Veeva Vault Connector 1.2 Additional Configuration Information
Veeva Vault Connector supports the following operations and configurations:
Documents
Document Renditions
Vault Objects
VQL Query
Picklists
Audit
Spark Messaging
Invoke Rest API
Connector Configuration

Follow the instructions in Connection Configuration.
Create Documents
The Create Documents operation enables you to create single or multiple documents with the provided document metadata in CSV or JSON format. Make sure you have uploaded document files on the vault FTP server location with the document content to attach to the created documents.
Create Documents Configuration

| Field | Description |
|---|---|
Metadata Format |
Select CSV or JSON to specify the format for the document metadata. |
Document Metadata |
Document Metadata payload with the required metadata in CSV or JSON format. Ensure the payload is in the format specified in the Metadata Format field. |
Input |
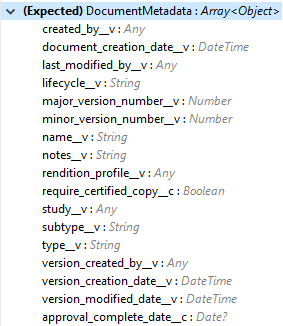
The following shows the document metadata required to create documents on the vault. Ensure the payload has the mandatory metadata required for the vault.
|
Output |
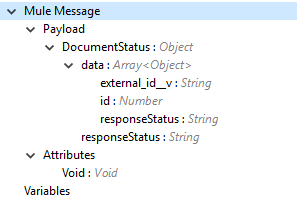
The Create Documents operation output status or response from the vault.
Note: Check the Success and Failure response status of operations in Connector Operations SUCCESS and FAILURE Response. |
Get Documents
The Get Documents operation enables you to retrieve document details based on the document type, subtype and classification selected. Using the selected type, subtype, and classification it fetches document properties metadata and builds VQL queries dynamically. The VQL query is then executed on the vault to retrieve document details. Place a For-Each/Splitter element after this operation to fetch each document’s data (page) sequentially.
This operation provides a paging mechanism based on Mule standard pagination. See Streaming and Pagination for more details.
The document type, subtype, and classification are optional. If none are selected then document properties metadata is fetched using API (/api/{version}/metadata/objects/documents/properties) and the VQL Query is built based on the document metadata properties added or inserted in the Document Properties list. If metadata properties are not provided then all queryable document properties are used in VQL and executed.
Get Documents Configuration
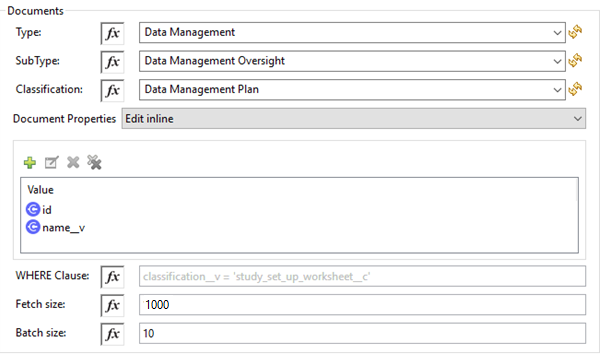
| Fields | Description |
|---|---|
Type (Optional) |
Click the refresh icon ( |
Subtype (Optional) |
Click the refresh icon ( |
Classification (Optional) |
Click the refresh icon ( |
Document Properties (Optional) |
Insert document properties per your business requirements. These properties will be used to build a VQL query to execute on the vault. |
WHERE Clause |
Insert a VQL WHERE clause (without using keyword WHERE) conditions as per business requirement and it will be appended to dynamically to build VQL query to execute on vault, for example: |
Fetch Size |
Provide the number of records per page. Default is 1000. |
Batch Size |
Provide the number of pages per batch. Default is 10. |
Input |
N/A |
Output |
You can find a list of queryable document properties retrieved from the vault. If a document properties list is provided, then the specified properties detail is retrieved and results in operation output. The default is a list of all queryable properties. 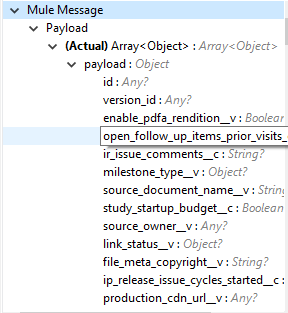
|
Delete Documents
The Delete Documents operation enables you to delete single or multiple documents using the bulk API with input metadata in CSV or JSON format.
