拡張性ベンチマーク
Runtime Fabric は中核となる Kubernetes (K8s) ソフトウェアであり、Runtime Fabric のハードウェアとソフトウェアの要件に準拠するすべての K8s 環境で同じように動作します。
スケールリミット
次のスケールリミットは、Amazon Elastic Kubernetes Service (Amazon EKS) クラスターで評価されています。
| 制限事項 | 説明 | Runtime Fabric による適用 |
|---|---|---|
Runtime Fabric でのデプロイメント |
最適なパフォーマンスを保証するため、任意のインスタンスにおいて Runtime Fabric が管理するデプロイメントの最大数は 8000 を超えないようにしてください。 |
推奨 |
水平ポッド自動スケーリング (HPA) |
Amazon EKS で Runtime Fabric を使用する場合、レプリカ数を 1 から 8 にスケーリングすると、トラフィック障害が発生する可能性が約 0.09% あります。このようなエラーはポッドスケーリング期間に固有のものであるため、スケーリング操作中にトラフィック障害が発生する可能性があります。 |
Runtime Fabric の機能やアプリケーションデプロイメントの管理は以下に左右されません。
-
各アプリケーションのサイズ
-
ワーカーノードのサイズ
-
ワーカーノードあたりの実行されているポッド数
Runtime Fabric は K8s ベースであり、クラウドネイティブのオーケストレーションプリンシパルを使用しているため、指定されたデプロイメントの設定に従って動作します。
評価されたメトリクス
次の評価されたメトリクスを確認して、ほぼ空のクラスターと 8000 個のデプロイを実行しているクラスターを比較した場合のさまざまな管理メトリクスを把握してください。使用されているクラスター設定は、AWS EKS クラスター上の Runtime Fabric です。
| 設定 | 説明 |
|---|---|
VPC とノードグループ |
eksctl から実行されるデフォルトの設定。3 つのサブネット (ノードグループごとに 1 つのサブネット)、NAT ゲートウェイ。 |
AWS NLB |
Nginx 作成時に Helm チャートを介して装備。 |
ノードの自動スケーラー |
推奨 3 GB (メモリ)/200m vCore (要求==上限) |
ワーカー |
m5.4x の大きさ、ワーカーノードグループ |
監視 |
固定、1 つのノード、Prometheus、監視ノードグループ、m5.2x の大きさ |
イングレス |
固定、2 つのノード、Nginx、イングレスノードグループ、m5.4x の大きさ |
Runtime Fabric の再起動レイテンシー
次の画像は、顧客またはクラスターのアップグレードによって呼び出された場合に Runtime Fabric エージェントが再起動に要する時間を示しています。
