高可用性および障害回復
計画しているかどうかに関わらず、インフラストラクチャやアプリケーションのダウンタイムは、いつでも、どこからでも、どのような形でも発生する可能性があります。テクノロジーの停止、設備の破壊、人材の損失、重要なサードパーティサービスの損失の際に組織の稼働を継続できる能力は、ビジネスへの取り返しのつかないダメージを防ぐために不可欠です。世界的に E コマースへのシフトが進み、アプリケーションの 365 日 24 時間のアップタイムへの依存が高まっているため、高可用性 (HA) と障害回復 (DR) は、組織の財政状態に影響を及ぼします。
次の表は、少しのダウンタイムでも積み上げれば組織に悪影響を及ぼす可能性があることを示しています。
| アップタイム率 | ダウンタイム率 | 週間ダウンタイム | 年間ダウンタイム |
|---|---|---|---|
99% |
1% |
1.68 時間 |
3.65 日 |
99.9% |
0.1% |
10.1 分 |
8.75 時間 |
99.99% |
0.01% |
1 分 |
52.5 分 |
99.999% |
0.001% |
6 秒 |
5.25 分 |
高可用性と障害回復の比較
-
高可用性 (HA) - システムコンポーネントの障害が発生した際にシステムがアクセス可能な状態を維持する能力の基準。一般に HA は、システムに複数レベルのフォールトトレランス機能や負荷分散機能を構築することで実装されます。
-
障害回復 (DR) - 自然災害 (洪水、竜巻、地震、火事など) や人災 (停電、サーバー障害、設定の誤りなど) が発生した後に、システムを以前の許容される状態に復元するプロセス。
どちらも全体的な可用性を高めますが、注目すべき違いは、HA では一般にサービスが停止しないことです。HA はサービスを保持し、DR はデータを保持しますが、DR では通常、DR 計画が実行されシステムが復元するまでの間にわずかなサービス停止が発生します。
HA および DR 戦略のための Mule のデプロイ
HA および DR 戦略に対応するために、さまざまなトポロジーで Mule Runtime をデプロイできます。1 つの方法は、クラスタリングを使用することです。これについては、このドキュメントの後のセクションで説明します。Mule 高可用性クラスタリングでは、Mule の基本的なフェールオーバー機能が提供されます。
JVM またはハードウェアの致命的な障害が発生したり、メンテナンスのためにオフラインになったりしたために、プライマリ Mule Runtime が使用できなくなった場合、バックアップ Mule Runtime が即座にプライマリノードになり、障害の発生したインスタンスが中断したところから処理を再開します。
システム管理者が障害が発生した Mule Runtime を回復してオンラインに戻すと、そのサーバーは自動的にバックアップノードになります。
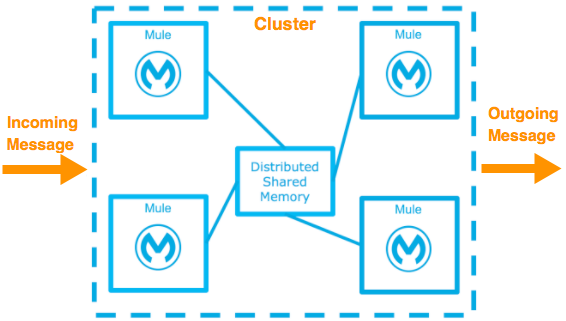
シームレスなフェールオーバーは、クラスタリングされた Mule Runtime ですべての一時的な状態の情報を共有する次のような分散メモリストアによって実現します。
-
SEDA サービスイベントキュー
-
メモリ内メッセージキュー
Mule アプリケーションをビルドする場合、目的の可用性、フォールトトレランス、パフォーマンス特性を実現するために、アプリケーションの最適な設計方法についてよく考えることが重要です。