Delete Documents Configuration

| Field | Description |
|---|---|
Metadata Format |
Select CSV or JSON to specify the format for the document metadata. |
Document Metadata |
Document Metadata payload with the required metadata in CSV or JSON format (same as the specified value in Metadata Format). |
Input |
The following shows the list of document metadata that’s required to delete documents on the vault. 
|
Output |
The delete documents operation output status or response from vault: 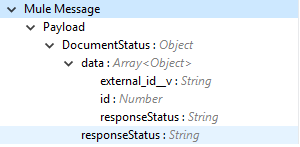
Note: Check the Success and Failure response status of operations in Connector Operations SUCCESS and FAILURE Response. |
Update Documents
The Update Documents operation enables you to update bulk documents with the provided editable metadata in the payload in CSV or JSON format.
Update Documents Configuration

| Field | Description |
|---|---|
Metadata Format |
Select CSV or JSON to specify the format for the document metadata. |
Document Metadata |
Document metadata payload with the required editable metadata in CSV or JSON format. The payload should be in the format specified in the Metadata Format field. |
Input |
The following is the list of editable document metadata to update documents on the vault. The payload should have only the editable metadata for that vault. 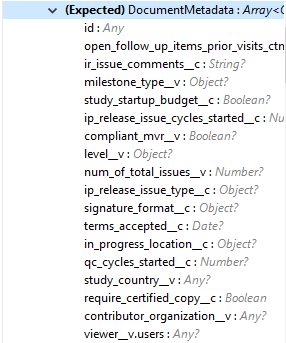
|
Output |
Create documents operation output status or response from the vault. 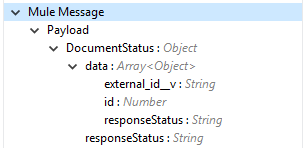
|
Export Documents
An Export Documents operation enables you to query a set of documents for export to your vault’s FTP staging server. It is recommended that you use the Export Documents operation in a separate asynchronous flow using Async Scope and passing the payload with document IDs.
When used asynchronously the operation executes in separate flow thread and waits for the specified polling interval to poll the Job status until it is successful while the main flow continues its process.
The exported documents are stored on the FTP staging area in the folder, with the hierarchy structure:
{root}/{userId}/{jobId}/{documentIds}/{versions}.
The following is an example of the Export Documents operation returning job results as response:
[
{
"file": "/41601/249051/0_1/TestDocument.docx",
"user_id__v": 1885110,
"id": 249051,
"responseStatus": "SUCCESS",
"minor_version_number__v": 1,
"major_version_number__v": 0
},
{
"file": "/41601/249050/0_1/TestDocument.docx",
"user_id__v": 1885110,
"id": 249050,
"responseStatus": "SUCCESS",
"minor_version_number__v": 1,
"major_version_number__v": 0
},
{
"file": "/41601/249052/0_1/TestDocument.docx",
"user_id__v": 1885110,
"id": 249052,
"responseStatus": "SUCCESS",
"minor_version_number__v": 1,
"major_version_number__v": 0
}
]
The previous example shows the following attributes:
-
file
Has the format:"/{jobId}/{documentId}/{major-minor-version}/{filename}", which is the absolute file path location on the Vault FTP server staging area. -
user_id__v
Vault system user ID of a user whose credentials are configured in the connector. The folder is created on the Vault FTP server staging area root location under where the exported file is located. The folder is created with the name of the user ID prefixed with the letter ‘u’; for example:
/uXXXXXXX/{jobId}/{documentId}/{major-minor-version}/{filename}\) -
id
Document ID of the exported document file. -
major_version_number__v
Major version number of the exported document file -
minor_version_number__v
Minor version number of the exported document file.
