Batch Processing
| Batch processing is exclusive to Mule Enterprise runtimes. |
Mule allows you to process messages in batches.
Within an application, you can initiate a Batch Job scope, which splits messages into individual records, performs actions upon each record, and then reports on the results and potentially pushes the processed output to other systems or queues.
For example, you can use batch processing when:
-
Synchronizing data sets between business applications, such as syncing contacts between NetSuite and Salesforce.
-
Extracting, transforming and loading (ETL) information into a target system, such as uploading data from a flat file (CSV) to Hadoop.
-
Handling large quantities of incoming data from an API into a legacy system.
If you are already familiar with batch processing in Mule 3.x, you can get an overview of the differences with batch in Mule 4.x in the Migrating the Batch Module article.
Overview
Within a Mule application, batch processing provides a construct for asynchronously processing larger-than-memory data sets that are split into individual records. Batch jobs allow for the description of a reliable process that automatically splits up source data and stores it into persistent queues, which makes it possible to process large data sets while providing reliability. In the event that the application is redeployed or Mule crashes, the job execution is able to resume at the point it stopped.
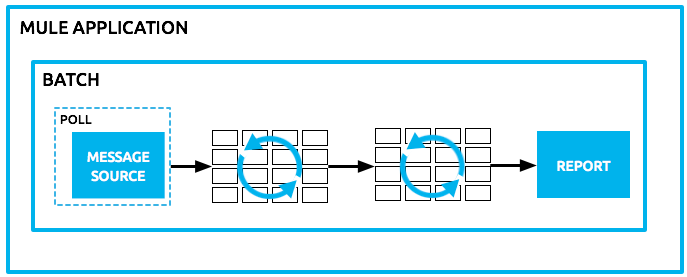
The job is then expressed in terms of processing individual records, providing semantics for record level variables, aggregation, and error handling.
Basic Architecture
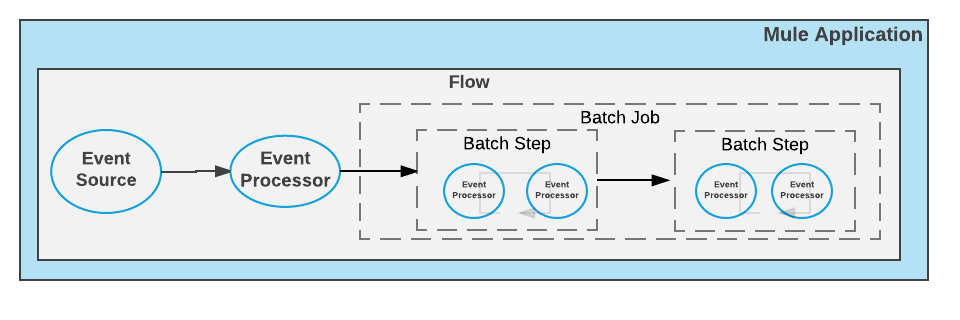
The heart of Mule’s batch processing lies within the batch job. A batch job is a scope that splits large messages into records that Mule processes asynchronously. In the same way flows process messages, batch jobs process records.
The Batch XML structure was modified on Mule 4.0. The example below shows abbreviated details to highlight batch elements.
<flow name="flowOne">
<batch:job jobName="batchJob">
<batch:process-records>
<batch:step name="batchStep1">
<event processor/>
<event processor/>
</batch:step>
<batch:step name="batchStep2">
<event processor/>
<event processor/>
</batch:step>
</batch:process-records>
</batch:job>
</flow>A batch job contains one or more batch steps that act upon records as they move through the batch job.
Each batch step in a batch job contains processors that act upon a record to transform, route, enrich, or otherwise process data contained within it. By leveraging the functionality of existing Mule processors, the batch step offers a lot of flexibility regarding how a batch job processes records. See Refining Batch Steps Processing for more information.
A batch job executes when the flow reaches the process-records section of the batch job. When triggered, Mule creates a new batch job instance. When the job instance becomes executable, the batch engine submits a task for each record block to the I/O pool to process each record. Parallelism occurs automatically, at the record block level. The Mule runtime engine uses its autotuning capabilities to determine how many threads to use and the level of parallelism to apply (see Execution Engine).
When the batch job starts executing, Mule splits the incoming message into records, stores them in a persistent queue, and queries and schedules those records in blocks of records to process. By default, the runtime stores 100 records in each batch step. You can customize this size according to the performance you require. See Refining Batch Steps Processing for more information.
After all the records have passed through all batch steps, the runtime ends the batch job instance and reports the batch job result indicating which records succeeded and which failed during processing.
Mule Message Splitting Process
The batch job performs an implicit split operation on the Mule message that recognizes any Java Iterables, Iterators, and Arrays, as well as JSON and XML payloads. The batch job cannot split any other data format. If you are working with a data format that is not compatible with the splitting process, transform the payload to a supported format before it enters the batch job.
