Throttling And Rate Limiting Policies Reference
This deep dive into the technologies behind throttling and rate limiting covers Throttling and Rate Limiting policy topics related to APIs deployed on Mule 3.x and earlier. Much of the reference also applies to APIs deployed on Mule Runtime 4.x.
Terminology
The following terms apply to rate limiting and throttling:
-
Limits: A series of pairs—quota, window
-
Quota: The
# of Reqsyou configure in API Manager -
Window: API Manager pair—time period, time unit
-
Retries: Throttling capability to queue requests
-
Contracts: relationship between an Application and an SLA
Limits
Selecting a limit in API Manager defines the quota per time window configuration for a rate limiting and throttling algorithm. The algorithm is created on demand, when the first request is received. This event fixes the time window.
Each request consumes quota from the current window until the time expires. When quota is exhausted, the resulting action depends on the policy:
-
Rate limiting rejects the request.
-
Throttling queues the request for retry.
When the time window closes, quota is reset and a new window of the same fixed size starts. The policy creates one algorithm for each limit with its quota per time window configuration. Therefore, when multiple limits are configured, every algorithm must have available quota in its current window for the request to be accepted.
Response Headers
The following access-limiting policies return headers having information about the current state of the request:
-
X-Ratelimit-Remaining: The amount of available quota.
-
X-Ratelimit-Limit: The maximum available requests per window.
-
X-Ratelimit-Reset: The remaining time, in milliseconds, until a new window starts.
Throttling Retries
Because throttling is intended to smooth spikes, Mule Runtime can delay requests and retry the requests later. The following examples describe how requests are rejected or accepted.
Rejected Request
Policy Configuration: 5 requests/10 seconds window, 1 retry with 500ms delay
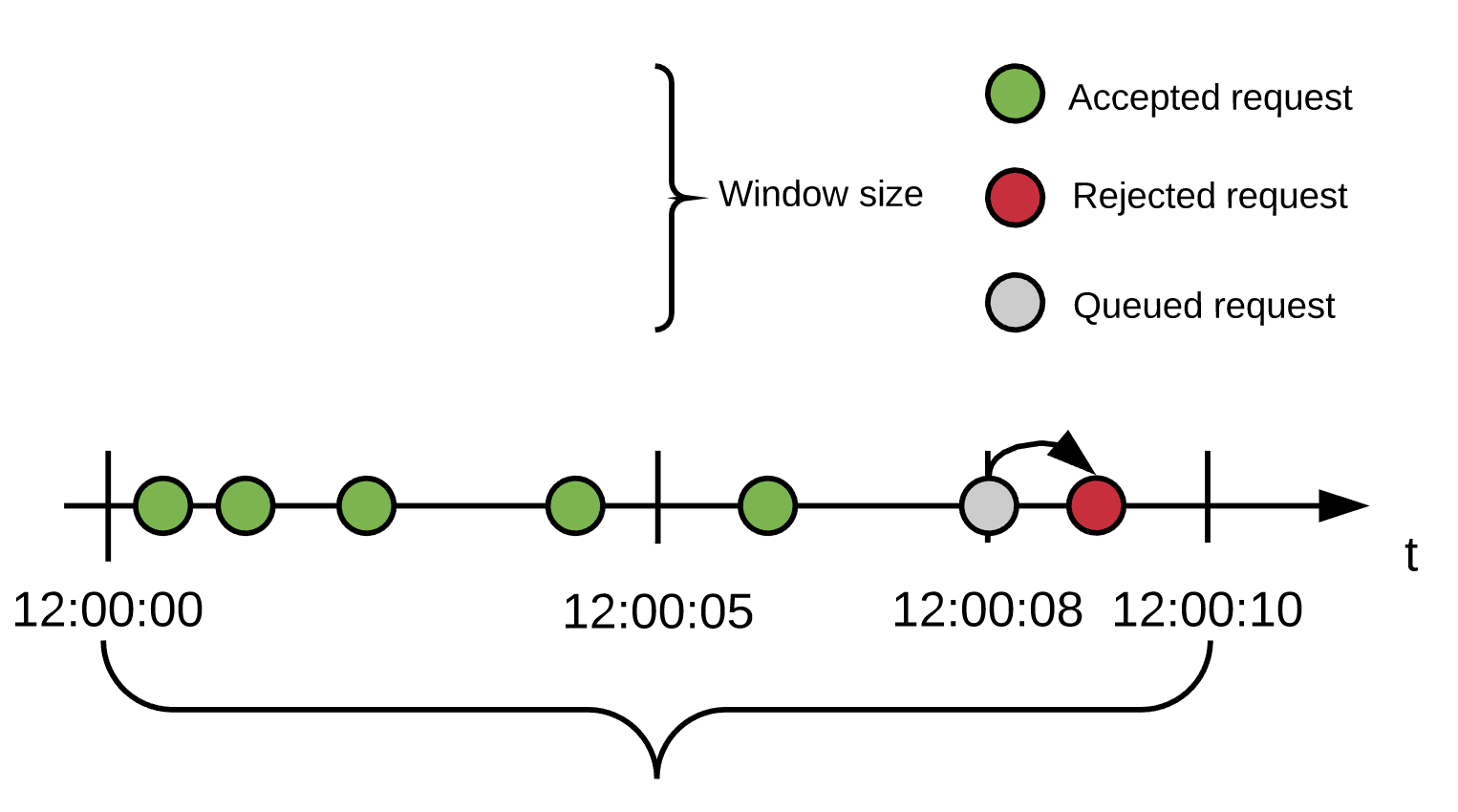
Users send 5 requests within the first six seconds, and all are accepted. At 8 seconds, a new request comes in. No quota remains, so the request is delayed for 500ms.