Export Documents Configuration
| Field | Description |
|---|---|
Metadata Format |
Select CSV or JSON to accept metadata for the specified document ID in either CSV or JSON format. |
Document Metadata |
Document Metadata payload contains document IDs in either CSV or JSON format. The payload should be in the format specified in the Metadata Format field. |
Source |
(Optional) To exclude source files, set to |
Renditions |
(Optional) To include renditions, set to |
All Versions |
(Optional) To include all versions, or the latest version, set to |
Polling Interval |
(Optional) Poll the vault at specified intervals (in seconds) until the job is successful. Default is 30 seconds. |
Input |
Input document metadata required to export documents from the vault to the FTP staging server. Make sure the payload has the mandatory metadata required for the vault. 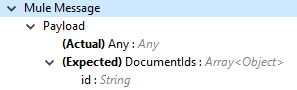
|
Output |
The export documents job status response is under the Output tab: 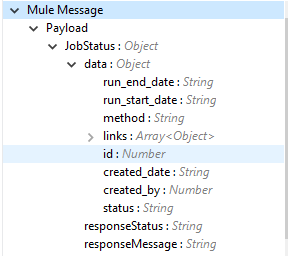
Note: Check the Success and Failure response status of operations in Connector Operations SUCCESS and FAILURE Response. |
Create Document Renditions
The Create Document Renditions operation enables you to add document renditions in bulk. Your vault must be in Migration Mode before using this operation. It takes CSV input data with a maximum size of 1 GB with a standard UTF-8-encoded value.
Create Document Renditions Configuration

| Field | Description |
|---|---|
Metadata Format |
Select CSV or JSON to specify the format for the document metadata. |
Document Metadata |
Document metadata payload with required metadata in CSV or JSON format. The payload must be in format specified in the Metadata Format field. |
Input |
Document metadata required in payload under the Input tab: 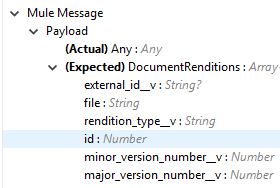
|
Output |
Operation output or response under the Output tab: 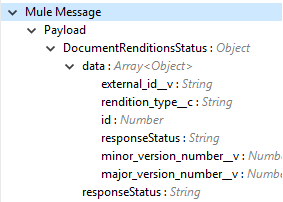
Note: Check the Success and Failure response status of operations in Connector Operations SUCCESS and FAILURE Response. |
Get Document Renditions Types
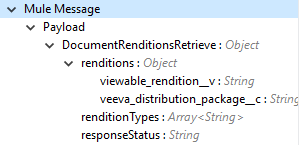
The Get Document Renditions Types operation enables you to retrieve document renditions types details.
Get Document Renditions Types Configuration

| Field | Description |
|---|---|
Document Metadata |
Document ID in the payload in either in CSV or JSON format. |
Input |
Document ID required in the payload is under the Input tab of the retrieve document renditions details operation:
|
Output |
The following operation output or response is under the Output tab:
Note: Check the Success and Failure response status of operations in Connector Operations SUCCESS and FAILURE Response. |
Delete Document Renditions
The Delete Document Renditions operation enables you to delete document renditions in bulk using CSV or JSON format input metadata.
Delete Document Renditions Configuration

| Field | Description |
|---|---|
Metadata Format |
Select CSV or JSON to specify the format for the document metadata. |
Document Metadata |
Document Metadata payload with the required metadata in CSV or JSON format (specified in the Metadata Format field). |
Input |
Document metadata required to create documents on the vault. Make sure the payload has the mandatory metadata required for the vault. 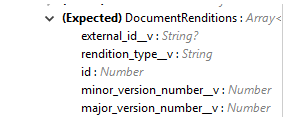
|
Output |
Delete document renditions operation output status or response from the vault: 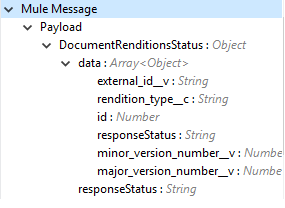
Note: Check the Success and Failure response status of operations in Connector Operations SUCCESS and FAILURE Response. |
Create Object Records
The Create Object Records operation enables you to create bulk object records for the selected vault object with the provided object metadata in CSV or JSON format.
