Runtime Fabric デプロイメントの水平ポッド自動スケーリング (HPA) の設定
Runtime Fabric インスタンスでは、CPU 使用量をシグナルとして、それに応じて追加レプリカの作成や不要なレプリカの削除を行うことで、Mule アプリケーションデプロイメントの水平スケーリングをサポートしています。
MuleSoft は Kubernetes (K8s) ランタイム側の CPU 使用量に反応する Mule アプリケーションの設定をサポートしています。Runtime Manager アプリケーションデプロイメントページで、CPU ベースの水平自動スケーリングを有効にできます。これにより、必要に応じてデプロイメントレプリカが自動的にスケールアップまたはスケールダウンされます。
Kubernetes では、水平ポッド自動スケーリング (HPA) により、需要に合わせてワークロードを自動的にスケーリングするために、ワークロードリソースが自動的に更新されます。水平スケーリングとは、負荷の増加に対応してより多くのポッドをデプロイするという意味です。
| HPA は Runtime Fabric エージェントバージョン 2.6.22 以降でのみサポートされています。 |
この機能の対象は、新しい価格設定およびパッケージモデルにオプトインしている一部のお客様のみです。詳細は、Anypoint Platform 価格設定を参照してください。
始める前に
自動スケーリングを設定するには、クラスター管理者は、管理対象の K8s API サーバー上で メトリクス API のサポートを有効にする必要があります。 メトリクス API サーバーをインストールまたは有効化する方法は、管理対象のベンダードキュメントを参照してください。
クラスター自動スケーリングの推奨事項
次の推奨事項は、クラスターの自動スケーリングを設定するインフラストラクチャチーム向けのものです。
ノードグループの設定
可用性ゾーンごとに 1 つのノードグループを設定し、ノードグループには 1 つ以上のノードを含めます。 これにより、Kubernetes がクラスター内のすべての可用性ゾーンの情報を持ち、ゾーントポロジーのスケジュール不可ポッドがスケールアウト topologySpread predicate チェックに失敗するという問題を避けることができます。
すべてのノードグループのノードの表示ラベルが全く同じであることを確認します。ただし、一般表示ラベルと固有のクラウドプロバイダー表示ラベルは例外で、デフォルトでノードや可用性ゾーン間で異なります。
ノード間で異なるカスタム表示ラベル (一般表示ラベルまたは固有のクラウドプロバイダー表示ラベルではない) は類似するノードグループを評価するときにクラスター自動スケーラーから除外する必要があります。
次のような管理 EKS 表示ラベルでの参照
eks.amazonaws.com/nodegroup failure-domain.beta.kubernetes.io/region failure-domain.beta.kubernetes.io/zone kubernetes.io/hostname topology.kubernetes.io/region topology.kubernetes.io/zone
クラスター自動スケーラーフラグの設定
フラグ --balance-similar-node-groups=true を使用してクラスター自動スケーラーを起動し、フラグ --balancing-ignore-label を使用してノードグループセクション内の前述したカスタム表示ラベルを除外します。
これらのフラグを使用することで、クラスター自動スケーラーは可用性ゾーン間のノード数のバランスを取ります。
管理 EKS クラスターでの参照では、次のノード表示ラベルはノードグループ間で異なります。
k8s.amazonaws.com/eniConfigCustom vpc.amazonaws.com/eniConfig
そのため、クラスター自動スケーラーの起動時に次のように指定します。
- --balancing-ignore-label=k8s.amazonaws.com/eniConfigCustom - --balancing-ignore-label=vpc.amazonaws.com/eniConfig
このような設定の推奨事項はガイドラインとして使用できます。ただし、クラスター自動スケーラー (CA) の実際の設定は使用するクラウドまたはインフラストラクチャのプロバイダー (ベンダー) や関連するトポロジーの考慮事項によって異なります。CA を適切に設定する必要があります。
オーバープロビジョニングノードの設定
可用性ゾーンごとに 1 つ以上のオーバープロビジョニングノードを設定します。各オーバープロビジョニングノードは 1 つのリソースを保持し、リソースは 3 つの Mule アプリケーションに対応できます。これにより、新しいノードが必要な場合のパフォーマンスが向上します。
| クラスター自動スケーリングのベストプラクティスとオーバープロビジョニング設定についての詳細は、管理対象のベンダードキュメントを参照してください。 |
トポロジー拡散制約の設定
自動スケーリングによって有効になった Mule アプリケーションデプロイメントでは、ポッド仕様内で whenUnsatisfiable 項目を DoNotSchedule に更新することによって、トポロジー拡散制約のために Kubernetes リソースをカスタマイズする必要があります。
