CloudHub High Availability Features
CloudHub High Availability (HA) features provide scalability, workload distribution, and added reliability to your applications on CloudHub. This functionality is powered by CloudHub’s scalable load-balancing service, worker scale-out, and persistent queues features.
You can enable HA features on a per-application basis using the Anypoint Runtime Manager console when either deploying a new application or redeploying an existing application.
Prerequisites
CloudHub HA requires:
-
A CloudHub Enterprise or Partner account type that allows you to use this feature.
-
Familiarity with deploying applications using the Runtime Manager console.
Worker Scale-out
CloudHub allows you to select an amount and a size for the workers of your application, providing horizontal scalability. This fine-grained control over computing capacity provisioning gives you the flexibility to scale up your application to handle higher loads (or scale down during low-load periods) at any time.
Use the drop-down menus next to workers to select the number and size of workers of your application and to configure the computing power that you need.
Depending on your subscription, you can deploy your application with up to 8 workers of any kind, up to a maximum of 128 vCores per application. To ensure that you have sufficient resources, see CloudHub Workers.
Worker scale out also adds additional reliability. Mule runtime engine (Mule) automatically distributes multiple workers for the same application across two or more data centers for maximum reliability.
When deploying your application to two or more workers, you can distribute workloads across these instances of Mule. CloudHub provides the following:
-
The HTTP load balancing service automatically distributes HTTP requests among your assigned workers.
-
Persistent message queues (see below)
Batch jobs only run on a single worker at a time, and cannot be distributed across multiple workers. If mule restarts in the same deployment, the status will persist and batch will continue processing. If the entire application is updated or redeploying while batch is running, the rest of the batch job will not continue. The main solution for persistent batch jobs in CloudHub is to use Cloud Object Store.
Persistent Queues
Persistent queues ensure zero message loss and let you distribute workloads across a set of workers.
-
If your application is deployed to more than one worker, persistent queues allow communication between workers and workload distribution. For example, if a large file is placed in the queue, your workers can divide it up and process it in parallel.
-
Persistent queues guarantees delivery of your messages, even if one or more workers or data centers go down, providing additional message security for high-stakes processing.
-
With persistent queues enabled on your application, you have runtime visibility into your queues on the Queues tab in the Runtime Manager console.
-
You can enable data-at-rest encryption for all your persistent queues. By enabling this feature, you ensure that any shared application data written out to a persistent queue is encrypted, allowing you to meet your security and compliance needs.
-
Retention time for messages in a persistent queue is up to 4 days. There is no limit on message size or the number of messages in a persistent queue.
-
The worker’s persistent queue is located in the same region as the worker
Note that persistent queues do not guarantee one-time-only message delivery. Duplicate messages may be sent. If one-time-only message delivery is critical for your use case, do not enable persistent queues.
To learn more about how to work with persistent queues in your application, see Manage Queues.
Enable CloudHub HA Features
You can enable and disable either or both features of CloudHub HA in one of two ways:
-
When you deploy an application to CloudHub for the first time using the Runtime Manager console
-
By accessing the Deployment tab in the Runtime Manager console for a previously deployed application
-
Next to Workers, select options from the drop-down menus to define the number and type of workers assigned to your application.
-
See CloudHub Workers for more information about deploying to multiple workers.
Click an application to see the overview and click Manage Application. Click Settings and click the Persistent Queues checkbox to enable queue persistence.
If your application is already deployed, you must redeploy it for your new settings to take effect.
How HA is Implemented
HTTP load balancing is implemented by an internal reverse proxy server. Requests to the application (domain) URL http://appname.cloudhub.io are automatically load balanced between all the application’s worker URLs.
Clients can bypass an application’s load balancer by using a worker’s direct URL. See: CloudHub Networking Guide for more information on how to access an application in a specific CloudHub worker.
Use Cases
You can use either, both, or no HA features in a single application.
-
To take advantage of persistent queueing, set your Mule application to support this feature. See Building Mule Applications to Support Persistent Queues for more information.
-
Enabling persistent queues has a performance implication: Putting a small message (50KB or less) on a queue can take 10-20 milliseconds (ms); taking the same message off a queue can take 70-100 milliseconds.