Create Object Records Configuration

| Field | Description |
|---|---|
Object Name |
Click the VeevaVault refresh icon ( |
Metadata Format |
Select CSV or JSON to accept object metadata in the specified format. |
Object Metadata |
Object field’s payload with the required metadata in CSV or JSON format. Make sure the payload is in the format specified in the Metadata Format field. |
Input |
The following shows the list of object metadata required to create object records: 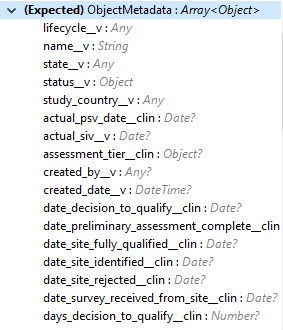
|
Output |
Operation output or responses retrieved from the vault for a created object record. 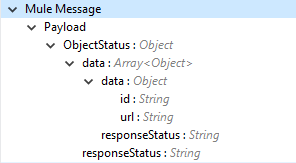
Note: Check the Success and Failure response status of operations in Connector Operations SUCCESS and FAILURE Response. |
Get Object Records
The Get Object Records operation enables you to retrieve object records details using object metadata fields to build a VQL query dynamically and execute on vault to get object details. Place a For-Each/Splitter element after this operation to fetch each object records (page) sequentially.
This operation provides a paging mechanism based on Mule standard pagination. See Streaming and Pagination for more details.
Get Object Records Configuration
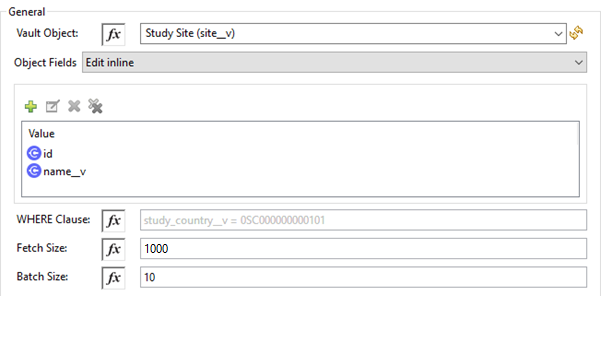
| Fields | Description |
|---|---|
Vault Object |
Click the refresh icon ( |
Object Fields |
(Optional) Insert object fields per your business requirements. These fields will be used to build a VQL query to execute on the vault. |
WHERE Clause |
Insert a VQL |
Fetch Size |
Provide the number of records per page. Default is 1000. |
Batch Size |
Provide the number of pages per batch. Default is 10. |
Input |
N/A |
Output |
The list of object records fields to add into the Object fields list. If the object fields list is provided, then the specified fields detail is returned as output. Default is a list of all fields. 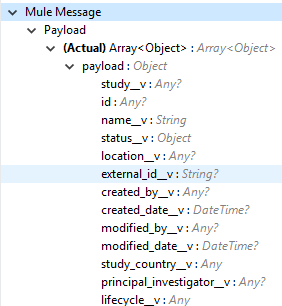
|
Delete Object Records Configuration
| Field | Description |
|---|---|
Object Name |
Click the refresh icon ( |
Metadata Format |
Select CSV or JSON to accept document metadata in the specified format. |
Object Metadata |
Object fields payload with the required metadata in CSV or JSON format. Make sure the payload is in the same format specified in the Metadata Format field. |
Input |
List of object metadata required to delete object records: 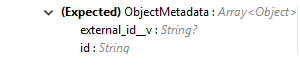
|
Output |
Operation output or response retrieved from vault for an object records deleted: 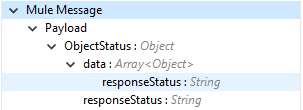
Note: Check the Success and Failure response status of operations in Connector Operations SUCCESS and FAILURE Response. |
Update Object Records
The Update Object Records operation enables you to update object records of specified vault object.
Update Object Records Configuration
| Field | Description |
|---|---|
Object Name |
Click the refresh icon ( |
Metadata Format |
Select CSV or JSON to accept object metadata in the specified format. |
Object Metadata |
Object fields payload with the required metadata in CSV or JSON format. Make sure the payload is in the same format that is specified in the Metadata Format field. |
Input |
List of object metadata required to create object records: 
|
Output |
Object status of an object updated as an output or response retrieved from the vault is under the Output tab of the operation. 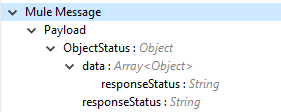
Note: Check the Success and Failure response status of operations in Connector Operations SUCCESS and FAILURE Response. |
Query
The Query operation enables you to execute the specified VQL query on the vault and retrieve the result in a paginated data input stream. Place a For-Each/Splitter element after the Query operation to fetch each record in sequential order.
