レート制限: SLA ベースのポリシー
ポリシー名 |
レート制限 SLA |
概要 |
SLA に基づいた期間中に処理される要求の最大数を定義することで、API へのアクセスを監視します。 |
カテゴリ |
サービス品質 |
使用可能な最小 Mule バージョン |
v4.1.0 |
返される状況コード |
400 - 無効なクライアントログイン情報が返されたか、または SOAP v1.2 を使用する WSDL API によってクォータを超過しました (Mule のみ)。 |
401 - 指定されたクライアントログイン情報 (クライアント ID またはクライアントシークレット) が無効であるため、要求がブロックされました。 |
|
429 - クォータを超過しました。現在のウィンドウが完了するまで要求はブロックされます。 |
|
500 - 無効なクライアントログイン情報が返されたか、または SOAP v1.1 を使用する WSDL API によってクォータを超過しました (Mule のみ)。 |
概要
レート制限サービスレベル契約 (SLA) ポリシーにより、API が特定の期間中に受け取ることができる要求数を制限することで、API への受信トラフィックを制御できます。期間が終了する前にこの制限に達すると、ポリシーはすべての要求を拒否して、バックエンド API の負荷増大を回避します。
レート制限 SLA ポリシーを API に適用するには、先にその API と登録済みクライアントアプリケーションとの間でコントラクトを作成する必要があります。特定の期間中に API が受け取ることのできる要求の数は、API Manager の [contracts (コントラクト)] セクションで定義します。
各要求は、クライアント ID と (ポリシー設定によって) 省略可能なクライアントシークレットによって識別される必要があります。登録済みクライアントアプリケーションのクライアントログイン情報の取得方法は、「登録済みクライアントアプリケーションのクライアントログイン情報の取得」を参照してください。
また、Mule Runtime Engine (Mule) クラスターで実行するようにポリシーを設定することもできます。クラスターポリシー設定では、クォータはクラスター内のすべてのノードで共有されます。これらのオプションの詳細は、「例」を参照してください。
ポリシーのパラメーターの設定
Mule ゲートウェイ
UI からポリシーを API に適用するときに、環境に Mule アプリケーションがあるか非 Mule アプリケーションがあるかに基づいて、パラメーターのリストが表示されます。
ポリシーのパラメーターの設定
次のパラメーターが表示されます。
| パラメーター | 説明 | 例 |
|---|---|---|
Client ID Expression (クライアント ID 式) |
