Mule アプリケーションでのストリーミング
Mule 4 では、データストリームを処理するためのフレームワークが追加されています。Mule 4 での変更点を理解するためには、従来はデータストリームがどのようにコンシュームされていたかを理解することが必要です。
-
データストリームは 1 回しかコンシュームできません。
次の例は、ファイルに書き込む本文 (ペイロード) を持つ POST メソッドを受け取る HTTP Listener ソースのフローを示しています。このフローにより、最初のファイルは正しく書き込まれますが、2 つ目のファイルはコンテンツが空になります。これは、ストリームをコンシュームする各コンポーネントが、新しいストリームを受信することを予期しているためです。最初の File Write 操作がストリームをコンシュームすると、2 つ目の File Write 操作は空のストリームを受け取ります。そのため、2 つ目の操作はファイルに書き込むコンテンツを持ちません。
 Figure 1. Mule 3 のストリーミング: ファイルの書き込み
Figure 1. Mule 3 のストリーミング: ファイルの書き込み次の例は、DataWeave 変換の後でペイロードをログに記録しようとすると、同じような結果となります。HTTP Listener 操作は、ペイロードストリームを受け取り、ストリームが Transform Message コンポーネントに達した時点ではまだメモリに残っているため、コンポーネントはストリームをコンシュームします。Transform Message コンポーネントでコンテンツをコンシュームした後で、2 つ目の Logger は空のストリームを受信します。
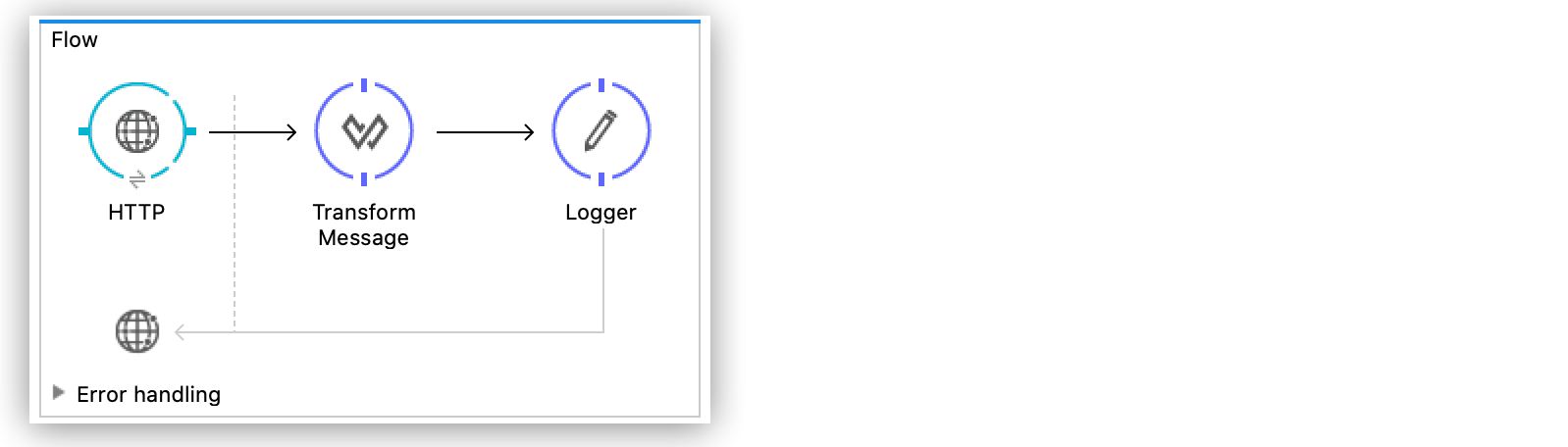 Figure 2. Mule 3 のストリーミング: ペイロードのログへの記録
Figure 2. Mule 3 のストリーミング: ペイロードのログへの記録
-
データストリームを同時にコンシュームすることはできません。
次の例は、Scatter-Gather ルーターを使用してデータストリームを分割し、ペイロードのログへの記録とファイルへの書き込みを同時に実行するフローを示しています。異なるプロセッサーチェーンでデータストリームのコンテンツを同時に処理することはできないため、アプリケーションはストリームの一部をファイルで受け取り、残りをログで受け取ります。
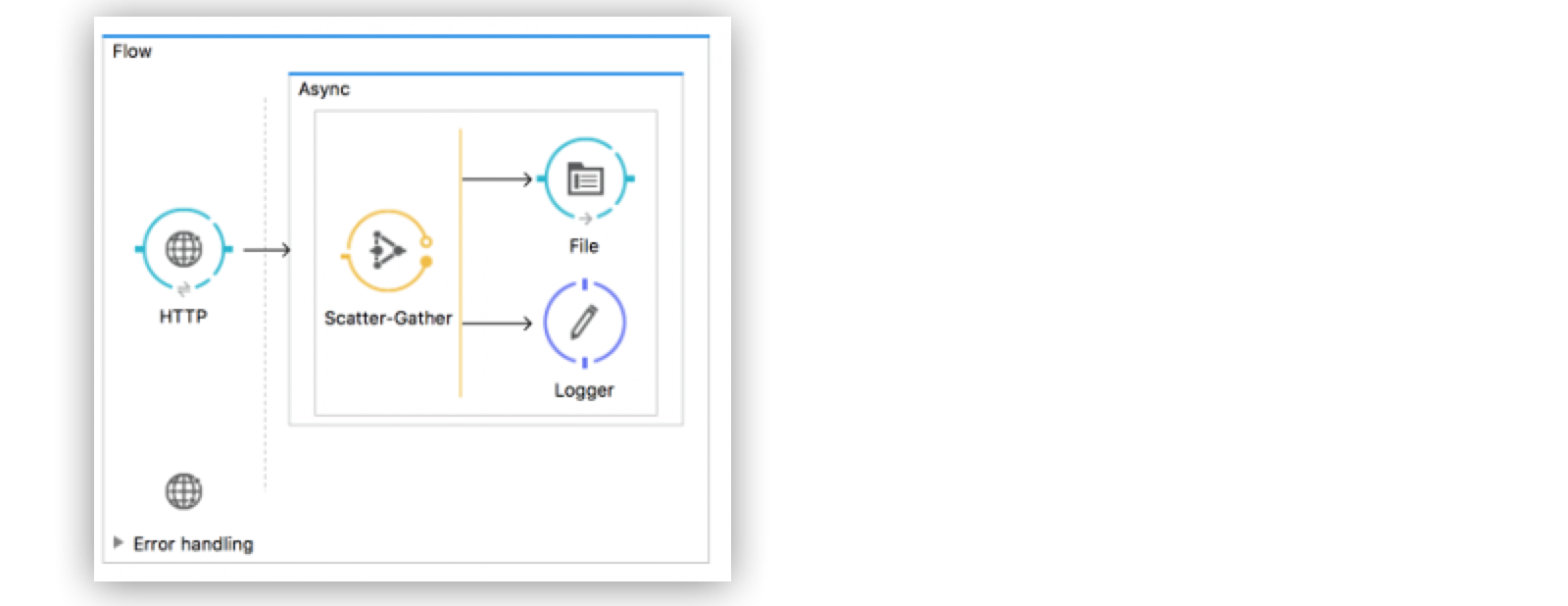 Figure 3. Mule 3 のストリーミング: データストリームのコンシューム
Figure 3. Mule 3 のストリーミング: データストリームのコンシューム
反復可能ストリーム
Mule 4 では、ストリームを処理するためのデフォルトフレームワークとして反復可能ストリームが追加されています。反復可能ストリームを使用すると、次の操作を実行できます。
-
ストリームを複数回読み込むことができます。
-
ストリームに同時にアクセスできます。
コンポーネントがストリームをコンシュームすると、Mule はそのコンテンツを一時バッファに格納します。以後、ランタイムはストリームのコンテンツをテンポラリーバッファからコンポーネントに供給することで、すでにストリームが他のコンポーネントによって何度コンシュームされていようとも、各コンポーネントが完全なストリームを受信できるようにします。この処理は自動的に行われるため、ユーザーが特別な設定をする必要はなく、再びアクセスするためにストリームを別の場所に保存するための回避策を考える必要はありません。この設定により、上記の 3 つの Mule アプリケーションの例の問題のうち、2 つが自動的に解決されます。