Note: Do not specify LIMIT and OFFSET in the VQL query. These parameters are incorporated internally.
This operation provides a paging mechanism based on Mule standard pagination. See Streaming and Pagination for more details.
Query Configuration
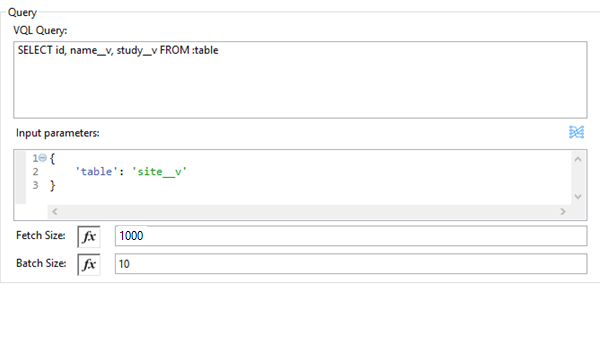
| Field | Description |
|---|---|
VQL Query |
Enter a VQL query to send it to the vault. Note: Do not specify the |
Input Parameters |
The input parameters pass parameters to a VQL query dynamically. The parameters must be a name-value pair. Payload or variable values can be passed; for example: #[
{
'table': 'site__v',
}
]
Default parameter is |
Fetch Size |
Provide the number of records per page. Default is 1000. |
Batch Size |
Provide the number of pages per batch. Default is 10. |
Input |
N/A |
Output |
You can find the specified VQL query fields in the Output tab of the operation. It returns the specified VQL query and the result contains pagination data. 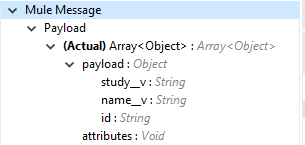
|
Use Input Parameters to Protect VQL Queries
The Query operation is used to retrieve documents, object, and workflow information from the vault. The primary concept of this operation is to supply a VQL query and use DataWeave to supply the parameters.
In the previous example, input parameters are supplied as key-value pairs, which you can create by embedding a DataWeave script. Those keys are used in conjunction with the colon character (:) to reference a parameter value by name. This is the recommended approach for using parameters in your VQL query.
The alternative is to directly write <veevavault:vql>SELECT id, namev, studyv FROM documents WHERE name__v = #[payload] </veevavault:vql>, but this is a very dangerous practice that is not recommended.
The following are the advantages of using input parameters to configure the WHERE clause in a SELECT statement:
-
The query becomes immune to VQL injection attacks.
-
The connector can perform optimizations that are not possible otherwise, which improves the app’s overall performance.
Get Picklists
The Get Picklists operation enables you to retrieve all available picklist values configured on a picklist.
Get Picklists Configuration

| Field | Description |
|---|---|
Picklist Name |
Click the refresh icon ( |
Input |
N/A |
Output |
You can find picklist values with name and label in the Output tab of the Get Picklists operation.
|
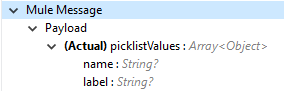
Get Audit Details
The Get Audit Detail operation enables you to retrieve audit details for the specified audit type. This operation provides a paging mechanism based on Mule standard pagination.
See Streaming and Pagination for more details.