API のコントラクトについてクライアントアプリケーションの ID を解決する DataWeave 式 |
レート制限アルゴリズムは、ID ごとに 1 つだけ作成されます。
|
Client Secret Expression (クライアントシークレット式) |
API のコントラクトについてクライアントアプリケーションのクライアントシークレットを解決する DataWeave 式 |
省略可能な値です。
例: |
Distributed (分散) |
このフラグを有効にして相互接続されたランタイムを使用する場合、クォータはすべてのノード間で共有されます |
Expose Headers (ヘッダーを公開) |
Anypoint Service Mesh (非 Mule アプリケーション) のポリシーパラメーターの設定
レート制限 SLA ポリシーは、次の違いを除き、Anypoint Service Mesh (Mule 以外のアプリケーション) と同様に機能します。
-
このポリシーでは、ヘッダーを公開するオプションが提供されない
-
次の表で説明しているように、パラメーターを取得するクライアント ID とクライアントシークレットが異なる。
| 要素 | 説明 | 必須 |
|---|---|---|
Credentials Origin (ログイン情報の取得元) |
クライアント ID とクライアントシークレットのログイン情報の取得元:
|
はい |
Client ID Header (クライアント ID ヘッダー) |
API 要求のクライアント ID を抽出するヘッダー名 |
はい ([Credentials origin (ログイン情報の取得元)] を [Custom ヘッダー (カスタムヘッダー)] に設定する場合) |
Client Secret Header (クライアントシークレットヘッダー) |
API 要求のクライアントシークレットを抽出するヘッダー名 |
いいえ |
ポリシーのしくみ
レート制限 SLA ポリシーは、現在のウィンドウ (使用可能なクォータ) 内で要求数を監視し、使用可能なクォータが 0 より大きい場合にのみ、要求がバックエンドに到達できるようにします。
ウィンドウで使用可能なクォータはクライアントごとに別々に定義されるため、クライアントアプリケーションは API との間で SLA (コントラクト) を定義する必要があります。したがって、要求が SLA の制限内にあるかどうかを検証するには、要求からクライアント ID と必要に応じてクライアントシークレットを取得する手段を定義する必要があります。
クライアントアプリケーションと API との間でコントラクトを作成すると、API ゲートウェイは API Manager 設定を監視することで、自動的にこれらのコントラクトを管理します。さらに API ゲートウェイは、Anypoint Platform 管理プレーンで予期しないダウンタイムが発生した場合に備えて、高可用性戦略を実装します。