At the 8.5 seconds, the queued request is reprocessed. As the window has not yet closed, there is still no quota available. Also, there are no more retries available, so the request is rejected.
Accepted Request
Policy Configuration: 5 requests/10 seconds window, 1 retry with 500ms delay
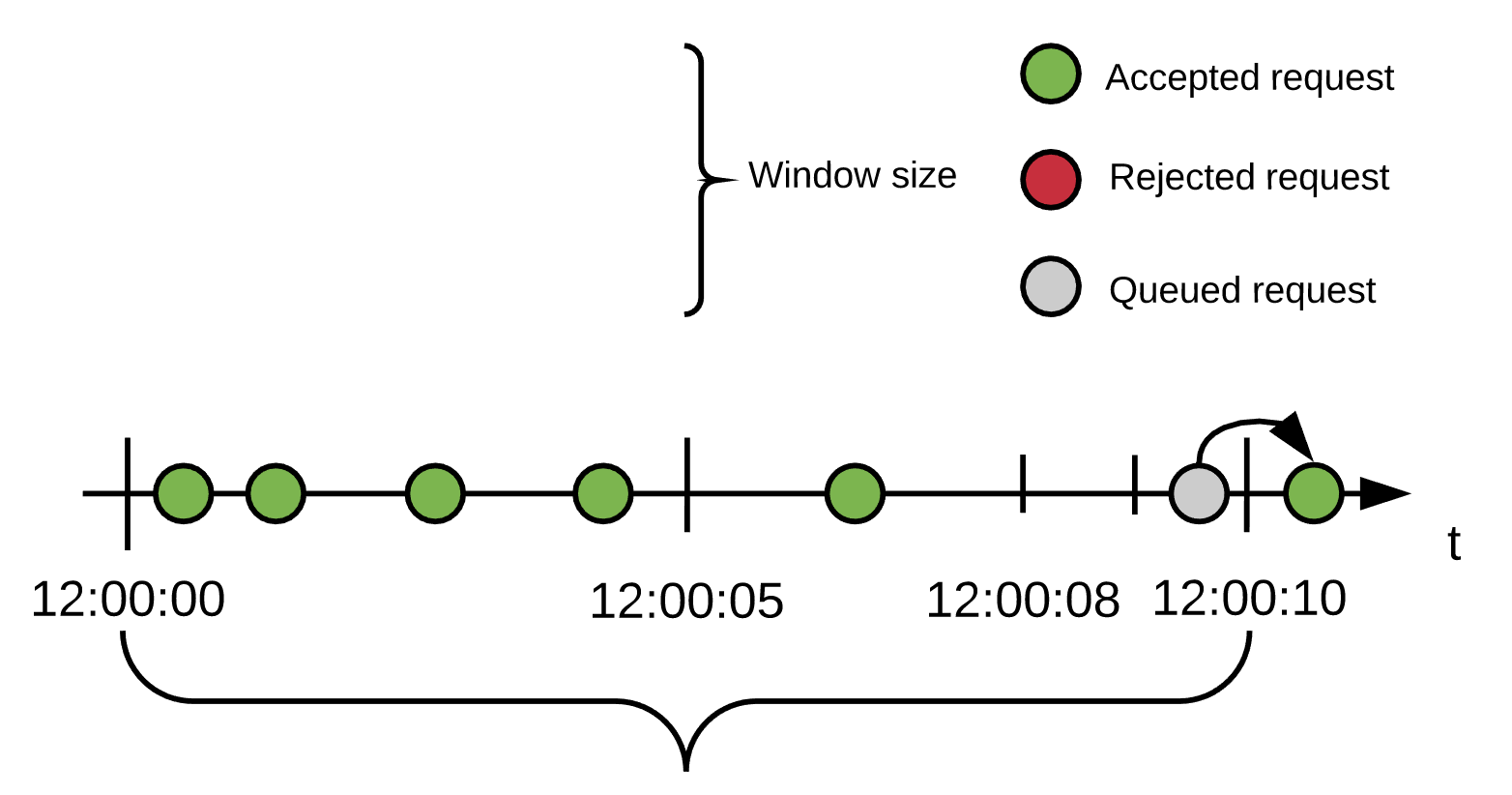
Users send 5 requests within the first nine seconds, all of them are accepted. At 9.7 seconds, a new request comes in. No quota remains, so the request is delayed for 500ms.