すべての反復可能ストリームは並列アクセスをサポートしています。つまり、各コンポーネントが異なるスレッドで実行されているときに、2 つのコンポーネントが同じストリームを読み取ろうとしても心配する要はありません。Mule は、コンポーネント A がストリームを読み込んでもコンポーネント B に対して一切の副作用を発生させないことを自動的に保証します。この動作により、3 番目の例で説明しているようなタスクを実行できます。
ストリーミング戦略
ストリーミング戦略を使用して、Mule によるストリームの処理方法を設定できます。
ファイルに格納された反復可能ストリーム
ファイルストレージは Mule 4 のデフォルトのストリーミング戦略です。
|
ファイルストレージは Mule Enterprise Edition (Mule EE) でのみ使用できます。 |
この戦略では、初期設定として、メモリ内のバッファサイズとして 512 KB を使用します。ストリームが大きくなると、この戦略で一時ファイルがディスクに作成され、メモリをオーバーフローさせることなく、コンテンツを格納します。
大きいまたは小さいファイルを処理する必要がある場合、バッファサイズ (inMemorySize) を変更してパフォーマンスを最適化できます。
-
バッファサイズを大きく設定すると、ランタイムがバッファをディスクに書き込む回数を減らすことができるため、パフォーマンスが向上します。ただし、アプリケーションが同時に処理できる要求の数が制限されます。
-
バッファサイズを小さく設定すると、メモリの負荷が減ります。
また、バッファの測定の単位も設定できます (bufferUnit)。
たとえば、常に約 1 MB のファイルを読み取ることが分かっているのであれば、1 MB のバッファを設定できます。
<file:read path="bigFile.json">
<repeatable-file-store-stream
inMemorySize="1"
bufferUnit="MB"/>
</file:read>あるいは、処理するファイルのサイズが 10 KB を超えることがないということが分かっていれば、メモリを節約できます。
<file:read path="smallFile.json">
<repeatable-file-store-stream
inMemorySize="10"
bufferUnit="KB"/>
</file:read>パフォーマンステストにより、この戦略のデフォルトである 512 KB のバッファサイズ設定が、ほとんどのシナリオにおいてパフォーマンスに大きな影響を与えないことが分かっています。 ただし、ニーズに合った適切なバッファサイズの設定を見つけるには、テストを実行する必要があります。
メモリ内の反復可能ストリーム
メモリ内戦略は、Mule Kernel (以前の名称は Mule Runtime Community Edition) のデフォルト設定です。
この戦略のデフォルトのバッファサイズは 512 KB です。大きいストリームでは、設定した最大バッファサイズに達するまで、デフォルトの拡張単位である 512 KB ずつバッファが拡張されます。ストリームが最大バッファサイズを超えると、アプリケーションはエラーとなります。
この動作は、初期バッファサイズ (initialBufferSize)、バッファの拡張単位 (bufferSizeIncrement)、最大バッファサイズ (maxInMemorySize)、バッファサイズ値の測定単位 (bufferUnit) を設定することでカスタマイズできます。