レート制限 SLA ポリシーの仕組みをわかりやすくするため、ID が「ID#1」のクライアントについて 10 秒ごとに 3 件の要求という設定で、ウィンドウ内のクォータに基づいて受信要求が許可または拒否される例を見てみましょう。
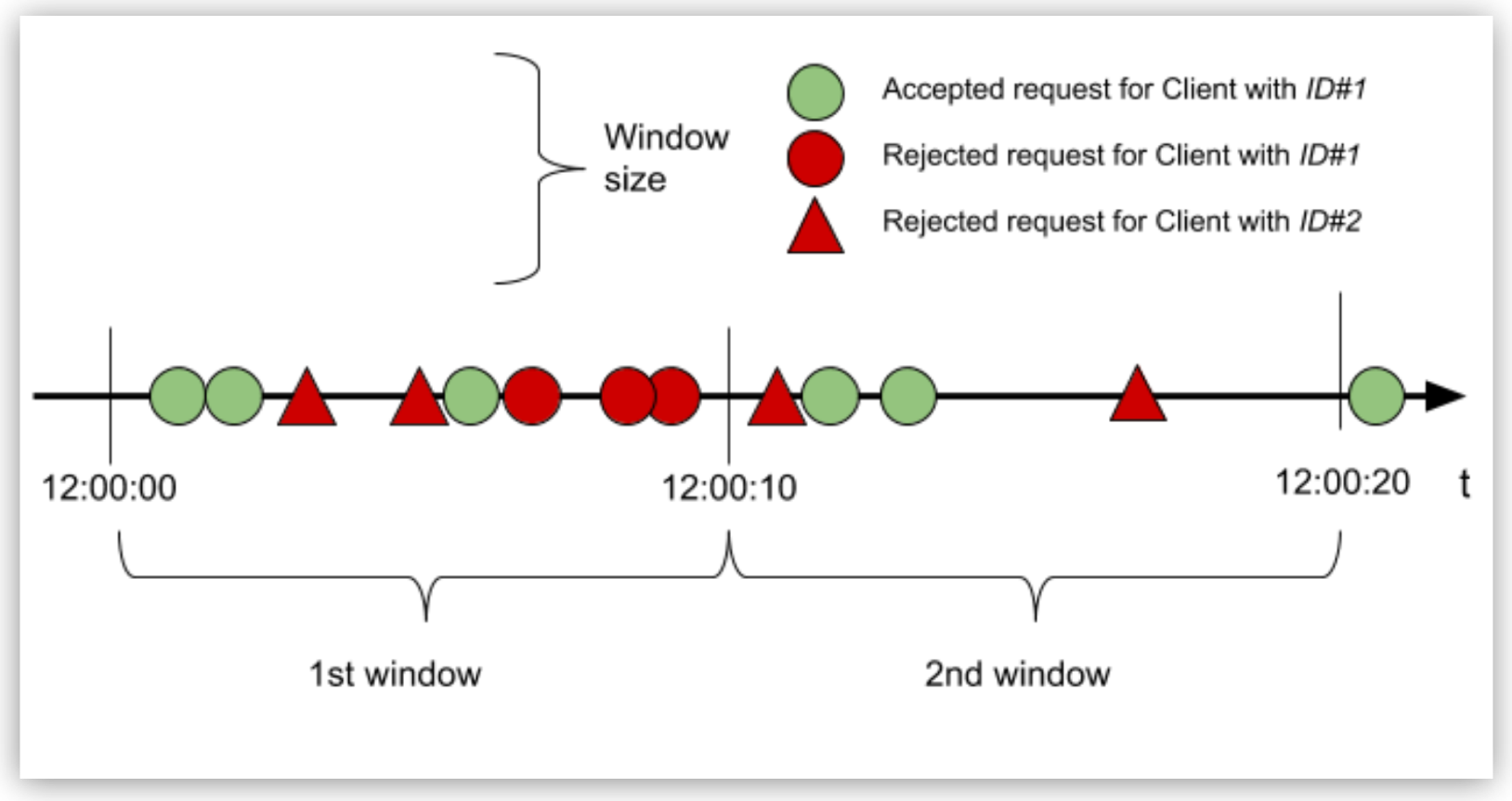
この例では、次のようになります。
-
ID が「ID#1」のクライアントの要求:
最初のウィンドウでは、3 番目の要求でクォータに達したため、以降の要求はウィンドウが終了するまで拒否されます。2 番目のウィンドウでは、3 件の要求のうち 2 件しか処理されていません。このウィンドウは終了したため、残りのクォータは未使用となります。
受け入れられた要求は API を経由してバックエンドに送られます。一方、拒否された要求は 429 status for HTTP (API が WSDL であれば 400 または 500) を返してバックエンドには到達しません。
-
ID が「ID#2」のクライアントの要求:
このクライアントは API との間で定義されているコントラクトを持たないため、すべての要求が拒否され、要求は 1 つも許可されません。
1 つの API は、それぞれ SLA が異なる複数のコントラクトを持つことができます。レート制限 SLA ポリシーは、コントラクトごとに 1 つのレート制限アルゴリズムを作成することで、各クライアントの使用可能なクォータ (およびウィンドウ) を別々に監視します。API に最初の要求が送られた時点で、遅延作成戦略によってアルゴリズムが作成されます。
例
クライアント ID#設定がクラスタリングされた場合に、クライアント ID#1 に対する 10 秒ごとに 3 件の要求のコントラクトがどのように機能するのかを見てみましょう (Mule のみ)。
12:00:00 ちょうどにリセットされ、長さが 10 秒で、ノード 2 台の Mule クラスターで実行されるウィンドウを考えてみましょう。両方のノードは同時にそれぞれのウィンドウを開始して終了し、クラスターではウィンドウごとにクライアント ID#1 で合計 3 件の要求が許可されます。
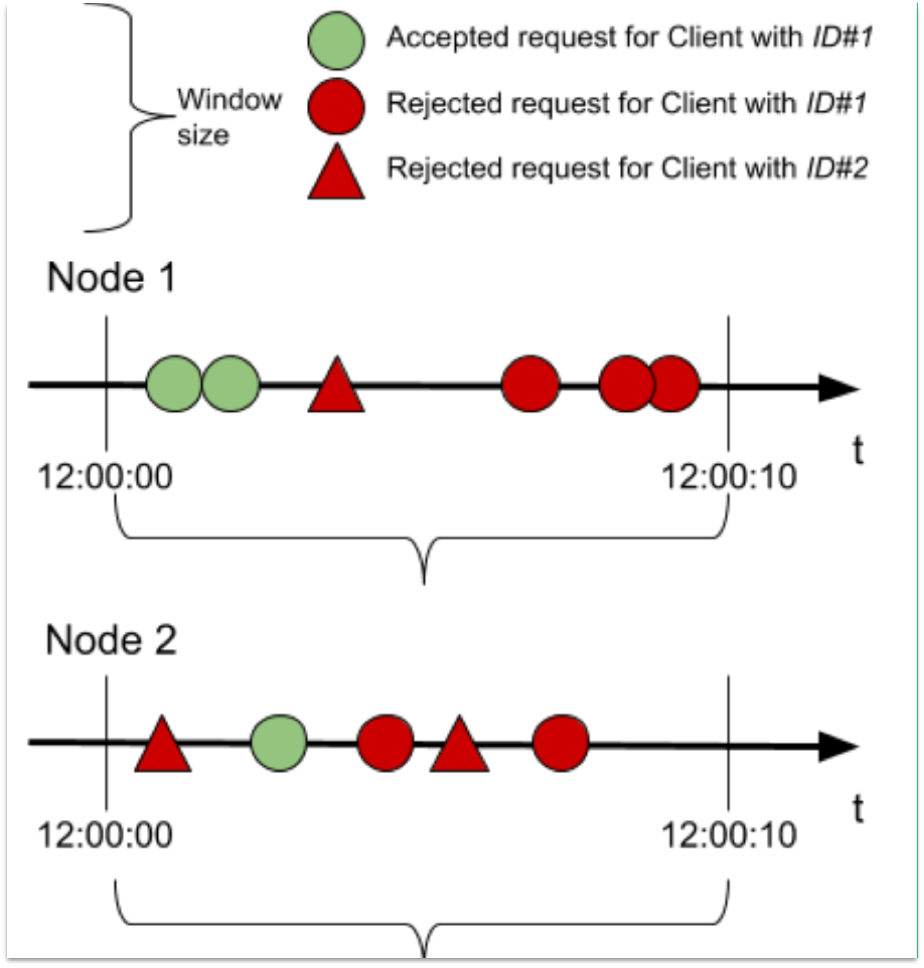
この例では、次のようになります。
-
クライアント ID#1 の要求:
ポリシーがクラスタリングされているため、クラスター全体で 3 件の要求を受け入れます。ポリシーのクラスタリングが無効化されると、Mule クラスターはウィンドウごとに 6 件の要求 (ノードごとに 3 件の要求) を受け入れることができます。
-
クライアント ID#2 の要求:
このクライアントは特定の API との間で定義されているコントラクトを持たないため、すべての要求が拒否されます。