-
Adding additional workers increases the cost of service.
| Use Case | Suggested HA Configuration | Implications |
|---|---|---|
You want to scale out your application, but you are satisfied with the existing highly available CloudHub architecture in terms of preventing service interruption or message loss. |
Persistent queues are not enabled. Number of Workers: 2 or more |
|
You have a high-stakes process for which you need to protect against message loss, but you are not experiencing issues with handling processing load and are OK with some service interruption in the case of a data center outage. |
Persistent queues are enabled. Number of Workers: 1 |
|
You have a high-stakes process for which you need to protect against message loss, avoid any chance of service interruption, and handle large processing loads. |
Persistent queues are enabled. Number of Workers: 2 or more |
|
You have an application that does not have any special requirements regarding either processing load or message loss. |
Persistent queues are not enabled. Number of Workers: 1 |
|
Persistent Queues for Applications Containing Batch Jobs
When you deploy an application containing batch jobs to CloudHub with persistent queues enabled, the batch jobs use CloudHub persistent queuing for the batch queuing functionality.
If you enable persistent queues, note the following limitations:
-
Batch jobs using CloudHub persistent queues experience additional latency.
For better performance, disable persistent queues.
-
CloudHub persistent queues occasionally process a message more than once.
To ensure that messages are processed only once, disable persistent queues.
-
When an application restarts, message loss can occur.
Because of these limitations, Mulesoft recommends that you disable persistent queues for batch jobs.
To disable a persistent queue for a batch job, add the following property to the application:
batch.persistent.queue.disable=truexml
By default, the value of this property is false.
When set to true, the application doesn’t use the persistent queue for the batch job, but the persistent queue remains enabled for other Mule components.
Building Mule Applications to Support Persistent Queues
For your application to benefit from persistent queuing, implement reliability patterns in your application code, separating individual XA transactions from VM transports. See Reliability Patterns for more information.
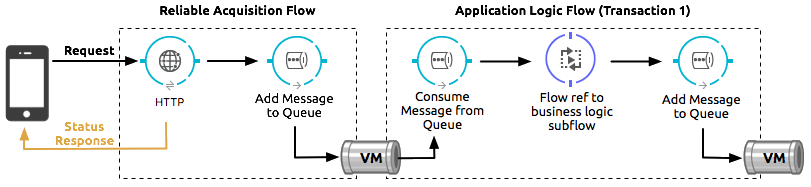
The reliable acquisition flow reliably delivers a message from an inbound HTTP connector to an outbound VM endpoint. If the reliable acquisition flow cannot put the message into the VM queue, it ensures that the message is not lost by returning an "unsuccessful request" response to the client so that the client can retry the request.
The application logic flow delivers the message from an inbound VM endpoint to the business logic processing in your application. This flow represents one transaction. (Your business logic may involve several other transactions, not shown.)
In between these two flows, a persistent VM queue holds the messages committed by the reliable acquisition flow until they are ready for processing by the application logic flow. In case of a processing error within the transaction or in case of a transaction timeout (the time allotted for the transaction is exceeded), Mule triggers a rollback. This rollback erases any partial processing that has occurred on the message and places the message back on the queue. If your Mule instance experiences an outage and is unable to explicitly roll back a transaction, the transaction automatically rolls back once the time allotted for the transaction is exceeded. The allotted time is determined by the timeout attribute of the transaction element. You can configure the timeout yourself, or accept the default.
It is helpful to think of each transaction in terms of three steps:
-
Begin. Mule kicks off the processing of all subcomponents within the transaction.
-
Commit. Mule sends the result of the completed transaction on to the next step. (For XA transactions, the commit step has two phases: a commit-request phase and a commit phase. During the commit-request phase, Mule coordinates the results of the multiple resources within the scope of the transaction and confirms that all processing executed successfully and is ready to commit. The commit phase then calls each resource to commit its processing.)
-
Rollback. If an error occurs in either the Begin or Commit steps, Mule rolls back the operations within the transaction so that no one part results in partial completion.
The following code snippet provides an example of an application set up in a reliability pattern using VM transports for queue persistence on CloudHub.