Get Audit Details Configuration
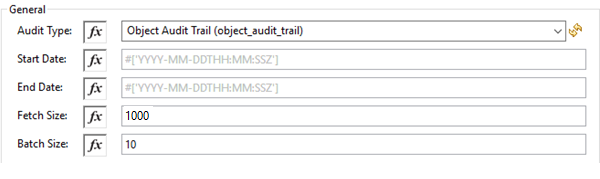
| Field | Description |
|---|---|
Audit Type |
Click the refresh icon ( |
Start date |
(Optional) Specify the start date to retrieve audit information. This date cannot be more than 30 days in the past. Dates must be in |
End date |
(Optional) Specify the end date to retrieve audit information. This date cannot be more than 30 days in the past. Dates must be in |
Fetch Size |
Provide the number of records per page. Default is 1000. |
Batch Size |
Provide the number of pages per batch. Default is 10. |
Input |
N/A |
Output |
The following selected audit type details are retrieved from the vault in pagination format. Make sure to use a 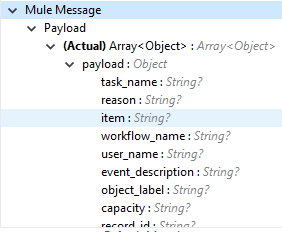
|
Spark Validator
The Spark Validator operation validates and verifies Spark messages triggered from the vault with a signature and public key. Upon successful validation and verification, the Spark message can be further processed in the Mule flow according to your business requirements. See Spark Messaging feature and functionalities and setup for more details.
The output of the Spark Validator operation includes Spark attributes (optional) with the Spark message as it is received from Vault.
Note: Before triggering a Spark message from the Vault make sure to raise a support ticket with Veeva Vault Support to increase the time interval (for example, 10 seconds) for the Spark message to resend or retry. By default, it is configured as 3 seconds, which is less than the time required for Spark Validator to complete message validation and verification.
Note: As per Veeva Systems the public key (00001.pem) expires every two years. You receive notification in advance advising you of the expiration date. If you are using this operation in a Mule application flow, after the public key expiration date you need to remove the public key file from the path configured in the Public Key Path field. A new public key will be created during execution of the key removal. If you don’t do this, Spark message verification fails as INVALID_SPARK_MESSAGE. The Mule application deployed on CloudHub with the default path must be restarted for successful Spark Message verification.
Spark Validator Configuration
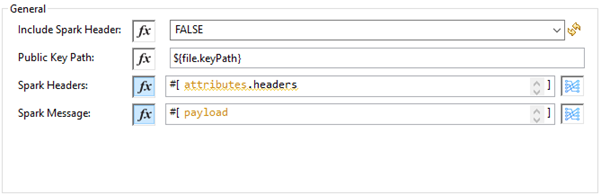
| Field | Description |
|---|---|
Include Spark Header |
Flag to include Spark headers received from the vault in Spark Validator output. Default is |
Public Key Path |
The path to where the public key (00001.pem) file is saved that will be used for verifying incoming Spark messages with a signature. Default is |
Spark Headers |
The Spark headers received from the vault. Default is |
Spark Message |
The Spark message body received from the vault. Default is |
Input |
Inputs required for Spark Validator: image::veevavault-connector-spark-validator-input.png[image,width=285,height=330] |
Output |
Output returns from the Spark Validator operation: image::veevavault-connector-spark-validator-output.png[image,width=280,height=265] |
Invoke Rest API
The Invoke Rest API operation enables you to invoke Veeva Vault Rest APIs. The response returned is either in JSON (default) or XML format, depending on the header Accept value provided.
Invoke Rest API Configuration
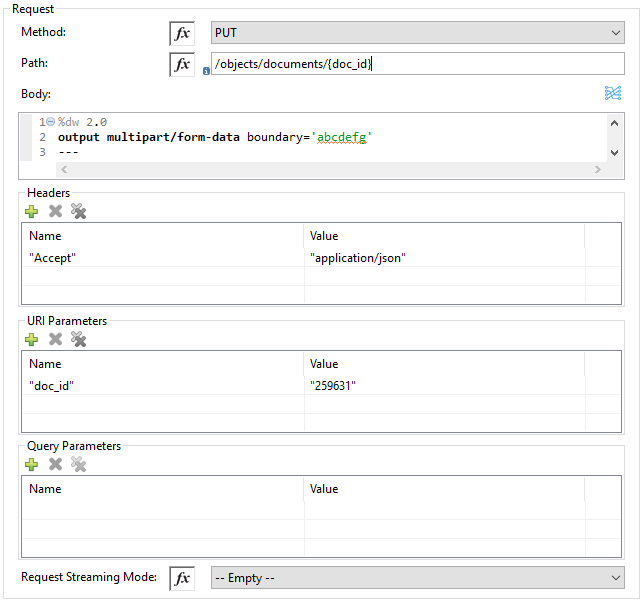
| Field | Description |
|---|---|
Method |
Method to invoke the Veeva Vault Rest API. The default is GET. |
Path |
URI path to invoke the Veeva Vault Rest API. For example: |
Body |
Body to send with a request to invoke Veeva Rest API. Default is #[payload]. |
Headers |
Headers in key-value format to send along with the request. If there are no required headers in the request, leave empty. The default is Empty list. |
URI Parameters |
URI Parameters in key-value format to resolve the value in the path. If there are no URI parameters in the path, leave empty. The default is an Empty List. |
Query Parameters |
Query parameters in key-value format to send along with the request. If there are no query parameters required in the request, leave empty. The default is Empty list. |
Request Streaming Mode |
Whether to use streaming mode for the request. By default, if the type of the payload is a stream, streaming is used to send the request. Select the streaming option from the drop-down list. |
Input |
N/A |
Output |
Response either in JSON (default) or XML format, depending on the specified header Accept value provided in Headers section. |
A typical use of the Invoke Rest API operation is to invoke the Veeva Vault Rest API using the default GET method. By default, GET methods do not send the payload in the request; the body of the HTTP request is empty. The other methods send the message payload as the body of your request.