Error Handling
Batch jobs can handle any record-level failure that might occur in processing to prevent the failure of a complete batch job. Further, you can set or remove variables on individual records so that during batch processing, Mule can route or otherwise act upon records in a batch job according to a variable (assigned above). See Handling Errors During Batch Job for more information.
Batch Job vs. Batch Job Instance
Though defined in context the above, it’s worth elaborating upon the terms batch job and batch job instance as they relate to each other.
-
A batch job is the scope element in an application in which Mule processes a message payload as a batch of records. The term batch job is inclusive of all three phases of processing: Load and Dispatch, Process, and On Complete.
-
A batch job instance is an occurrence in a Mule application whenever a Mule flow executes a batch job. Mule creates the batch job instance in the Load and Dispatch phase. Every batch job instance is identified internally using a unique String known as batch job instance id.
This identifier is useful if you want, for example, to pass the local job instance ID to an external system for referencing and managing data, improve the job’s custom logging, or even send an email or SMS notifications for meaningful events around that specific batch job instance. See Batch Job Instance ID to learn more about this identifier and how to customize it.
Batch Job Processing Phases
Each batch job contains three different phases:
-
Load and Dispatch.
-
Process.
-
On Complete.
Load and Dispatch
This first phase is implicit. During this phase, the runtime performs all the "behind the scenes" work to create a batch job instance. Essentially, this is the phase during which Mule turns a serialized message payload into a collection of records for processing as a batch. You don’t need to configure anything for this activity to occur, though it is useful to understand the tasks Mule completes during this phase.
-
Mule splits the message using Dataweave. This first step creates a new batch job instance.
Mule exposes the batch job instance ID through thebatchJobInstanceIdvariable. This variable is available in every step and the on-complete phase. -
Mule creates a persistent queue and associates it with the new batch job instance.
The queue name is prefixed with
BSQ, and you can see it in Anypoint Runtime Manager: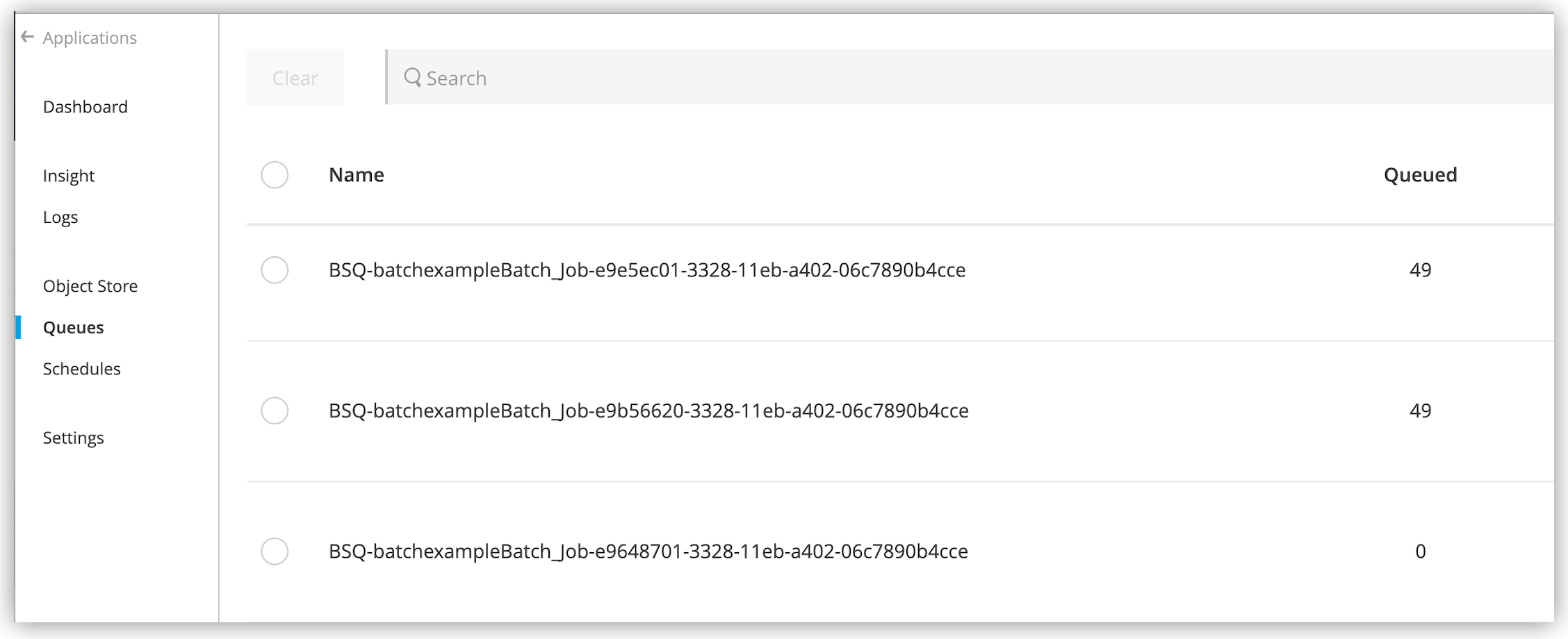
-
For each item generated by the splitter, Mule creates a record and stores it in the queue. This activity is "all or nothing" – Mule either successfully generates and queues a record for every item, or the whole message fails during this phase.