At 10 seconds, the window closes, and quota is reset to 5. At 10.2 seconds since the start (the 0.2 second mark of the current window) the queued request is reprocessed. Now, there is available quota, so the request is accepted (available quota decreases to 4).
Configuration
Because the Throttling policy works over the HTTP stack, an open connection must be preserved between the user and the API for each of the queued requests to be reprocessed. This process is resource intensive, and on large windows, HTTP or the underlying TCP may cancel the connection due to timeout.
Although not enforced in Gateway 2.x and Mule Runtime 3.x, small windows are recommended. A one (1) second maximum window is considered small. Using this policy in a standalone environment is recommended.
Cluster vs. Standalone
One way to achieve resiliency is to use redundancy: multiple Mule Runtime instances serving the same API.
A consideration in this situation is whether or not rate limiting (with or without SLA) should be shared. You can set up Mule Runtimes to run in a cluster to share the configured limits and treat all nodes as a whole.
The following analyses cover different scenarios.
Decentralized processing
n nodes where:
-
Each has its own backend.
-
The fastest response is required.
-
The number of served requests are limited only by the backend capacity.
-
SLA levels are not available or each node serves only one.
For example, you need two nodes; one is assigned to the billing users of the company, and the other is assigned to the rest.
For decentralized processing in this scenario, there is no need for cluster. Just set the policy below the backend capacity of the weakest of the nodes. In the no SLA scenario, a load balancer could be useful in case a node goes down.
Centralized processing
n nodes where:
-
The backend is centralized.
-
The number of served requests are limited only by the backend capacity.
-
SLA levels are not available or every node serves the same, single SLA.
For example, every node is assigned to the billing users of the company.
If there is a load balancer up front, there is no need for a cluster. If q is the maximum capacity of the backend, then configure the policy as follows:
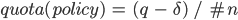
where Omega 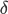 is a small number, below the backend maximum capacity.
is a small number, below the backend maximum capacity.
If there is no load balancer, cluster mode is recommended over standalone as you cannot configure beforehand how much traffic each node will handle. These policies are designed to work both on a perfectly balanced workload, or completely uneven. The backend will not receive any extra requests.
Multiple Workers
n CloudHub workers where:
-
Each one represents the same API.
-
The application workload is equally distributed across the workers.
The approach should be the same as the Centralized processing use case.
Using Several Contracts
n nodes where:
SLAs are applied.
If a Rate Limiting SLA is applied, and each node must accept requests from multiple SLAs, then a cluster is a good choice in this situation, as you cannot determine beforehand how many requests from each SLA each node will serve.
Time Window Sizes in a Cluster
In a cluster, the nodes must share information for consistency across the cluster. The sharing process adds latency that must be taken into account when reviewing performance.
In the worst case scenario, the number of penalized requests with latency due to cluster consistency is constant and independent from the actual size of the configured quota. Consequently, the smaller the window, the greater the percentage of potentially delayed requests. Therefore, MuleSoft strongly recommends setting only window sizes greater than one minute in Rate Limiting and Rate Limiting SLA policy configurations.
Minimizing Latency
The clustered algorithm minimizes the amount of shared information to maximize performance. Response headers (the X-Rate-Limit headers) are calculated with a heuristic that predicts the size of available quota in the cluster, without the need for resynchronization on every request. The error in the headers information is always less than 10%. Still, the amount of accepted requests will not be greater than the defined quota.
Configuration
In API Gateway Runtime 2.x and Mule Runtime 3.x, Rate Limiting policies with and without SLA will automatically run distributed in a cluster. You cannot turn off this feature.
Persistence
You can configure rate limiting and throttling algorithms to use big windows sizes: days, months, years. For example, suppose as a client you want to allow your user X to consume 1M requests per year. You cannot predict whether the node will be up the entire period or need maintenance, which may result in restarting the runtime. The algorithm has been running for several months, so the client will lose critical information. Persistence solves this problem by periodically saving the current policy state. In case of a redeployment or restart, the algorithms are recreated from the last known persisted state or started from a clean state.
Although persistence is enabled by default, you can turn it off by setting the following property to false:
throttling.persistence_enabled
You can also tweak the persistence frequency rate, which has a default of 10 seconds:
throttling.persistent_data_update_freq
IMPORTANT: This feature is disabled on CloudHub.