPath property to reference the associated flat file through the output directive. For example:
output application/flatfile schemaPath="src/main/resources/schemas/mailing-record.ffd"
Supported Copybook Features
Not all copybook features are supported by the COBOL Copybook format in DataWeave. In general, the format supports most common usages and simple patterns, including:
-
USAGE of DISPLAY, BINARY (COMP), COMP-5, and PACKED-DECIMAL (COMP-3). For character encoding restrictions, see Character Encodings.
-
PICTURE clauses for numeric values consisting only of:
-
'9' - One or more numeric character positions
-
'S' - One optional sign character position, leading or trailing
-
'V' - One optional decimal point
-
'P' - One or more decimal scaling positions
-
-
PICTURE clauses for alphanumeric values consisting only of 'X' character positions
-
Repetition counts for '9', 'P', and 'X' characters in PICTURE clauses (as in
9(5)for a 5-digit numeric value) -
OCCURS DEPENDING ON with
controlValproperty in schema. Note that if the control value is nested inside a containing structure, you need to manually modify the generated schema to specify the full path for the value in the form "container.value". -
REDEFINES clause (used to provide different views of the same portion of record data - see details in section below)
Unsupported features include:
-
Alphanumeric-edited PICTURE clauses
-
Numeric-edited PICTURE clauses, including all forms of insertion, replacement, and zero suppression
-
Special level-numbers:
-
Level 66 - Alternate name for field or group
-
Level 77 - Independent data item
-
Level 88 - Condition names (equivalent to an enumeration of values)
-
-
SIGN clause at group level (only supported on elementary items with PICTURE clause)
-
USAGE of COMP-1 or COMP-2 and of clause at group level (only supported on elementary items with PICTURE clause)
-
VALUE clause (used to define a value of a data item or conditional name from a literal or another data item)
-
SYNC clause (used to align values within a record)
REDEFINES Support
REDEFINES facilitates dynamic interpretation of data in a record. When you import a copybook with REDEFINES present, the generated schema uses a special grouping with the name '*' (or '*1', '*2', and so on, if multiple REDEFINES groupings are present at the same level) to combine all the different interpretations. You use this special grouping name in your DataWeave expressions just as you use any other grouping name.
Use of REDEFINES groupings has higher overhead than normal copybook groupings, so MuleSoft recommends that you remove REDEFINES from your copybooks where possible before you import them into Studio.
Character Encodings
BINARY (COMP), COMP-5, or PACKED-DECIMAL (COMP-3) usages are only supported with single-byte character encodings, which use the entire range of 256 potential character codes. UTF-8 and other variable-length encodings are not supported for these usages (because they’re not single-byte), and ASCII is also not supported (because it doesn’t use the entire range). Supported character encodings include ISO-8859-1 (an extension of ASCII to full 8 bits) and other 8859 variations and EBCDIC (IBM037).
REDEFINES requires you to use a single-byte-per-character character encoding for the data, but any single-byte-per-character encoding can be used unless BINARY (COMP), COMP-5, or PACKED-DECIMAL (COMP-3) usages are included in the data.
Common Copybook Import Issues
The most common issue with copybook imports is a failure to follow the COBOL standard for input line regions. The copybook import parsing ignores the contents of columns 1-6 of each line, and ignores all lines with an '*' (asterisk) in column 7. It also ignores everything beyond column 72 in each line. This means that all your actual data definitions need to be within columns 8 through 72 of input lines.
Tabs in the input are not expanded because there is no defined standard for tab positions. Each tab character is treated as a single space character when counting copybook input columns.
Indentation is ignored when processing the copybook, with only level-numbers treated as significant. This is not normally a problem, but it means that copybooks might be accepted for import even though they are not accepted by COBOL compilers.
Both warnings and errors might be reported as a result of a copybook import. Warnings generally tell of unsupported or unrecognized features, which might or might not be significant. Errors are notifications of a problem that means the generated schema (if any) will not be a completely accurate representation of the copybook. You should review any warnings or errors reported and decide on the appropriate handling, which might be simply accepting the schema as generated, modifying the input copybook, or modifying the generated schema.
Configuration Properties
DataWeave supports the following configuration properties for this format.
Reader Properties
DataWeave accepts properties that provide instructions for reading input data in this format.
| Parameter | Type | Default | Description |
|---|---|---|---|
|
|
|
When the schema contains elements of type Binary or Packed, the |
|
|
|
Error if required value missing.
Valid values are |
|
|
|
Fill character used to represent missing values. To activate a non-default setting, set the
|
|
|
|
Fills the entire group when the DEPENDING ON subject is not present. Introduced in DataWeave 2.3 with the August 2021 release of Mule 4.3.0-20210622. |
|
|
|
Expected separation between lines/records:
Note that schemas with type |
|
|
|
Schema definition. Location in your local disk of the schema file used to parse your input. |
|
|
|
Segment identifier in the schema for fixed width or copybook schemas (only needed when parsing a single segment/record definition and if the schema includes multiple segment definitions). |
|
|
|
Structure identifier in schema for flatfile schemas (only needed when parsing a structure definition, and if the schema includes multiple structure definitions) |
|
|
|
Truncate COBOL copybook DEPENDING ON values to the length used. Valid values are |
|
|
|
By default, the flat file reader and writer use spaces for missing characters and ignore the setting of the |
|
|
|
Use the |
Writer Properties
DataWeave accepts properties that provide instructions for writing output data in this format.
| Parameter | Type | Default | Description |
|---|---|---|---|
|
|
|
Size of the buffer writer. |
|
|
|
When set to |
|
|
|
Encoding to be used by this writer,
such as |
|
|
|
Error if a required value is missing.
Valid values are |
|
|
|
Fill character used to represent missing values. To activate a non-default setting, use
|
|
|
|
Fills the entire group when the DEPENDING ON subject is not present. Introduced in DataWeave 2.3 with the August 2021 release of Mule 4.3.0-20210622. |
|
|
System property |
Record separator line break. Valid values:
Note that in Mule versions 4.0.4 and later, this is only used as a separator
when there are multiple records. Values translate directly to character codes
( |
|
|
When set to |
|
|
|
Schema definition. Path where the schema file to be used is located. |
|
|
|
Segment identifier in the schema for fixed width or copybook schemas (only needed when writing a single segment/record definition, and if the schema includes multiple segment definitions). |
|
|
|
Structure identifier in schema for flatfile schemas (only needed when writing a structure definition and if the schema includes multiple structure definitions) |
|
|
|
Trim string values longer than the field length by truncating trailing characters. Valid values are |
|
|
|
Indicates whether trim values are longer than the field width. Valid Options are |
|
|
|
Truncate COBOL copybook DEPENDING ON values to the length used. Valid values are |
|
|
|
By default, the flat file reader and writer use spaces for missing characters and ignore the setting of the |
|
Supported MIME Types
The COBOL Copybook format supports the following MIME types.
| MIME Type |
|---|
|