たとえば、次の例では、メモリ内の反復可能ストリームの初期バッファサイズを 512 KB、拡張単位を 256 KB、そしてメモリに読み込めるコンテンツの最大サイズを 2000 KB (2 MB) に設定しています。
<file:read path="exampleFile.json">
<repeatable-in-memory-stream
initialBufferSize="512"
bufferSizeIncrement="256"
maxInMemorySize="2000"
bufferUnit="KB"/>
</file:read>パフォーマンステストにより、この戦略のデフォルトである 512 KB のバッファサイズと 512 KB の拡張単位が、ほとんどのシナリオにおいてパフォーマンスに大きな影響を与えないことが分かっています。ただし、テストを実行してニーズに合った適切なバッファサイズとサイズの拡張単位の設定を見つける必要があります。
InputStream または Streamable コレクションを返す Mule 4 のすべてのコンポーネントで、反復可能ストリームがサポートされています。これらのコンポーネントには以下が含まれています。
-
File Connector
-
FTP Connector
-
Database Connector
-
HTTP Connector
-
Sockets Connector
-
SalesForce Connector
オブジェクトのストリーミング
Anypoint Connector が自動ページングを使用するように設定されている場合、Mule 4 によって、反復可能自動ページングフレームワークを使用してページングされたコネクタ出力が自動的に処理されます。コネクタがオブジェクトを受信し、Mule がオブジェクトを保存するために設定可能なメモリ内バッファを設定するため、このフレームワークは反復可能ストリームと似ています。ただし、反復可能ストリームはバッファサイズをバイト単位で測定するのに対して、ランタイムはオブジェクトを処理するときにインスタンス数を使用してバッファサイズを測定します。
| オブジェクトをストリーミングすると、メモリ内のバッファサイズはインスタンス数で測定されます。 |
反復可能自動ページングのメモリ内のバッファサイズを計算する場合は、メモリ不足にならないように、各インスタンスで使用するメモリ量を見積もる必要があります。
反復可能ストリームと同じように、さまざまな戦略を使用して、Mule による反復可能自動ページングの処理方法を設定できます。
反復可能ファイルストア (イテラブル)
この設定は、Mule Enterprise Edition のデフォルトです。この戦略では、デフォルトの設定済みメモリ内バッファとして 500 個のオブジェクトを使用します。このバッファサイズよりも多くの結果がクエリで返されると、Mule はオブジェクトをシリアル化して、ディスクに書き込みます。メモリ内のバッファに格納されるオブジェクト数は設定可能です。メモリ内に保存するオブジェクトの数が多いほど、ディスクへの書き込みが減るため、パフォーマンスが向上します。
たとえば、次のように、SalesForce Connector のクエリに対してメモリ内のバッファサイズを 100 個のオブジェクトに設定できます。
<sfdc:query query="dsql:...">
<ee:repeatable-file-store-iterable inMemoryObjects="100"/>