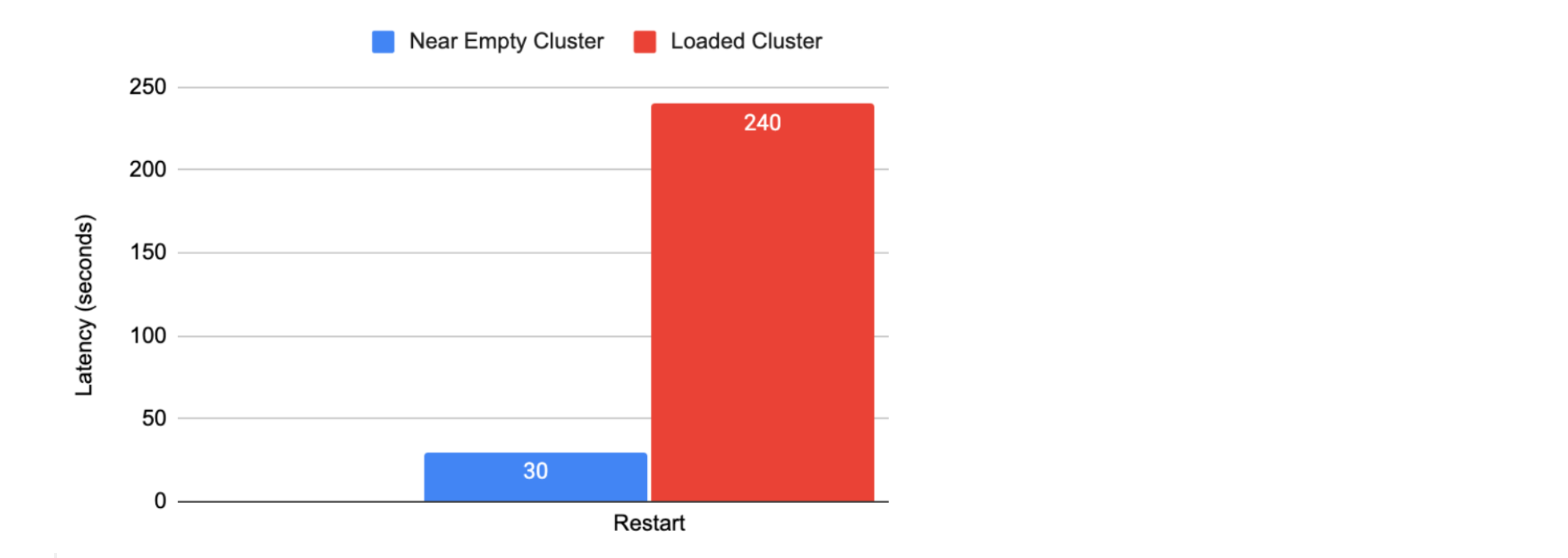
Runtime Fabric は、デプロイメントの量に関係なくアプリケーションの作成に約 190 秒を要します。 次の表に、Mule アプリケーションの起動、停止、削除に要する時間を示します。
| アプリケーション操作 | ほぼ空のクラスター | 負荷あり |
|---|---|---|
起動のレイテンシー |
~110 秒 |
158 秒 |
停止のレイテンシー |
~10 秒 |
20 秒 |
削除のレイテンシー |
~9 秒 |
~28 秒 |
次の表に、不正なノードがある場合に node cordon 操作を再開するのに要する時間を示しています。
| ノード操作 | 空のクラスター | 負荷ありのクラスター |
|---|---|---|
Cordon |
~2 秒 |
~2 秒 |
Drain process |
~4 秒 |
~35 秒 |
考慮事項
次のスケールの考慮事項を確認してください。
-
Runtime Fabric エージェントは大規模なデプロイメントのクラスターを管理する場合に必要なメモリや CPU の量がデフォルトよりも多くなり、これらの値は次の表の情報を使用して変更できます。8000 件のデプロイメントがあるクラスターでは、少なくとも次の量を使用してください。
クラスターの推奨 デフォルト 200 個のノード/8000 個のアプリケーションリソース設定 エージェントリソース
メモリは 200Mi を要求、500Mi が上限。CPU は 100m を要求、1vCore が上限。
1000Mi (メモリ)/1vCore (要求 == 上限)
デーモンリソース
メモリは 200Mi を要求、300Mi が上限。CPU は 150m を要求、200m が上限。
1200Mi (メモリ)/500m (要求 == 上限)
-
デフォルトのリソース割り当てでは、最大 2,000 個のアプリケーション/75 個のノードがサポートされています。
-
Runtime Fabric を使用した大規模のデプロイメントのオーケストレーションのパフォーマンスはデプロイメントの量に反比例します。
-
RTFCTL クラスターは特定のベンチマークに対してのみサポートされています。
-
Helm を使用すると、クラスターのサイズのために Runtime Fabric エージェントにカスタマイズされたリソースが必要な任意のクラスターを管理できます。
-
Runtime Fabric エージェントのリソース制限をスケールアップする場合、必要に応じて要求を増やすことを検討してください。
-
制限を完全に削除してコンテナを無制限に実行することは避けてください。OpenShift Operator の場合、制限を削除すると、エージェントの制限設定がデフォルトに設定されます。
-
resource-cache および mule-clusterip-service サービスはステートレスであるため、水平方向にスケールできます。