効果的な SLA の作成
サービスレベル契約 (SLA) では、何が許容されるかについて具体的な定義の概要を定めます。
高可用性の基本的な定義は、サービスが起動して機能している、つまり適切に要求と応答を処理しているということです。これは、サービスが常に完全な機能を維持して稼働しているという意味ではありません。高可用性を考慮して設計されたシステムは、中断を防ぎ、第一に停止の発生を防ぎます。SLA では、すべての関係者に対する期待事項を定めます。
SLA 要件
-
単一障害点が排除されている
-
トラフィック/要求がリダイレクト/処理される
-
障害の検出
たとえば、基本的なサービスの SLA は次のようになります。
-
サービスの通常の運用では、1 秒あたり 1000 件のトランザクションを応答時間 1 秒で処理する。
-
1 年間の合計ダウンタイムは 0.5% (1.83 日) とする。
-
最小許容サービス影響レベルは、1 秒あたり 100 件のトランザクション、応答時間 1 秒を 1 週間に 2 時間とする。
関連情報
高可用性オプション
高可用性は、クラスタリングの使用やノードの負荷分散によって実現できます。定義された SLA に応じて、Mule には 4 つの HA オプションがあります。
| 多くの場合、これらのオプションは障害回復戦略に関連します。 |
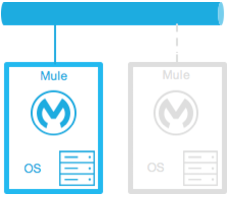
コールドスタンバイ
| 図 | 説明 | ダウンタイム |
|---|---|---|
|
Mule 環境がインストールされ、設定されています。ただし、1 つ以上のオペレーティングシステムが実行中ではありません。これは、本番システム/仮想マシンのバックアップとして使用できます。停止が検出された後にオペレーティングシステムの環境と Mule Runtime が起動されます。 |
あり。環境を起動してトラフィックを転送するのにかかる時間。 |
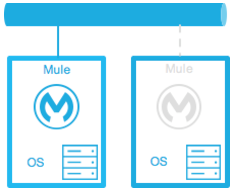
ウォームスタンバイ
| 図 | 説明 | ダウンタイム |
|---|---|---|
|
Mule 環境がインストールされ、設定されています。ただし、Mule Runtime は実行されておらず、オペレーティングシステムのみが実行されています。停止が検出された後に Mule Runtime が起動されます。 |
少ない。Mule Runtime を起動し、トラフィックを環境に転送するのにかかる時間。 |
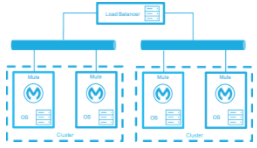
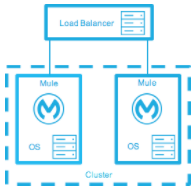
オンプレミスデプロイメントモデルの高可用性
アクティブ-アクティブクラスタリングデプロイモデル
クラスタリングされ負荷が分散されている環境の 2 つのノードで、応答時間 1 秒で 1,500 TPS をサポート可能です。この状態で、SLA の通常運用の条件を満たしています。ノードに障害が発生すると、サービスは影響を受けます。ただし、ノードは応答時間 1 秒で 700 TPS を処理でき、これは許容される影響レベルを大きく上回っているため、この障害による影響は SLA に違反しません。
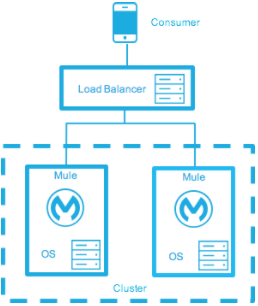
複数の Mule ノードに負荷を均等に分散させます。
-
すべてのノードの機能は同じです。