After sending a request, the connector receives the response either in JSON (default) or XML format, depending on the header Accept value provided. The payload is then passed to the next element in your application’s flow.
Add Parameters
By default, the Invoke Rest API operation sends the Mule message payload as the request body, but you can customize it using a DataWeave script or expression. In addition to the body of the request, you can configure:
-
Headers
-
Query parameters
-
URI parameters
Headers
In General > Request > Query Parameters, click the plus icon (+) to add headers to the request. For example, add header names HeaderName1 and HeaderName2, and header values HeaderValue1 and HeaderValue2.
You can use DataWeave expressions, for example:
#[{'HeaderName1' : 'HeaderValue1', 'HeaderName2' : 'HeaderValue2'}].
URI Parameters
You configure a URI parameter when you want to use a placeholder, such as /objects/documents/{doc_id}, in the path of your request. To configure a URI parameter, type the placeholder enclosed in curly brackets in the Path field. Select URI Parameters, and click the plus sign (+), to enter a name and value.
Query Parameters
In General > Request > Query Parameters, click the plus icon (+) to add a parameter to a request. Type a name and value for the parameter or use a DataWeave expression to define the name and value.
Sending Form Parameters in a POST Request
To send parameters in a POST request:
-
In General > Request, select the POST method.
-
In Body, construct the payload of the Mule message.
Following are some examples:
-
Enter the names and the values of the parameters to send for application/x-www-form-urlencoded:
#[output application/x-www-form-urlencoded --- {'key1':'value1', 'key2':'value2'}] -
In multipart/form-data, ensure the header Content-Type value contains a boundary attribute with the same value as the Dataweave output as shown, for example:
multipart/form-data; boundary=abcdefg.%dw 2.0 output multipart/form-data boundary='abcdefg' --- { parts: { file: { headers: { "Content-Disposition": { "name": "file", "filename": attributes.fileName }, "Content-Type": payload.^mimeType }, content : payload }, name__v: { headers: { }, content: 'Test Document' }, type__v: { headers: { }, content: 'Trial Management' }, subtype__v: { headers: { }, content: 'Meetings' }, classification__v: { headers: { }, content: 'Kick-off Meeting Material' }, lifecycle__v: { headers: { }, content: 'Base Doc Lifecycle' }, study__v: { headers: { }, content: '0ST000000000301' }, comments__c: { headers: { }, content: 'Test Document' } } }
-
Connector Operations SUCCESS and FAILURE Response
The Veeva Vault Connector operation responses are based on the Veeva Vault API success or failure response with an error.
The connector returns a SUCCESS response at HIGH LEVEL and SUCCESS or FAILURE at LOW LEVEL. This means the connector operation is successful but some document or object records failed to create or update due to some irrelevant metadata being passed in the request.