-
Mule presents the batch job instance, with all its queued-up records, to the first batch step for processing.
After this phase completes, the flow continues its execution without waiting for the batch job to finish processing all records. This behavior occurs because the next phase, Process, is asynchronous.
Process
During the Process phase, Mule starts pulling records from the stepping queue to build record blocks of the configured batch block size. Then, Mule sends the record blocks to their corresponding batch step and processes them asynchronously. Each batch step starts processing multiple record blocks in parallel, however, batch steps process the records inside each block sequentially. After a batch step processes all the records in a block, the batch step sends those records to the stepping queue, where the records await to be processed by the next batch step (each record keeps track of the steps it completed). This process continues until every record has passed through every batch step of the batch job instance.
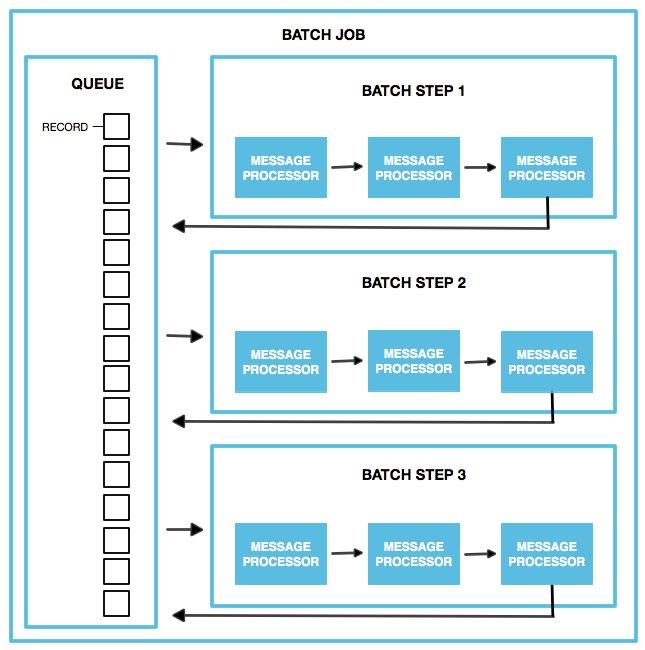
Note that a batch job instance does not wait for all its queued records to finish processing in one batch step before pushing any of them to the next batch step. However, if you configure an aggregator, the batch job step changes its behavior while processing records, depending on how the aggregator is configured:
-
Behavior with aggregator configured with fixed size
In this scenario, the batch step sends the processed records to an aggregator, which starts processing the records and buffering them until the configured aggregator’s size is reached. After that, the aggregator sends the aggregated records to the stepping queue.
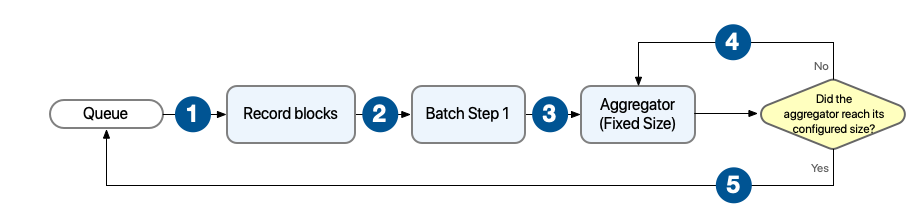
1 The batch job builds record blocks of the configured block size and sends them to their corresponding batch step for processing. 2 Each batch step receives one or more record blocks and starts processing them in parallel. 3 After the batch step processes a record, the batch step sends the record to the aggregator for further processing. 4 The aggregator continues processing records until the number of aggregated records reaches the configured aggregator’s size. 5 The aggregator sends all the aggregated records to the stepping queue. -
Behavior with aggregator configured for streaming
In this scenario, the batch step sends the processed records to an aggregator, which keeps processing records until all records from the current batch step are processed and aggregated.