この設定により、高可用性のために自動スケーリングレプリカがゾーン間に均等に拡散されます。
topologySpreadConstraints:
- maxSkew: 1
topologyKey: topology.kubernetes.io/zone
whenUnsatisfiable: DoNotSchedule
labelSelector:
matchLabels:
rtf.mulesoft.com/id: "{{ .Values.id }}"
whenUnsatisfiable: DoNotSchedule を使用すると、ポッドが可用性ゾーン間に均等に拡散されることが保証されます。この設定を変更するには、K8S テンプレート CRD を使用し、HPA を使用しているデプロイメントを whenUnsatisfiable: DoNotSchedule にします。また、専用の名前空間 (環境) を使用して、自動スケーリングのワークロードを従来のものと分離することもできます。この変更を行わない場合は、whenUnsatisfiable: ScheduleAnyway を使用します。
設定についての詳細は、Mule アプリケーション Kubernetes リソースのカスタマイズドキュメントを参照してください。
可用性ゾーンあたりのノードグループ、クラスター自動スケーラー、オーバープロビジョニングの推奨される設定を使用せずに whenUnsatisfiable: DoNotSchedule を使用してトポロジー拡散をカスタマイズすると、待機中状態エラーが発生し、K8s がレプリカのスケジュールに失敗することがあります。
|
CPU ベースの自動スケーリングポリシーの理解
MuleSoft は、お客様の Mule アプリケーションデプロイメントの 自動スケーリングポリシーを所有し、適用します。
次の例は、Runtime Fabric インスタンスにデプロイされた Mule アプリケーションに使用される CPU ベースの HPA ポリシーを示しています。minReplicas 値と maxReplicas 値は Runtime Manager インターフェースから選択できます。
apiVersion: autoscaling/v2
kind: HorizontalPodAutoscaler
metadata:
name: my-app
namespace: app-namespace
spec:
behavior:
scaleDown:
policies:
- periodSeconds: 15
type: Percent
value: 100
selectPolicy: Max
stabilizationWindowSeconds: 1800
scaleUp:
policies:
- periodSeconds: 180
type: Percent
value: 100
selectPolicy: Max
stabilizationWindowSeconds: 0
maxReplicas: <maxReplicasChosenFromRuntimeManagerUI>
metrics:
- resource:
name: cpu
target:
averageUtilization: 70
type: Utilization
type: Resource
minReplicas: <minReplicasChosenFromRuntimeManagerUI>
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: my-app
考慮すべき点をいくつか挙げます。
スケールアップは最長 180 秒おきに実行されます。各期間に、設定された最大レプリカ数に達するまで、現在実行中のレプリカの最大 100% を追加できます。スケールアップの場合は安定化期間はありません。対象をスケールアップする必要があることをメトリクスが示すと、対象はすぐにスケールアップされます。
スケールダウンは最長 15 秒おきに実行されます。各期間に、現在実行中のレプリカの最大 100% を削除できます。つまり、スケーリング対象は許容される最小レプリカ数までスケールダウンできます。削除されるレプリカ数は、過去 1800 秒間の安定化期間に集計された計算に基づきます。
最小レプリカ数
-
任意の時点で実行が保証されるレプリカの最小数。
-
スケールダウンポリシーによって、この数を下回るまでレプリカが削除されることはありません。
最大レプリカ数
-
スケールアップでそれ以上はレプリカが追加されない上限となるレプリカの最大数。
-
スケールアップポリシーによってこの数を超えてレプリカが追加されることはありません。
HPA を有効にすると、アプリケーションが水平にスケーリングされるときにお客様に追加のフロー使用量が発生することがあります。予期しないスケーリングによる超過を避けるため、購入したフロー制限内に収まるように最大レプリカ数は慎重に設定してください。発生したフロー使用量は使用状況レポートで追跡できます。
HPA の CPU 使用率は平均 70% です。
HPA は リソース要求に基づいています。
When target utilization value is set, the controller calculates the utilization value as a percentage of the equivalent resource request on the containers in each pod.
