Applying Rate Limiting Policy v1.2.0
Rate Limiting 1.2.0 includes the capabilities in Rate Limiting 1.0.0 and 1.1.0 plus the capability to apply a quota by a key-sensitive identifier. This policy is available since Mule 4.1.0
The identifier is a DataWeave expression that maps to a String, creating a selector key. In Rate Limiting 1.0.0 and 1.1.0, when you apply the policy to an API, only one rate limiting algorithm is created per policy with the configured limits and an identification. In 1.2.0, the selector key is part of the identification. Therefore, one algorithm is created for each selector key, and they have their own quota.
You specify the identifier when you apply the policy.
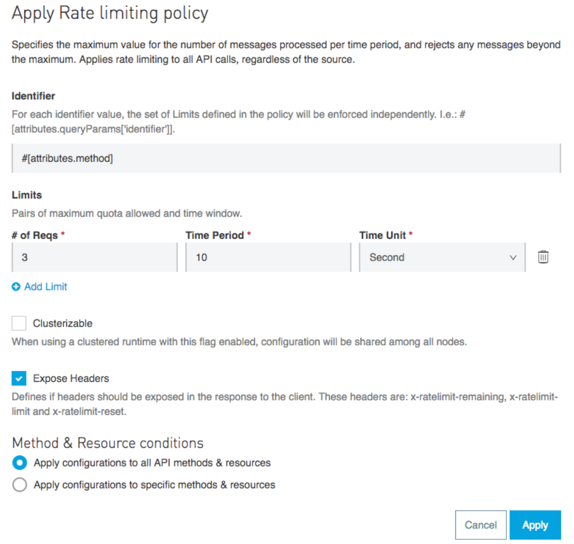
This example makes Rate limiting effective for every method. The quota is independent for each method (3 requests per 10 seconds). Such a policy configuration could result in the events over a hypothetical period of time shown below:
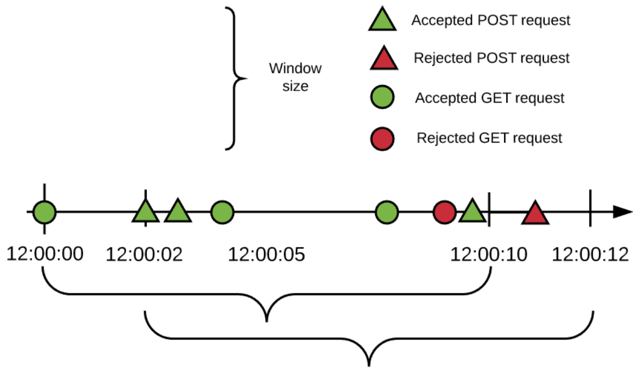
The example shows the following things:
-
Every HTTP Method is allowed 3 requests every 10 seconds (in this example only GET and POST requests have been made to the API).
-
The Rate Limiting policy works in a fixed window fashion (see the window size bracket).
-
Window start times are independent: The engine uses a lazy creation strategy that spools a Rate limiting algorithm whenever the first request for a method is received.
To Apply Rate Limiting Using an Identifier on Non-Obligatory Parameters
The identifier is a non-obligatory parameter. By default the identifier is blank, preserving compatibility with all previous versions of the Rate limiting policy as follows:
-
When not set (blank), the quota limiting applies to every request matched by the policy pointcut, using one bucket.
-
When set for an obligatory HTTP header, each case-sensitive value of the header has its own quota. Quotas are created lazily.
-
When set for a non obligatory HTTP header, custom header, payload, query parameter or expression, each value has its own quota.
If the identifier is not sent in the request, it defaults to an empty identifier, having its own quota. This behavior allows the Rate limiting policy to be applied to an API consumed by uncontrolled clients, and at the same time accommodates special buckets for the clients sending the identifier (which may be internal controlled services).
The following image illustrates the latter case, which corresponds to a 3-requests-per-10-seconds quota with the DataWeave expression: #[attributes.queryParam[‘customIdentifier’]] as the policy identifier:
In the case, the following actions occur:
-
All requests without the identifier are resolved to the empty identifier, and therefore use a single rate limiting algorithm.
-
Each different identifier uses a different bucket, with its own independent quota.
To Apply Rate Limiting Using DataWeave Expressions
The rate limiting engine is HTTP agnostic, depending solely on the resolution of the DataWeave expression. You can alter the identifier expression to cover complex rate limiting scenarios.
For example, you can configure a rate limiting policy with an identifier that uses one bucket for all Class A & C LAN requests, and another one for everything else.
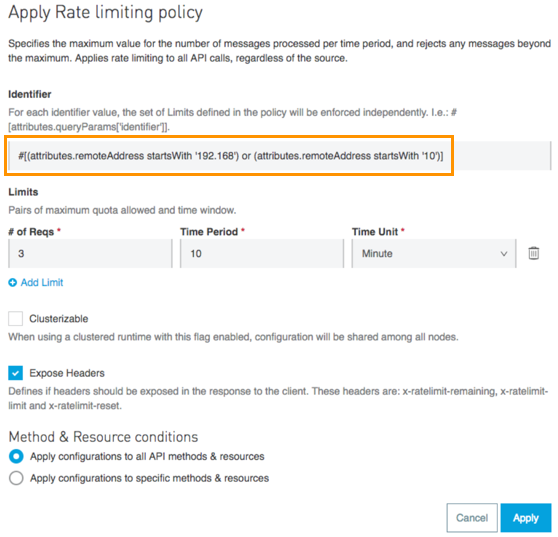
This configuration creates a false or a true bucket that corresponds to the locality of the IP that made the request.
False and true correspond to the domain of boolean values, not HTTP; nevertheless, the policy works correctly because the engine treats the resolved expression as a String.
Possible identifiers must extract the result from the request using DataWeave, but otherwise, are unlimited except by your imagination.
Note: The HTTP RFC declares header names as case-insensitive. The MuleSoft HTTP Connector changes header names to lowercase characters. DataWeave is key-sensitive. Therefore, when creating the identifier expression, remember to reference headers in lowercase.
Unbounded Identifier Sets
As one algorithm must exist for every identifier, carefully create the DataWeave expression not to return an unbounded co-domain (or a very large one), as it will require hosting the same amount of algorithms in memory (if there is at least a request for every possible identifier). For example, suppose the DataWeave expression uses the ip as the identifier in a runtime that is public to the Internet. If every public IPv4 IP in the internet makes a request to this runtime, there will be 3,706,452,992 algorithms running in a single runtime. On an average of 250 bytes per algorithm, this would be approximately 1 terabyte in rate limit algorithms.
MuleSoft recommends using a DataWeave expression that resolves to a finite number of identifiers, and to keep the resulting set as small as possible.
Rate Limiting for Anypoint Service Mesh
The Rate Limiting policy works in the same way for Anypoint Service Mesh (non-Mule applications), excluding the following limitations:
-
The policy does not support sub-bucketing (single bucket only) by an identifier.
-
The policy does not offer the option to expose headers.