レート制限および調整
ここでは、Mule 3.x 以前にデプロイされた API に関する調整とレート制限ポリシーのトピックに対応する、調整とレート制限の基盤となるテクノロジーについて詳しく説明します。説明の多くは、Mule Runtime 4.x にデプロイされた API にも該当します。
用語
レート制限と調整では、次の用語が使用されます。
-
制限: 一連のペア - 割り当てと期間
-
割り当て: API Manager で設定する
# of Reqs -
期間: API Manager ペア - 期間と時間単位
-
再試行: 要求をキューに登録する調整機能
-
コントラクト: アプリケーションと SLA の間の関係
制限
API Manager で制限を選択すると、制限および調整アルゴリズムの期間あたりの割り当て設定が定義されます。アルゴリズムは、最初の要求を受信したときにオンデマンドで作成されます。このイベントによって、期間が固定されます。
各要求は、期間が終了するまで、現在の期間の割り当てをコンシュームします。 割り当てが枯渇した場合のアクションは、ポリシーによって異なります。
-
レート制限では、要求は拒否されます。
-
調整では、要求は再試行のためにキューに登録されます。
期間が終了すると、割り当てはリセットされ、同じ固定サイズの新しい期間が開始されます。 ポリシーは各制限の期間あたりの割り当て設定を使用してアルゴリズムを作成します。そのため、複数の制限が設定されている場合、要求が受け入れられるには、すべてのアルゴリズムに現在の期間で使用可能な割り当てが存在する必要があります。
レスポンスヘッダー
次のアクセス制限ポリシーは、要求の現在の状態に関する情報を含むヘッダーを返します。
-
X-Ratelimit-Remaining: 使用可能な割り当て量。
-
X-Ratelimit-Limit: 期間あたりに使用可能な最大要求数。
-
X-Ratelimit-Reset: 新しい期間が開始されるまでの残り時間 (ミリ秒)。
調整再試行
調整は、急増を緩和することを目的としているため、Mule Runtime は要求を遅延させて、後で再試行できます。次の例は、要求の拒否と受け入れがどのように行われるかを示しています。
拒否される要求
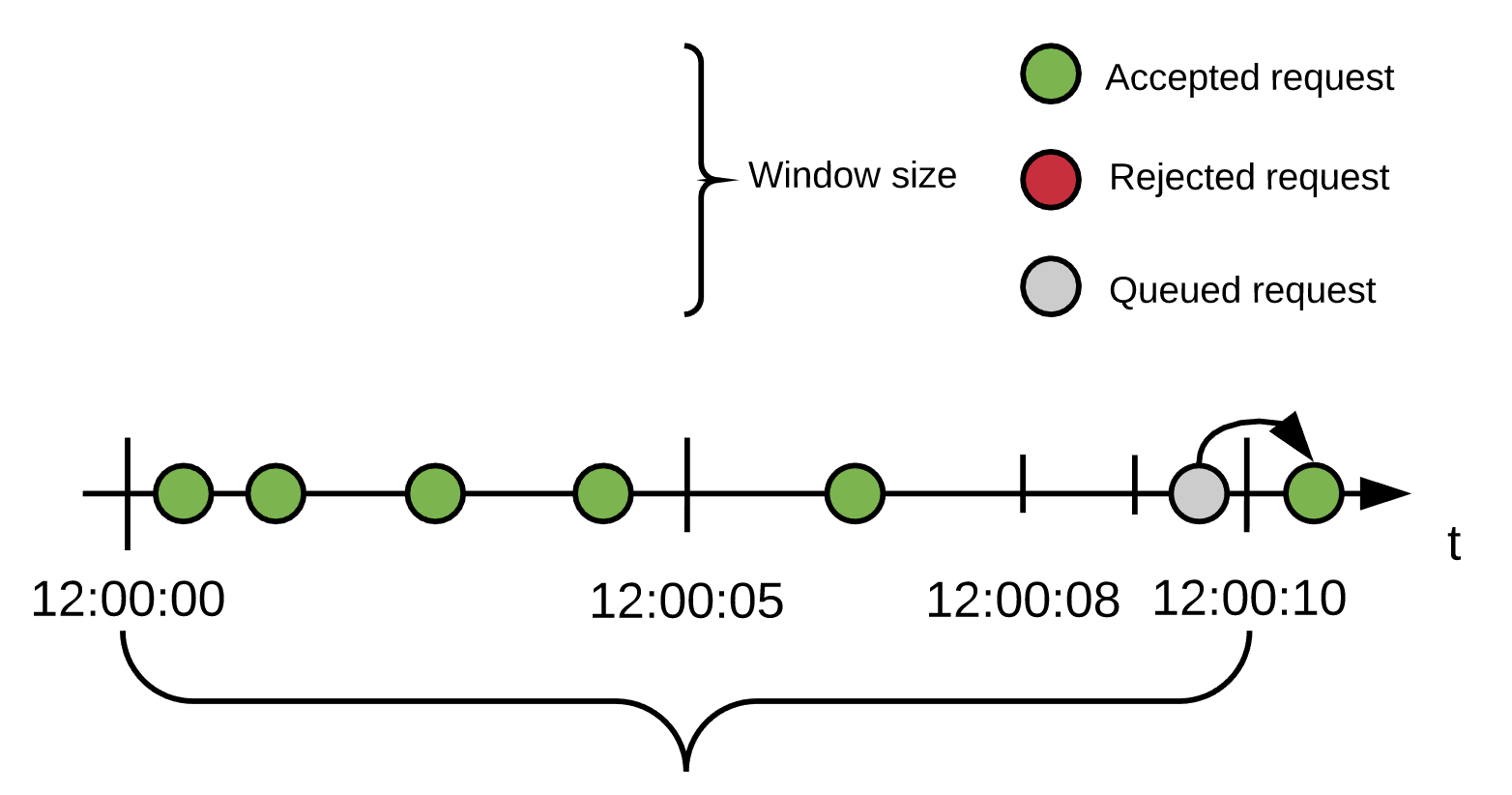
ポリシー設定: 5 件の要求/10 秒の期間、500ms の遅延で 1 回の再試行
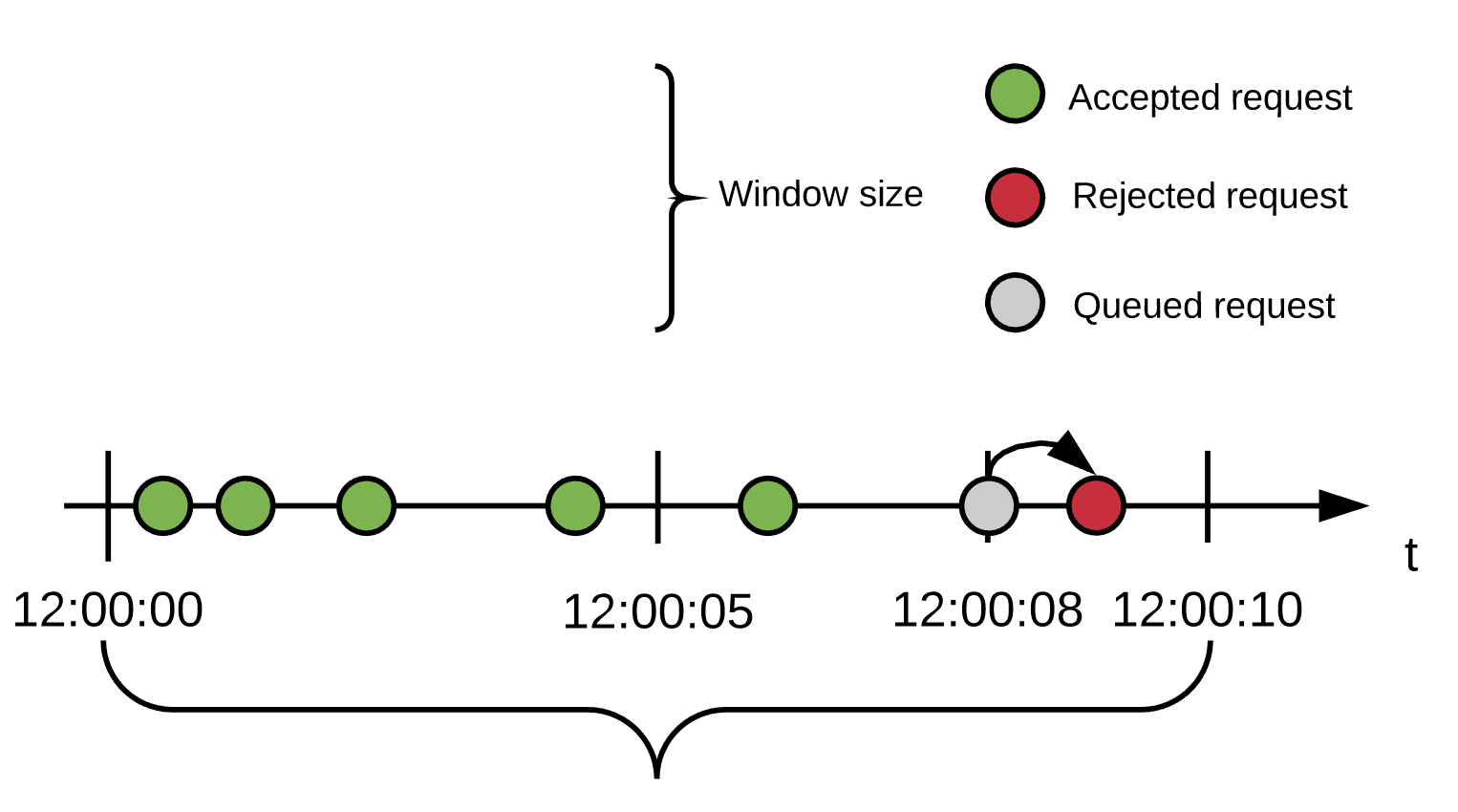