Examples
SUCCESS with SUCCESS response:
{
"responseStatus": "SUCCESS",
"data": [{
"id": 239026,
"name__v": "E22611234--38483",
"responseStatus": "SUCCESS"
},
{
"id": 239025,
"name__v": "Kick-off Meeting Material Updated12341234--81032",
"responseStatus": "SUCCESS"
}
]
}
SUCCESS with a FAILURE response:
{
"data": [
{
"external_id__v": "TEST-238924",
"rendition_type__v": "imported_rendition__c",
"id": 238924,
"responseStatus": "FAILURE",
"minor_version_number__v": 1,
"errors": [
{
"type": "INVALID_DATA",
"message": "Document not found [238924/0/1]."
}
],
"major_version_number__v": 0
},
{
"external_id__v": "TEST-238925",
"rendition_type__v": "imported_rendition__c",
"id": 238925,
"responseStatus": "FAILURE",
"minor_version_number__v": 1,
"errors": [
{
"type": "INVALID_DATA",
"message": "Document not found [238925/0/1]."
}
],
"major_version_number__v": 0
}
],
"responseStatus": "SUCCESS"
}
The Veeva Vault operations throw an exception when Veeva Vault APIs return a FAILURE response, for example:
FAILURE with an ERROR response
{
"responseStatus": "FAILURE",
"errors": [
{
"type": "INVALID_DATA",
"message": "Unknown relationship [reviewer__v]"
}
]
}
Upon receiving the FAILURE response from Veeva Vault APIs, the connector operations throw an exception, which is caught in the Error Handling component within the Mule flow:
********************************************************************************** Message : An error occurred from the Veeva Vault API. Error Code: INVALID_DATA. Original Error Message: Unknown relationship [reviewer__v]. Error type : VEEVAVAULT:INVALID_DATA **********************************************************************************
The following are the error codes that are caught in the Error Handling component:
-
VEEVAVAULT:API_LIMIT_EXCEEDED
-
VEEVAVAULT:ATTRIBUTE_NOT_SUPPORTED
-
VEEVAVAULT:INACTIVE_USER
-
VEEVAVAULT:INVALID_DATA
-
VEEVAVAULT:INVALID_DOCUMENT
-
VEEVAVAULT:INSUFFICIENT_ACCESS
-
VEEVAVAULT:MALFORMED_URL
-
VEEVAVAULT:METHOD_NOT_SUPPORTED
-
VEEVAVAULT:NO_PERMISSION
-
VEEVAVAULT:OPERATION_NOT_ALLOWED
-
VEEVAVAULT:PARAMETER_REQUIRED
Streaming and Pagination
All the operations in the connector (except Download Document) return an InputStream as a payload with respective results based on operation output. Because of this, by default, Mule applies Streaming Strategies. See Mule Streaming Strategies for more details. The streaming strategies configuration fields are in the Advanced tab of the connector operations.
The following operations in the connector provide a pagination mechanism based on Mule standard pagination.
While using the paginated operations make sure to place a For-Each/Splitter element to retrieve each object (metadata is in JSON format) at a time. The pagination operations have Fetch Size and Batch Size fields.
-
Fetch Size
The Fetch Size is a limit number of records that can be retrieved in a single page. The operation returns the pages with the fetch size number of JSON object records.
In some cases, Veeva APIs auto-calculate the fetch size (number of records on each page) based on record size and the calculation exceeds the standard record size. The operation returns calculated records on each page. -
Batch Size
The Batch Size is the number of pages to return in each batch and each page will have the fetch size number of records. The operation returns a number of records (metadata in JSON format) per batch, and is calculated like in the following example:
Fetch Size set as *1000* Batch Size set as *10* If the total records in the vault are *100,000*, then: Number of pages = Total records/Fetch Size = 100000/1000 = 100 pages. Number of pages per batch = Number of pages/Batch Size = 100/10 = 10 pages per batch. Number of Records per batch = Number of pages per batch * Fetch Size = 10 * 1000 = 10,000 records. Therefore, the number of records returned per batch would be 10,000 records.
The repeatable streams measure the buffer size in byte measurements. When handling objects, the runtime measures the buffer size using instance counts.
In non-repeatable streams connector operations return streams as the number of records per batch. Repeatable streams return all records at once, so when calculating the in-memory buffer size for repeatable auto-paging, you need to estimate how much memory space each instance takes to avoid running out of memory.
Next Step
After you complete configuring the connector, you can try the Examples.