</sfdc:query>MuleSoft ではシリアル化に Kryo フレームワークを使用します。これは、標準の Java シリアル化では、Serializable インターフェースを実装するためにシリアル化されたオブジェクト (およびそのすべての参照されるオブジェクト) が必要になるためです。Kryo シリアライザーにはこの制限がないため、標準の Java のシリアル化ではシリアル化できない一部のオブジェクトをシリアル化できます。ただし、Kryo ですべてをシリアル化できるわけではありません。たとえば、org.apache.xerces.jaxp.datatype.XMLGregorianCalendarImpl のインスタンスは Kryo を使用してもシリアル化できません。MuleSoft では、オブジェクトを単純にすることをお勧めします。
|
このオプションは Mule EE でのみ使用できます。 |
反復可能メモリ内 (イテラブル)
この設定は Mule Kernel のデフォルトであり、デフォルトのバッファサイズを 500 個のオブジェクトに設定します。クエリ結果がこのサイズを超えると、設定された最大バッファサイズに到達するまで、デフォルトの拡張単位である 100 個ずつバッファが拡張されます。ストリームがこの制限を超えると、アプリケーションは失敗します。
初期バッファサイズ (initialBufferSize)、バッファの拡張単位 (bufferSizeIncrement)、そして最大バッファサイズ (maxBufferSize) をカスタマイズできます。
たとえば、次の設定ではメモリ内のバッファサイズを 100 個のオブジェクト、拡張単位を 100 個のオブジェクト、最大バッファサイズを 500 個のオブジェクトに設定します。
<sfdc:query query="dsql:...">
<repeatable-in-memory-iterable
initialBufferSize="100"
bufferSizeIncrement="100"
maxBufferSize="500" />
</sfdc:query>反復可能ストリームの無効化
反復可能ストリームは、non-repeatable-stream 戦略と non-repeatable-iterable 戦略で無効化できます。使用する戦略は、ストリームの種別によって決まります。
このオプションは、ストリームを複数回コンシュームする必要がないことが確実であり、パフォーマンスとリソース消費を非常に厳密に最適化する必要がある場合にのみ使用してください。
その場合には、次の点に注意してください。
-
反復可能ストリームを無効化するとパフォーマンスは向上しますが、向上する程度はストリームのサイズに比例します。大きなストリームを使用していない限り、アプリケーションの他の部分を調整した方がパフォーマンスはより大きく向上します。
-
反復可能ストリームを無効化すると、ストリームは 1 回しか読み取ることができなくなります。フローには、明示的にそのように指定していなくても、ストリーム全体をコンシュームする必要のあるコンポーネントが存在する可能性があります。たとえば、Cache コンポーネント (
<ee:cache>)、Transform Message コンポーネント (<ee:transform>) による一部の変換、For Each コンポーネント (<foreach>) による JSON 配列の反復処理、そしてストリームに直接、または式を通してアクセスする他のコンポーネントなどです。