<mule xmlns:vm="http://www.mulesoft.org/schema/mule/vm" xmlns:http="http://www.mulesoft.org/schema/mule/http" xmlns="http://www.mulesoft.org/schema/mule/core" xmlns:doc="http://www.mulesoft.org/schema/mule/documentation" xmlns:spring="http://www.springframework.org/schema/beans" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans-current.xsd
http://www.mulesoft.org/schema/mule/core http://www.mulesoft.org/schema/mule/core/current/mule.xsd
http://www.mulesoft.org/schema/mule/http http://www.mulesoft.org/schema/mule/http/current/mule-http.xsd
http://www.mulesoft.org/schema/mule/vm http://www.mulesoft.org/schema/mule/vm/current/mule-vm.xsd
http://www.mulesoft.org/schema/mule/jbossts http://www.mulesoft.org/schema/mule/jbossts/current/mule-jbossts.xsd">
<vm:connector name="vmConnector" doc:name="VM">
</vm:connector>
<http:listener-config name="listener-config" host="..." port="..."/>
<!-- This is the reliable acquisition flow in the reliability pattern. -->
<flow name="reliable-data-acquisition" doc:name="reliable-data-acquisition">
<http:listener config-ref="listener-config" path="/" doc:name="HTTP Connector"/>
<expression-filter expression="#[message.inboundProperties.'http.request.path' != '/favicon.ico']" nullReturnsTrue="true" doc:name="Expression"/>
<vm:outbound-endpoint exchange-pattern="one-way" path="input" connector-ref="vmConnector" doc:name="VM"/>
</flow>
<!-- This is the application logic flow in the reliability pattern.
It is a wrapper around a subflow, "business-logic-processing".
-->
<flow name="main-flow" doc:name="main-flow">
<vm:inbound-endpoint exchange-pattern="one-way" path="input" connector-ref="vmConnector" doc:name="VM">
<xa-transaction action="ALWAYS_BEGIN" timeout="30000"/>
</vm:inbound-endpoint>
<flow-ref name="business-logic-processing" doc:name="Flow Reference"/>
<vm:outbound-endpoint exchange-pattern="one-way" path="output" connector-ref="vmConnector" doc:name="VM">
</flow>
<!--
This subflow is where the actual business logic is performed.
-->
<sub-flow name="business-logic-processing" doc:name="business-logic-processing">
....
</sub-flow>
</mule>xmlDifferences Between Hybrid VM Queues and CloudHub VM Queues
The following table describes key differences between hybrid VM queues and CloudHub VM queues.
| VM Queues in On-Premises Applications | VM Queues in Applications deployed to CloudHub |
|---|---|
You can configure the maximum number of outstanding messages using the queue-profile element. |
There is no limit to the number of outstanding messages in CloudHub. Even if you have a queue-profile element coded in your application with a maximum number of outstanding messages, CloudHub allows unlimited outstanding messages if you deploy the application to CloudHub with the Persistent Queues checkbox checked. |
You can toggle the persistence of the queue using the queue-profile element. |
The persistence of your queue is managed using the Persistent Queues checkbox in the Advanced Details section of the deployment dialog. Even if you have a queue-profile element coded in your application, CloudHub overrides these settings when you deploy the application to CloudHub with the Persistent Queues checkbox checked. |
You can define a queue store for your VM queue to use. |
CloudHub manages the queue store for you, so there is no need to define a queue store. |
Transaction commits and rollbacks for XA transactions operate according to the two-phase commit algorithm. |
In CloudHub, there is an important exception to the way the two-phase commit algorithm works for XA transactions when a message is being added to a queue. See the known issue described below for details. Note: when CloudHub consumes messages from a persistent queue, this exception to the two-phase commit algorithm does not apply. |
Considerations
When messages are added to a VM queue in CloudHub, the two-phase commit protocol for XA transactions can fail to roll back a complete transaction if the following conditions are true:
-
The commit-request phase has completed successfully. All participating processes within the transaction execute successfully, so the message is ready to commit to the queue.
-
During the commit phase, an error occurs that causes a subprocess within the transaction to fail to commit, triggering a rollback of the transaction.
-
The VM outbound endpoint completes its commit before the rollback occurs.
If all three above conditions are true, the message is added to the queue instead of being rolled back as intended by the transaction rollback process. No message loss occurs, and the transaction can still repeat, but the outbound VM queue contains an unintended message.
| This issue occurs only when a flow produces messages that need to be added to a VM queue. There is no effect on the process of consuming messages from queues. |