ユーザーは最初の 6 秒間で 5 件の要求を送信し、そのすべてが受け入れられます。8 秒の時点で新しい要求を受信しますが、割り当てが残っていないため、この要求は 500ms 遅延されます。
8.5 秒の時点でキューに登録された要求が再処理されます。期間がまだ終了していないため、割り当ては使用できないままです。再試行回数も残っていないため、この要求は拒否されます。
クラスターとスタンドアロン
弾力性を実現する 1 つの方法は冗長性を使用することです。つまり、同じ API に複数の Mule Runtime インスタンスを使用します。
この状況で考慮すべきことは、レート制限 (SLA ありまたはなし) を共有するかどうかということです。複数の Mule Runtime をクラスターで実行するように設定して、設定した制限を共有し、すべてのノードを全体として扱うことができます。
次に、さまざまなシナリオに対応した分析を示します。
分散処理
n 個のノードがあり、次のようになっています。
-
各ノードにはそれぞれのバックエンドがある。
-
最速の応答が必要である。
-
処理される要求数は、バックエンドの容量によってのみ制限される。
-
SLA レベルがないか、各ノードに 1 つだけある。
たとえば、2 つのノードが必要で、1 つは会社の有料ユーザーに割り当て、もう 1 つはその他に割り当てる場合などです。
このシナリオの分散処理では、クラスターの必要はありません。単に最も弱いノードのバックエンド容量を下回るポリシーを設定します。SLA のないシナリオでは、ノードがダウンした場合にロードバランサーが役立つことがあります。
中央処理
n 個のノードがあり、次のようになっています。
-
バックエンドが一元化されている。
-
処理される要求数は、バックエンドの容量によってのみ制限される。
-
SLA レベルがないか、すべてのノードの SLA は 1 つで、同じである。
たとえば、すべてのノードが会社の有料ユーザーに割り当てられている場合などです。
前方にロードバランサーがあれば、クラスターの必要はありません。バックエンドの最大容量を q とすると、ポリシーを次のように設定します。
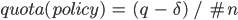
ここで、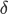 は、バックエンドの最大容量を下回る小さな数値です。
は、バックエンドの最大容量を下回る小さな数値です。
ロードバランサーがない場合、各ノードが処理するトラフィックを事前に設定できないため、スタンドアロンよりもクラスターノードをお勧めします。これらのポリシーは、ワークロードのバランスが完全に取れている場合でも、非常に不均衡な場合でも機能するように設計されています。バックエンドは余分な要求を受信しません。