-
すべてのノードが同時にアクティブです。
コスト
SLA 要件によって異なります。このモデルでは、SLA を満たすために 2 つのノードが必要です。SLA の許容可能なサービス影響が通常運用で指定されているのと同じ条件に変更されると、1 つのノード障害に対応するために環境に少なくとも 3 つのノードが必要です。2 つ以上のノードが実行中である状態を維持できない確率によっては、さらに多くのノードが必要な場合もあります。
アクティブ-アクティブクラスタリングフォールトトレランスデプロイモデル
フォールトトレランスの基本的な定義は、システム内の障害がサービスに全く影響を及ぼさないということです。これは、サービスの影響とダウンタイムへの耐性があるという点で高可用性とは異なります。
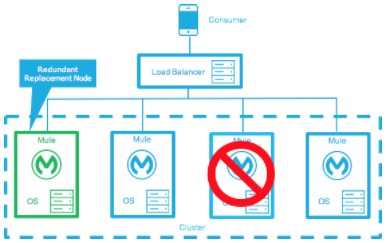
フォールトトレランスでは、高可用性とは異なり、コンポーネント障害後にアプリケーションが中断なく機能し続けられるようにするための追加のリソースが提供されます。フォールトトレランス環境は高可用性環境よりもコストがかかります。
フォールトトレランスの度合を判断するには、システム障害の確率が必要です。高可用性のセクションで取り上げた SLA の例を使用して、最小許容サービス影響レベルが通常運用の要件と同じであるとします。
新しい全体的な SLA では、システムが 1 秒あたり 1000 件のトランザクションを処理し、応答時間 1 秒、ダウンタイムなし、サービスへの影響なしにする必要があります。
2 つ以上のノードで障害が発生する確率が低ければ、このアーキテクチャに必要なノードは 3 つで済みます。一方、2 つ以上のノードで障害が発生する確率が許容できないほど高い場合は、複数障害に対応するために 4 つ以上のノードが必要になります。
コスト
定義された SLA を満たすために冗長性が必要なので、よりコストがかかります。
ゼロダウンタイムデプロイモデル
目標は、SLA に影響を与えずに環境をすばやく変更することです。この変更には、インフラストラクチャやインフラストラクチャ上で実行中のアプリケーションのアップグレードを含みます。通常、ゼロダウンタイムデプロイでは、新旧のシステムが短期間共存するサイドバイサイドのデプロイが使用されます。これは、機能の低下や完全なダウンタイムが発生するインプレースのデプロイとは対照的です。
Gartner は連続稼働を次のように定義しています。「データ処理システムの特性で、定期メンテナンスなどの計画されたダウンタイムを低減または排除すること。24 時間 365 日稼働の 1 つの要素。」
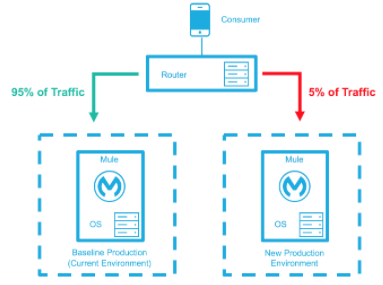
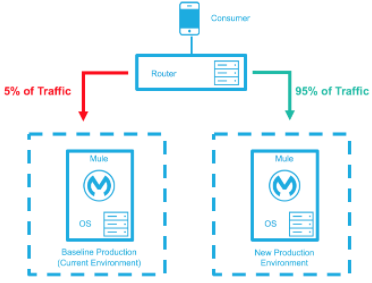
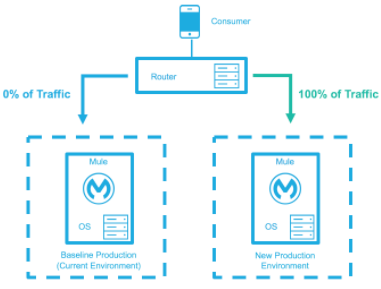
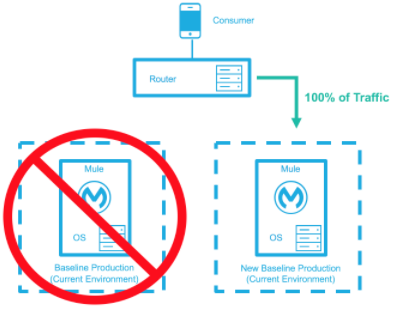
ベースライン本番環境は、現在稼働中の環境です。変更 (ランタイムのアップグレード、設定、新しいアプリケーションなど) された新しい環境が作成されます。 ごく一部のトラフィックが新しい環境に送信され、新しい環境の信頼度が高まるにつれて増えていきます。新しい環境が完全稼働状態 (トラフィックの 100% を処理) になるまで、ベースライン本番環境は引き続き使用されます。新しい環境がすべてのトラフィックを受け入れるようになると、それが新しいベースライン本番環境となり、以前のベースライン本番環境は終了します。