期間内 (スケールアップの期間は 180 秒に設定されています) のポッドの平均使用率が 70% より高い場合、HPA はスケールアップします。詳細は Kubernetes のドキュメントを参照してください。
パフォーマンスに関する考慮事項と制限事項
Mule アプリケーションの水平自動スケーリングを成功させるために、パフォーマンスに関する次の考慮事項を確認してください。
-
Runtime Fabric で、使用されるポリシーが Mule アプリケーションに対して評価され、予約済み CPU: 0.45vCpu、vCPU 制限: 0.55vCpu となりました。これは次の設定に対応します。
resources: limits: cpu: 550m requests: cpu: 450m -
CPU 使用量に基づいてスケーリングされる Mule アプリケーションは CPU ベースの HPA に適しています。次に例を示します。
-
非同期要求を使用する HTTP/HTTPS
-
リバースプロキシ
-
低レイテンシー + 高スループットのアプリケーション
-
DataWeave 変換
-
APIkit ルーティング
-
ポリシーを使用する API ゲートウェイ
-
-
バッチジョブなどの並列処理が組み込まれていない非リエントラントアプリケーション、リエントランシーやアプリケーション間の重複スケジューリングがないスケジューラーアプリケーション、大きな要求を使用する低スループット高レイテンシーアプリケーションなどは、CPU ベースの HPA に適していません。
-
スケールアップとスケールダウンのパフォーマンスはレプリカサイズとアプリケーション種別に応じて異なります。
-
ポリシーは 850m より小さいレプリカサイズに対して最適化されています。レプリカサイズがそれよりも大きい場合は、スケーリングに時間がかかる可能性があります。HPA は、平均使用量が 0.2vCPU の小さな CPU アプリケーションにのみお勧めします。
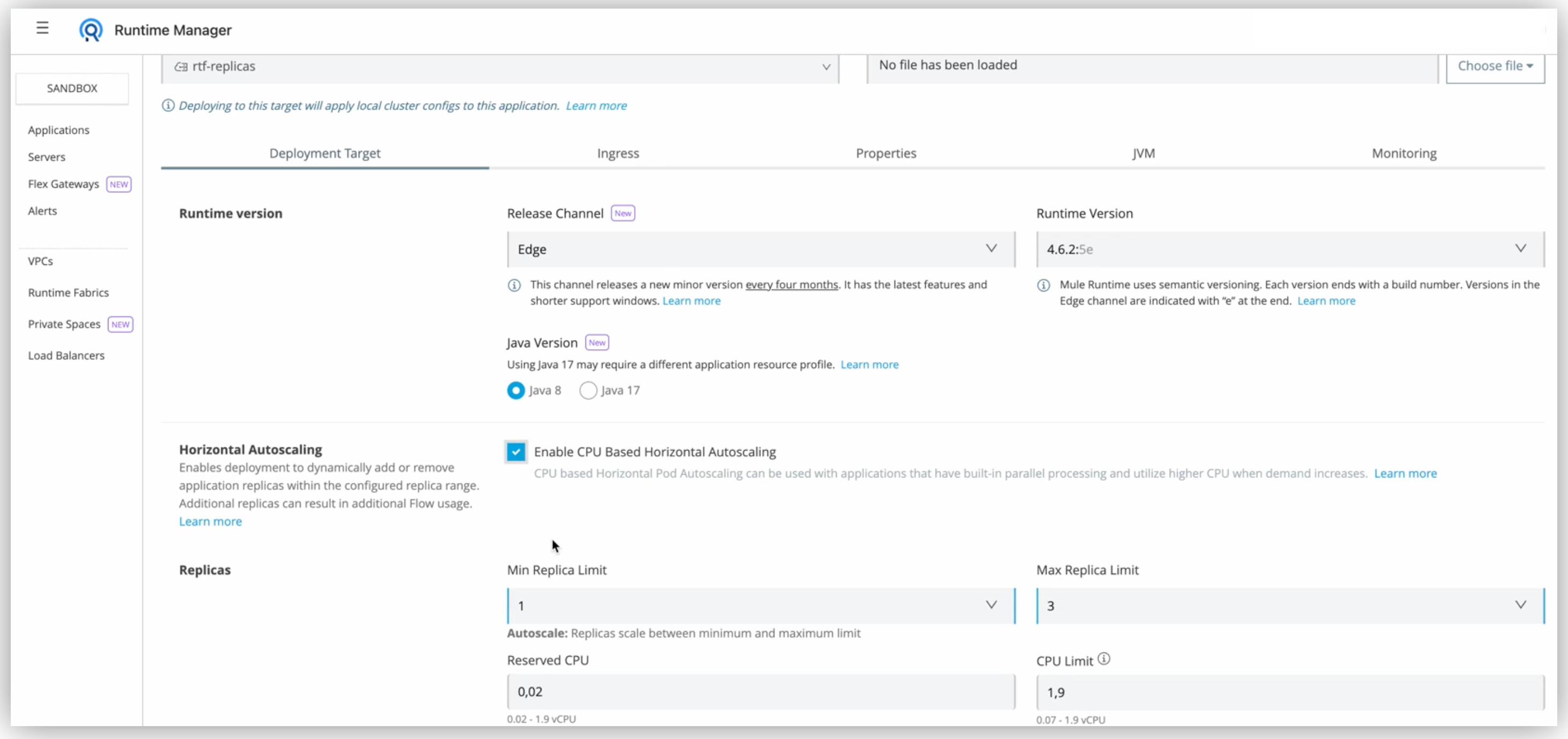
水平ポッド自動スケーリングの設定
Runtime Fabric にデプロイされた Mule アプリケーションの水平自動スケーリングを設定する手順は次のとおりです。
-
管理対象の K8s API サーバー上で メトリクス API のサポートを有効にします。