分散されたカウンターによってノードの同期が必要となり、その結果としてパフォーマンスが低下します。このポリシーでは、キャッシュメカニズムを使用して動作を予測し、スループットを最大化します。ただし、最悪ケースのシナリオではレイテンシーが大きくなることがあります。クラスタリング設定を使用するかどうかは、ユースケースによって決まります。
ポリシーの設定
レート制限 SLA ポリシーを設定する場合は、ポリシーの価値を最大限に引き出せるように、環境の特定の側面を考慮する必要があります。
クラスター設定とスタンドアロン設定の選択
サーバーで認証メカニズムとして 1 つのクライアントアプリケーションしか使用していない場合は、レート制限ポリシーと同じ推奨事項が適用されます。複数の Mule インスタンスを使用している場合は、異なるクライアントアプリケーションをロードバランサーの異なるサーバーにマッピングすることがあります。
このようなシナリオでは、クラスターを使用する必要はありません。スタンドアロンノードの場合は、それぞれのノードが排他的に実行しているクライアントに対してレート制限アルゴリズムを作成します。一方、サーバーの高可用性を実現するために複数のクライアントアプリケーションを設定する場合があります。
Mule クラスターでは、クラスター全体の各クライアントについて SLA クォータを数えるため、このユースケースではクラスターが最適です。レート制限 SLA ポリシーは、ワークロードが分散されていても分散されていなくても機能するように設計されています。バックエンドは過剰な要求を受け取らないため、最大容量を超えることはありません。
クラスターノードのウィンドウサイズの選択
クラスター設定では、一貫性を保つためにノードがクラスター全体で情報を共有する必要があります。共有プロセスによりレイテンシーが発生するため、パフォーマンスについて確認するときには考慮する必要があります。
最悪のシナリオでは、クラスターの一貫性のためにレイテンシーの影響を受ける要求の数は一定で、設定された割り当ての実際のサイズとは関係がありません。そのため、期間が短いほど、遅延する可能性がある要求の割合は大きくなります。
したがって、レート制限ポリシーとレート制限 SLA ポリシーの設定では、クラスターシナリオでのみ 1 分より長いウィンドウサイズを設定する必要があります。
レート制限 SLA ポリシーの永続性の選択 (Mule のみ)
レート制限 SLA ポリシーは、数日、数ヶ月、あるいは数年に渡って永続するウィンドウを使用するように設定できます。たとえば、1 年間に 100 万件の要求をコンシュームできるようにしたいものの、その期間全体に渡ってノードが稼動しているかどうか、あるいは Mule の再起動が発生するメンテナンスが必要になるかどうかについては確信が持てないとします。