下の例では、各環境は同じ数の Mule Runtime とコアを使用していると想定しています。実際には新しい環境がベースライン環境よりも多くなったり少なくなったりする可能性もあります。
| デプロイの手順 | 図 |
|---|---|
新しい本番環境がデプロイされ、ごく一部のトラフィックが新しい環境に転送されます。 |
|
新しい環境の信頼度が高まり、転送されるトラフィックが増えます。 |
|
すべてのトラフィックが新しい環境に転送されます。 |
|
すべてのトラフィックが新しい環境に転送され、新しい環境がベースライン本番環境に昇格します。以前のベースライン環境は終了します。 |
|
コスト
このデプロイ方法では、一時的にサービスの容量が追加される場合があります (数分間、数時間、または数日間)。
障害回復
あなたの会社は、IT の緊急事態が発生した後にどれだけ迅速に業務に戻ることができますか?
障害回復は、自然災害や人災が発生した後に、システムを以前の許容される状態に復元するプロセスです。ビジネス要件に沿って適切な DR 戦略を選択することが重要です。DR では、目標復旧時間 (RTO) や目標復旧時点 (RPO) などの測定可能な特性を使用して DR 計画を推進します。
障害回復で重要なのは目標復旧時点 (RPO) と目標復旧時間 (RTO) です。RPO は、IT 障害の後に戻る時点です。たとえば、24 時間ごとにバックアップしている場合、RPO は最長で 24 時間前になります。一方、RTO は、どれだけ迅速に RPO に戻して、業務に戻れるかということです。これには、プライマリ機器が機能しなくなったときに、予備の機器でバックアップの実行を開始する時間などの活動が含まれます。
システムバックアップは、しっかりとした障害回復プログラムの重要な要素です。回復には、コールド、ウォーム、ホットの 3 種類があります。
| 用語 | 定義 | 例 |
|---|---|---|
目標復旧時間 (RTO) |
どれだけ迅速にこのアセットを復旧する必要があるか? |
1 分? 15 分? 1 時間? 4 時間? 1 日? |
目標復旧時点 (RPO) |
このアセットはどれだけ新しいものに復旧する必要があるか? |
データロスなし、15 分の有効期限? |
CloudHub を使用した障害回復についての詳細は、「CloudHub High Availability and Disaster Recovery (CloudHub の高可用性と障害回復)」を参照してください。
ステートレスなインテグレーション
一般的な設計原理として、インテグレーションが本質的にステートレスであることが常に重要です。つまり、さまざまなクライアントの呼び出しや実行 (スケジュールされたサービスの場合) の間でトランザクション情報を共有しないということです。システムの制約によって一部のデータをミドルウェアで管理する必要がある場合、そのデータはデータベースやメッセージングキューなどの外部ストアで保持し、ミドルウェアのインフラストラクチャやメモリの内部では保持しないようにする必要があります。拡張 (特にクラウドでの拡張) の際には、各ワーカー/ノードで使用される状態やリソースは他のワーカーとは独立している必要があることに注意することが重要です。このモデルを使用することで、パフォーマンス、スケーラビリティ、信頼性が向上します。