複数のワーカー
n 個の CloudHub ワーカーがあり、次のようになっています。
-
各ワーカーは同じ API を表している。
-
アプリケーションのワークロードはワーカー間に等しく分散されている。
アプローチは、中央処理のユースケースと同じです。
複数のコントラクトの使用
n 個のノードがあり、次のようになっています。
SLA が適用されている。
レート制限 SLA が適用されていて、各ノードが複数の SLA からの要求を受け入れる必要がある場合は、各ノードが各 SLA からの何件の要求を処理するかを事前に決定できないため、クラスターが適しています。
クラスター内の期間の長さ
クラスターでは、クラスター内での一貫性を保つためにノードは情報を共有する必要があります。共有プロセスによりレイテンシーが発生するため、パフォーマンスについて確認するときには考慮する必要があります。
最悪の場合、クラスターの一貫性のためにレイテンシーの影響を受ける要求の数は一定で、設定された割り当ての実際のサイズとは関係がありません。そのため、期間が短いほど、遅延する可能性がある要求の割合は大きくなります。したがって、レート制限ポリシーとレート制限 SLA ポリシーの設定では、1 分より長い期間のみを設定することを強くお勧めします。
永続性
レート制限および調整アルゴリズムで日、月、年といった長い期間を使用するように設定できます。たとえば、クライアントとしてユーザー X が 1 年に 100 万件の要求をコンシュームすることを許可したいとします。ノードが期間中ずっと稼働しているか、それともメンテナンスが必要になるかを予測することはできません。メンテナンスを行うとランタイムを再起動する可能性があります。アルゴリズムはすでに数か月間実行されているため、クライアントは重要な情報を失います。永続性では、現在のポリシー状態を定期的に保存することによってこの問題を解決します。再デプロイメントや再起動が発生した場合、アルゴリズムは最後の既知の永続的な状態から再作成されるか、クリーンな状態から開始されます。
永続性はデフォルトで有効になっていますが、次のプロパティを false に設定することで無効にできます。
throttling.persistence_enabled
また、永続性の頻度を調整できます。デフォルトは 10 秒です。
throttling.persistent_data_update_freq
IMPORTANT: この機能は CloudHub では無効になっています。