-
Anypoint Platform から、[Runtime Manager] > [Applications (アプリケーション)] を選択します。
-
[Deploy application (アプリケーションをデプロイ)] をクリックします。
-
[Runtime (ランタイム)] タブで、[Enable Autoscaling (自動スケーリングを有効化)] ボックスをオンにします。
-
最小と最大の [Replica Count (レプリカ数)] を設定します。
-
[Deploy Application (アプリケーションをデプロイ)] をクリックします。
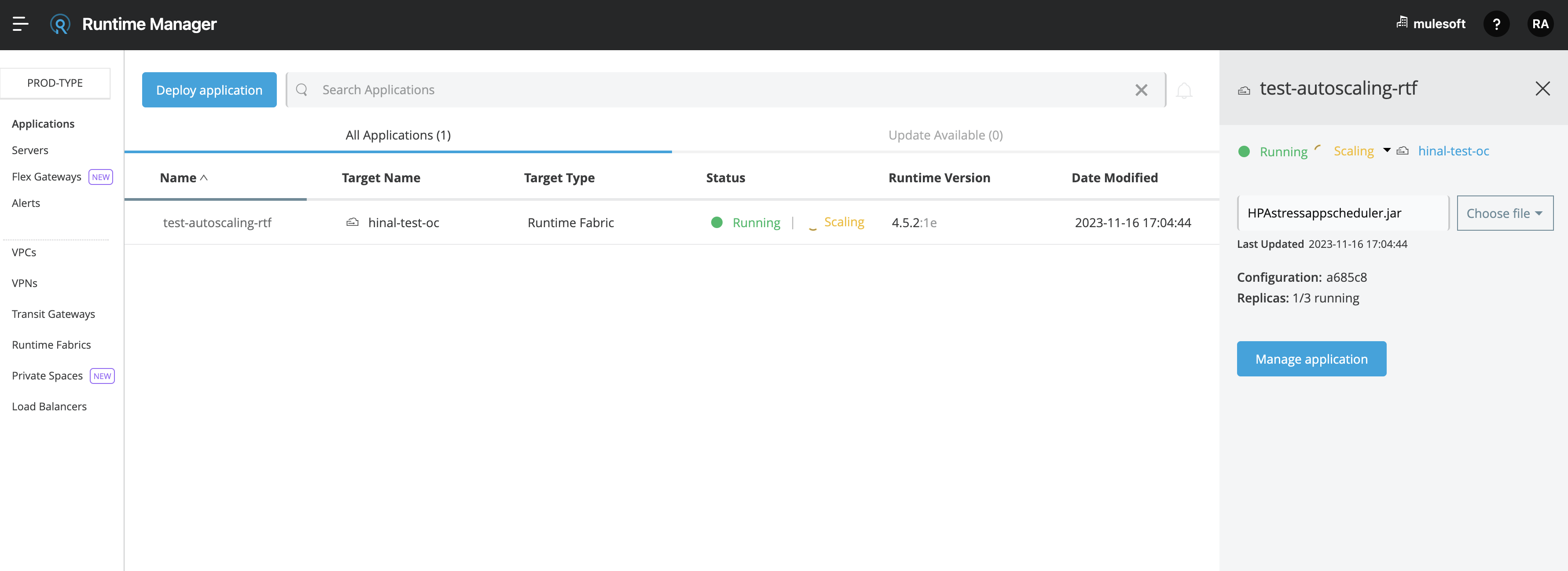
自動スケーリングの状況とログ
自動スケーリングイベントが発生し、水平自動スケーリングを設定している Mule アプリケーションがスケールアップされたら、Runtime Manager UI のアプリケーションの詳細ウィンドウで [View status (状況を表示)] をクリックして、[Scaling (スケーリング)] 状況を確認できます。
また、アクセス管理の [Audit logs (監査ログ)] では、自動スケーリングイベントがいつ発生したかを追跡できます。アプリケーションデプロイメントのスケーリングが発生するたびに、製品 [Runtime Manager] の下に [Anypoint Staff] ユーザーによる監査ログがパブリッシュされます。このログでは、[Action (アクション)] は [Scaling (スケーリング)] に設定され、[Object (オブジェクト)] はアプリケーション ID に設定されています。

次に、ログペイロードの例を示します。
{"properties":{"organizationId":"my-orgID-abc","environmentId":"my-envID-xyz","response":{"message":{"message":"Application id:my-appID-123 scaled DOWN from 3 to 2 replicas.","logLevel":"INFO","context":{"logger":"Runtime