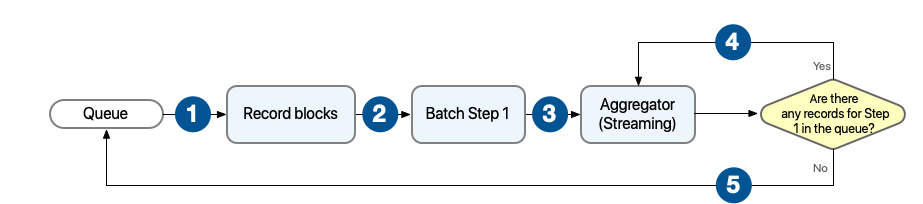
1 The batch job builds record blocks of the configured block size and sends them to their corresponding batch step for processing. 2 Each batch step receives one or more record blocks and starts processing them in parallel. 3 After the batch step processes a record, the batch step sends the record to the aggregator for further processing. 4 The aggregator continues processing records until there are no more records in the stepping queue that are waiting to be processed by the current batch step. 5 The aggregator sends all the aggregated records to the stepping queue.
Mule persists a list of all records that succeed or fail to process through each batch step. If an event processor in a batch step fails to process a record, Mule continues processing the batch, skipping over the failed record in each subsequent batch step.
At the end of this phase, the batch job instance completes and, therefore, ceases to exist.
Refine Batch Steps Processing
Beyond simple processing of records, there are several things you can do with records within a batch step.
-
You can apply filters by adding acceptExpressions within each batch step to prevent the step from processing certain records. For example, you can set a filter to prevent a step from processing any records which failed to process in the preceding step.
-
You can use a batch aggregator processor to aggregate records in groups, sending them as bulk upserts to external sources or services. For example, rather than upserting each contact (that is, a record) in a batch to Google Contacts, you can configure a batch aggregator to accumulate, say, 100 records, then upsert all of them to Google Contacts in one chunk.
See Refining Batch Steps Processing for more information.
On Complete
During this phase, you can optionally configure the runtime to create a report or summary of the records it processed for the particular batch job instance. This phase exists to give system administrators and developers some insight into which records failed to address any issues that might exist with the input data.
<batch:job name="Batch3">
<batch:process-records>
<batch:step name="Step1">
<batch:record-variable-transformer/>
<ee:transform/>
</batch:step>
<batch:step name="Step2">
<logger/>
<http:request/>
</batch:step>
</batch:process-records>
<batch:on-complete>
<logger/>
</batch:on-complete>
</batch:job>After Mule executes the entire batch job, the output becomes a batch job result object (BatchJobResult). Because Mule processes a batch job as an asynchronous, one-way flow, the results of batch processing do not feed back into the flow which may have triggered it, nor do the results return as a response to a caller. Any event source that feeds data into a batch job must be one-way, not request-response.
You have two options for working with the output:
-
Create a report in the On Complete phase, using DataWeave using information such as the number of failed records and successfully processed records, and in which step any errors might have occurred.
-
Reference the batch job result object elsewhere in the Mule application to capture and use batch metadata, such as the number of records which failed to process in a particular batch job instance.
If you leave the On Complete phase empty and do not reference the batch job result object elsewhere in your application, the batch job simply completes, whether failed or successful.
|
As a good practice, you should configure some mechanism for reporting on failed or successful records to facilitate further action where required. |
Variable Propagation
Every processed record of the Batch Job Instance starts with the same variables and values present before the execution of the block. Every record has its own set of variables, so new variables or modifications of already-existing variables during the processing of a given record will not be visible while processing another record. For each record, those variables (and modifications) are propagated through the different Batch Steps. For example, if record R1 sets a variable varName: "hello", record R2 sets varName: "world", and record R3 does not set this variable, then in the next step, R1 will see the value "hello", R2 the value "world" and R3 will not see any value for that variable.
In the On Complete phase, none of these variables (not even the original ones) are visible. Only the final result is available in this phase. Moreover, since the Batch Job Instance executes asynchronously from the rest of the flow, no variable set in either a Batch Step or the On Complete phase will be visible outside the Batch Scope.
Scheduling Strategy
A Mule application can contain several batch job definitions. Each definition has its own scheduling strategy. A Scheduling Strategy enables you to control how instances of a given batch job are executed:
-
ORDERED_SQUENTIAL(the default): If several job instances are in an executable state at the same time, the instances execute one at a time based on their creation timestamp. -
ROUND_ROBIN: This setting attempts to execute all available instances of a batch job using a round-robin algorithm to assign the available resources.The
ROUND_ROBINoption is useful when you can guarantee that no job execution can have a side effect on another job execution. Therefore, this option is not a good choice for data synchronization jobs, which can update the same record in two concurrent jobs. Because the order of the job execution is not guaranteed, your result might be a prior version of the data. However, you can safely use this strategy to parallelize the job’s execution if your batch job retrieves only new records from a database or lifts individual files from an SFTP server, and you are certain that all records are completely independent.
Note that none of these strategies guarantee that records will be executed in order. The strategies do not control the execution order of records in the batch job, nor do they depend on the number of records each instance contains.