アルゴリズムはすでに数か月間実行されているため、クライアントは重要な情報を失います。永続性では、現在のポリシー状態を定期的に保存することによってこの問題を解決します。再デプロイメントや再起動が発生した場合、アルゴリズムは最後の既知の永続的な状態から再作成されるか、クリーンな状態から開始されます。
永続性はデフォルトで有効になっていますが、次のプロパティを false に設定することで無効にできます。
throttling.persistence_enabled
また、永続性の頻度を調整できます。デフォルトは 10 秒です。
throttling.persistent_data_update_freq
|
永続性は CloudHub では使用できません。 |
FAQ
このウィンドウはいつ開始されますか?
このウィンドウは、ポリシーが正常に適用された後の最初の要求で開始されます。
アルゴリズムが使用するウィンドウの種別は?
固定ウィンドウです。
クォータを使い果たすとどうなりますか?
アルゴリズムは、最初の要求を受信したときにオンデマンドで作成されます。このイベントによって、期間が固定されます。各要求は、期間が終了するまで、現在のウィンドウの要求クォータをコンシュームします。
要求クォータを使い果たすと、レート制限 SLA ポリシーは要求を拒否します。ウィンドウが終了すると、要求クォータはリセットされ、同じ固定サイズの新しいウィンドウが開始されます。
SLA で複数の制限を定義するとどうなりますか?
ポリシーはウィンドウあたりの要求クォータ設定を使用して各制限のアルゴリズムを作成します。そのため、複数の制限が設定されている場合、要求が受け入れられるには、すべてのアルゴリズムに現在のウィンドウで使用可能な要求クォータが存在する必要があります。
各レスポンスヘッダーの意味は?
各レスポンスヘッダーは、要求の現在の状態に関する情報を返します。
-
X-Ratelimit-Remaining: 使用可能な要求クォータ
-
X-Ratelimit-Limit: 各ウィンドウで使用可能な最大要求数
-
X-Ratelimit-Reset: 新しいウィンドウが開始されるまでの残り時間 (ミリ秒)
デフォルトでは、応答の X-RateLimit ヘッダーは無効になっています。これらのヘッダーを有効にするには、ポリシーの設定時に [Expose Headers (ヘッダーを公開)] を選択します。
Mule クラスターを CloudHub で設定できますか?
いいえ。この機能は、Runtime Fabric、ハイブリッド、およびスタンドアロン Mule 設定でのみ使用できます。
レート制限 SLA やスパイク制御ではなくレート制限ポリシーを使用する必要がある状況は?
レート制限 SLA ポリシーとレート制限 SLA ポリシーは、説明責任を果たすためにハード制限を (レート制限で識別子を使用して) グループまたは (レート制限 SLA を使用して) クライアントアプリケーションに適用する場合に使用します。バックエンドを保護するには、代わりにスパイク制御を使用してください。