Manager"},"timestamp":1700234556678}},"deploymentId":"my-appID-123","initialRequest":"/organizations/my-orgID-abc/environments/my-envID-xyz/deployments/my-appID-123/specs/my-specID-456"},"subaction":"Scaling"}さらに、ターミナルで次の kubectl コマンドを実行することで、スケールアップされたレプリカの起動と Mule アプリケーションのレプリカ数を追跡できます。
kubectl get events | grep HorizontalPodAutoscalerクラスター内で発生したイベントを取得するには、Kubernetes で kubectl get events コマンドを使用します。このコマンドを実行すると、ポッドの作成、削除、その他の重要なイベントなど、クラスター内で実行されるさまざまなアクティビティや変更に関する情報が表示されます。
grep コマンドを使用すると、kubectl get events の出力を文字列 HorizontalPodAutoscaler を含む行に絞り込むことができます。次の例は、HorizontalPodAutoscaler に関するイベントを含むコマンド出力を示しています。HPA によってトリガーされた再スケーリング操作の成功に関する情報が表示されています。
# kubectl get events | grep HorizontalPodAutoscaler
5m20s Normal SuccessfulRescale HorizontalPodAutoscaler New size: 4; reason: cpu resource utilization (percentage of request) above target
5m5s Normal SuccessfulRescale HorizontalPodAutoscaler New size: 8; reason: cpu resource utilization (percentage of request) above target
4m50s Normal SuccessfulRescale HorizontalPodAutoscaler New size: 10; reason: