Splitter Flow Control Examples
Splitting and Aggregating with Asynchronous Flows
This example builds upon the Splitter basic example. Follow the steps below to run message fragments in asynchronous flows and then aggregate them back into a single message.
Studio Visual Editor
-
Drag a VM connector to the end of the flow.
-
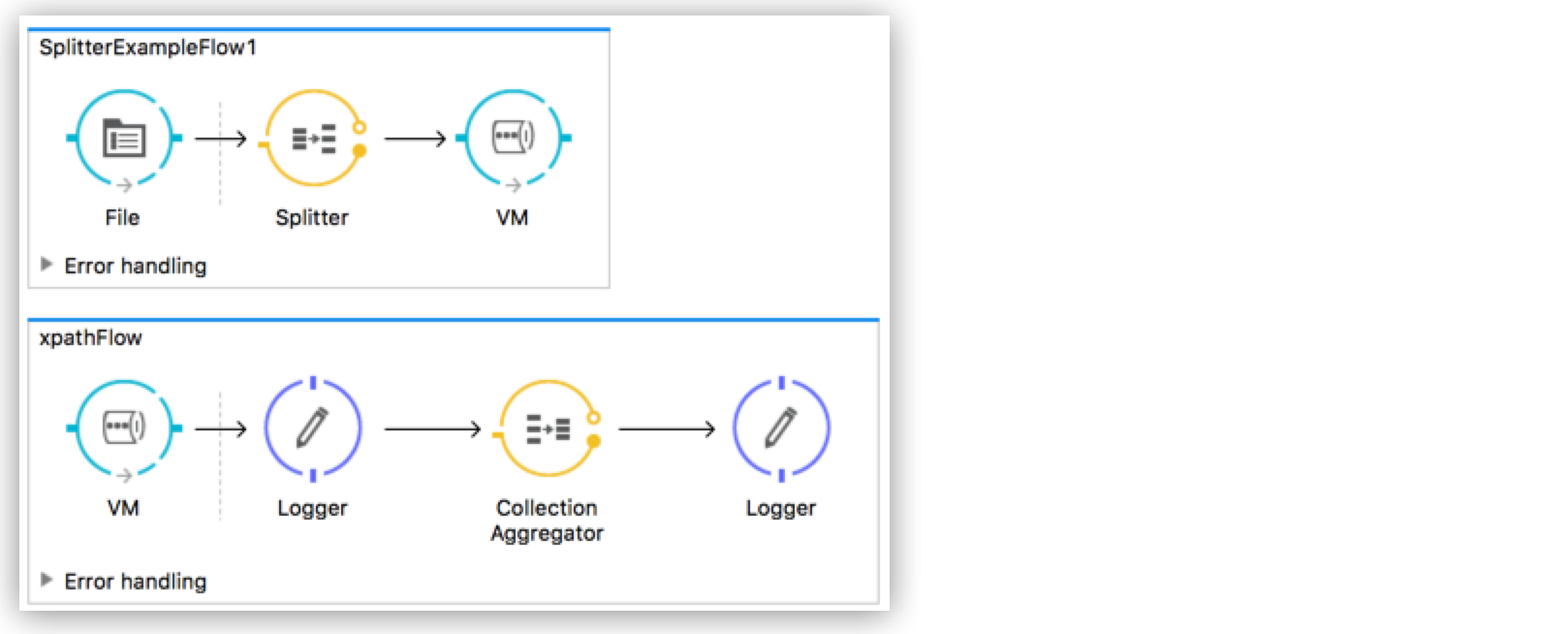
Drag a second VM connector outside the existing flow, below it. This creates a new flow.
-
Drag the existing aggregator and logger you had in the first flow to the new second flow, after the VM connector.
-
Configure the two VM connectors. Change both their Queue Path to
step2.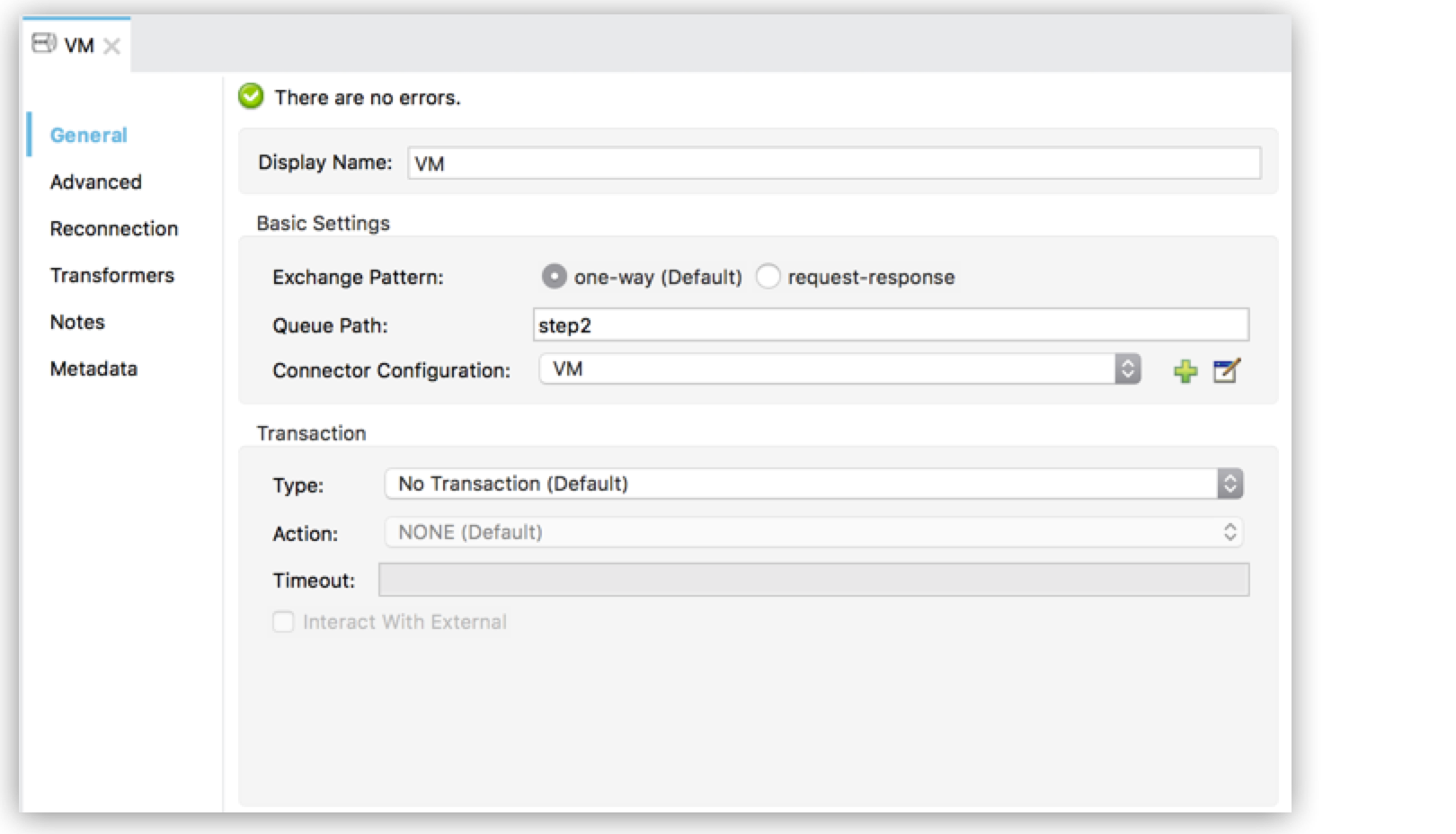
After you configure both VMs with the same Queue Path, they are linked. Messages that arrive to the first VM continue their path out of the second VM.
What you have at this point appears to work identically to what you built in the first example. There is, however, one key difference: each fraction of the message is processed simultaneously rather than in sequence. If you deploy your app to a cluster of servers, this has a big effect on performance.
You should see four messages logged into the console: the first three should be short, one for every "actor" XML element (notice the ID attribute in each message). After these first three messages there should be a fourth, longer message, which is logged after the aggregator has run. Notice two things:
-
Although the aggregator was triggered three times, once for every fraction of the message that reached it, it produced one single output message, only when all of the fractions were in place
-
The aggregator assembles the message in the order in which fractions have arrived; the final message may be shuffled. If maintaining the original sequence is important to you, take a look at the Advanced Example 2 in this page.
XML Editor
-
Add a second flow to your project.
<flow name="SplitterExampleFlow1" > <file:inbound-endpoint path="./src/main/resources/" connector-ref="File" pollingFrequency="5000" responseTimeout="10000" doc:name="File"> <file:filename-regex-filter pattern="vip.xml" caseSensitive="true"/> </file:inbound-endpoint> <splitter expression="#[xpath3('//*:actor/text()',payload,'NODESET')]" doc:name="Splitter"/> <logger message="#[payload]" level="INFO" doc:name="Logger"/> <collection-aggregator failOnTimeout="true" doc:name="Collection Aggregator"/> <logger message="#[payload]" level="INFO" doc:name="Logger"/> </flow> <flow name="xpathFlow"> </flow>xml -
Move both loggers and the Collection Aggregator to the second flow and connect them and link both flows through a couple of VM connectors, an outbound connector in the first flow and an inbound connector in the second flow.
<flow name="SplitterExampleFlow1" > <file:inbound-endpoint path="./src/main/resources/" connector-ref="File" pollingFrequency="5000" responseTimeout="10000" doc:name="File"> <file:filename-regex-filter pattern="vip.xml" caseSensitive="true"/> </file:inbound-endpoint> <splitter expression="#[xpath3('//*:actor/text()',payload,'NODESET')]" doc:name="Splitter"/> <vm:outbound-endpoint exchange-pattern="one-way" path="step2" connector-ref="VM" doc:name="VM"/> </flow> <flow name="xpathFlow"> <vm:inbound-endpoint exchange-pattern="one-way" path="step2" connector-ref="VM" doc:name="VM"/> <logger message="#[payload]" level="INFO" doc:name="Logger"/> <collection-aggregator failOnTimeout="true" doc:name="Collection Aggregator"/> <logger message="#[payload]" level="INFO" doc:name="Logger"/> </flow>xmlProvide these same attributes for both VM connectors:
Attribute Value exchange-pattern
one-way
After both VMs share the same Queue Path, they are linked. Messages that arrive to the first VM continue their path out of the second VM. What you have at this point appears to work identically to what you built in the first example. There is, however, one key difference: each fraction of the message processes simultaneously rather than in sequence. If you deploy your app to a cluster of servers this has a big effect on performance.
You should see four messages logged into the console: the first three should be short, one for every "actor" XML element (notice the ID attribute in each message). After these first three messages there should be a fourth, longer message, which is logged after the aggregator has run. Notice two things:
-
Although the aggregator was triggered three times, once for every fraction of the message that reached it, it produced one single output message, only when all of the fractions were in place.
-
The aggregator assembles the message in the order in which fractions have arrived; the final message may be shuffled. If maintaining the original sequence is important to you, take a look at the Advanced Example 2 in this page.
-
Full Example Code
<?xml version="1.0" encoding="UTF-8"?>
<mule xmlns:file="http://www.mulesoft.org/schema/mule/file" xmlns:dw="http://www.mulesoft.org/schema/mule/ee/dw" xmlns:tracking="http://www.mulesoft.org/schema/mule/ee/tracking" xmlns:vm="http://www.mulesoft.org/schema/mule/vm"
xmlns:mulexml="http://www.mulesoft.org/schema/mule/xml" xmlns:http="http://www.mulesoft.org/schema/mule/http" xmlns="http://www.mulesoft.org/schema/mule/core" xmlns:doc="http://www.mulesoft.org/schema/mule/documentation" xmlns:spring="http://www.springframework.org/schema/beans" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://www.mulesoft.org/schema/mule/vm http://www.mulesoft.org/schema/mule/vm/current/mule-vm.xsd
http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans-current.xsd
http://www.mulesoft.org/schema/mule/core http://www.mulesoft.org/schema/mule/core/current/mule.xsd
http://www.mulesoft.org/schema/mule/http http://www.mulesoft.org/schema/mule/http/current/mule-http.xsd
http://www.mulesoft.org/schema/mule/xml http://www.mulesoft.org/schema/mule/xml/current/mule-xml.xsd
http://www.mulesoft.org/schema/mule/ee/tracking http://www.mulesoft.org/schema/mule/ee/tracking/current/mule-tracking-ee.xsd
http://www.mulesoft.org/schema/mule/file http://www.mulesoft.org/schema/mule/file/current/mule-file.xsd
http://www.mulesoft.org/schema/mule/ee/dw http://www.mulesoft.org/schema/mule/ee/dw/current/dw.xsd">
<file:connector name="File" autoDelete="false" streaming="true" validateConnections="true" doc:name="File"/>
<vm:connector name="VM" validateConnections="true" doc:name="VM"/>
<flow name="SplitterExampleFlow1" >
<file:inbound-endpoint path="./src/main/resources/" connector-ref="File" pollingFrequency="5000" responseTimeout="10000" doc:name="File">
<file:filename-regex-filter pattern="vip.xml" caseSensitive="true"/>
</file:inbound-endpoint>
<splitter expression="#[xpath3('//*:actor/text()',payload,'NODESET')]" doc:name="Splitter"/>
<vm:outbound-endpoint exchange-pattern="one-way" path="step2" connector-ref="VM" doc:name="VM"/>
</flow>
<flow name="xpathFlow">
<vm:inbound-endpoint exchange-pattern="one-way" path="step2" connector-ref="VM" doc:name="VM"/>
<logger message="#[payload]" level="INFO" doc:name="Logger"/>
<collection-aggregator failOnTimeout="true" doc:name="Collection Aggregator"/>
<logger message="#[payload]" level="INFO" doc:name="Logger"/>
</flow>
</mule>xmlReordering Before Aggregating
This example builds upon the previous example.
If fractions of the message are being processed in parallel in different servers, there’s a good chance that they may take different lengths of time to be processed, and consequently fall out of order. The following example solves that problem.
Follow the steps below to:
-
Run message fragments in asynchronous flows.
-
Arrange them back into the original sequence.
-
Aggregate them back into a single message that follows the original sequence.
Studio Visual Editor
-
Add a Resequencer Flow Control before the aggregator
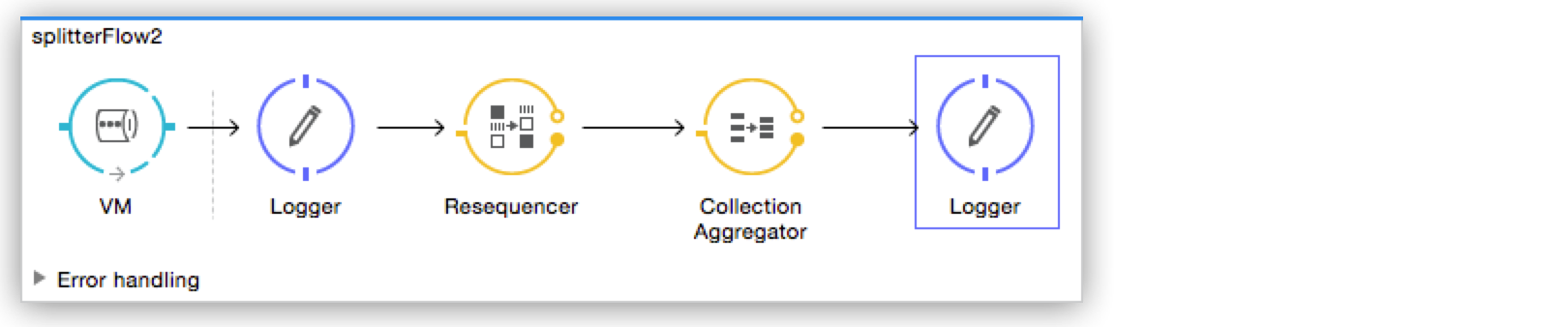
The Resequencer waits for all of the messages in the group to arrive (keeping track of MULE_CORRELATION_ID and MULE_CORRELATION_GROUP_SIZE) and then reorder them according to their MULE_CORRELATION_SEQUENCE index.
The Resequencer outputs three distinct messages, so the Aggregator is still needed to merge them into one.
-
Run the Mule project.
With the Resequencer in place, messages now reach the aggregator in the correct order and are assembled accordingly.
To really take advantage of splitting the message, you should deploy your app to a cluster of servers. By following the steps below, you can simulate the random delays of a cluster of servers.
|
The following is not an implementable solution but rather a proof of concept that highlights what occurs in the flow. |
-
Add a Groovy component in the second flow, between the VM and the logger.

-
Copy the following code into the Groovy Component:
random = new Random() randomInt = random.nextInt(10)*1000 Thread.sleep(randomInt) return payloadtextThis snippet of code simply introduces a random delay of up to 10 seconds. As each message is running asynchronously, this delay can potentially alter the order in which messages move on to the next step, simulating what could happen in a real implementation with parallel servers processing each fraction of the message.
XML Editor
-
Add a Resequencer Flow Control before the aggregator.
<resequencer failOnTimeout="true" doc:name="Resequencer"/>
Attribute Value failOnTimeouttruedoc:nameResequencerThe Resequencer waits for all of the messages in the group to arrive (keeping track of MULE_CORRELATION_ID and MULE_CORRELATION_GROUP_SIZE) and then reorders them according to their MULE_CORRELATION_SEQUENCE index.
The Resequencer outputs three distinct messages, so the Aggregator is still needed to merge them into one.
With the Resequencer in place, messages now reach the aggregator in the correct order and are assembled accordingly.
To really take advantage of splitting the message, you should deploy your app to a cluster of servers. By following the steps below, you can simulate the random delays of a cluster of servers.
| The following is not an implementable solution but rather a proof of concept that highlights what occurs in the flow. |
-
Add a Groovy component in the second flow, between the VM and the first logger.
<scripting:component doc:name="Groovy"> <scripting:script engine="Groovy"> <![CDATA[ random = new Random() randomInt = random.nextInt(10)*1000 Thread.sleep(randomInt) return payload ]]> </scripting:script> </scripting:component>xmlThis snippet of code simply introduces a random delay of up to 10 seconds. As each message is running asynchronously, this delay can potentially alter the order in which messages move on to the next step, simulating what could happen in a real implementation with parallel servers processing each fraction of the message.
-
Run the project.
You should now see three messages logged into the console, one for every "actor" XML element. These likely not have their MULE_CORRELATION_SEQUENCE indexes in order due to the random delays caused by the Groovy code.
Below these, you see a fourth longer message where these indexes are put back in order by the Resequencer.
INFO YYYY-DD-MM HH:MM:SS,SSS [] org.mule.api.processor.LoggerMessageProcessor: [#text: Will Ferrell] INFO YYYY-DD-MM HH:MM:SS,SSS [] org.mule.api.processor.LoggerMessageProcessor: [#text: Christian Bale] INFO YYYY-DD-MM HH:MM:SS,SSS [] org.mule.api.processor.LoggerMessageProcessor: [#text: Liam Neeson] INFO YYYY-DD-MM HH:MM:SS,SSS [] org.mule.api.processor.LoggerMessageProcessor: [[#text: Christian Bale], [#text: Liam Neeson], [#text: Will Ferrell]]text
Full Example Code
<?xml version="1.0" encoding="UTF-8"?>
<mule xmlns:scripting="http://www.mulesoft.org/schema/mule/scripting" xmlns:file="http://www.mulesoft.org/schema/mule/file" xmlns:dw="http://www.mulesoft.org/schema/mule/ee/dw" xmlns:tracking="http://www.mulesoft.org/schema/mule/ee/tracking" xmlns:vm="http://www.mulesoft.org/schema/mule/vm" xmlns:mulexml="http://www.mulesoft.org/schema/mule/xml" xmlns:http="http://www.mulesoft.org/schema/mule/http" xmlns="http://www.mulesoft.org/schema/mule/core" xmlns:doc="http://www.mulesoft.org/schema/mule/documentation" xmlns:spring="http://www.springframework.org/schema/beans" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://www.mulesoft.org/schema/mule/vm http://www.mulesoft.org/schema/mule/vm/current/mule-vm.xsd
http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans-current.xsd
http://www.mulesoft.org/schema/mule/core http://www.mulesoft.org/schema/mule/core/current/mule.xsd
http://www.mulesoft.org/schema/mule/http http://www.mulesoft.org/schema/mule/http/current/mule-http.xsd
http://www.mulesoft.org/schema/mule/xml http://www.mulesoft.org/schema/mule/xml/current/mule-xml.xsd
http://www.mulesoft.org/schema/mule/ee/tracking http://www.mulesoft.org/schema/mule/ee/tracking/current/mule-tracking-ee.xsd
http://www.mulesoft.org/schema/mule/file http://www.mulesoft.org/schema/mule/file/current/mule-file.xsd
http://www.mulesoft.org/schema/mule/ee/dw http://www.mulesoft.org/schema/mule/ee/dw/current/dw.xsd
http://www.mulesoft.org/schema/mule/scripting http://www.mulesoft.org/schema/mule/scripting/current/mule-scripting.xsd">
<file:connector name="File" autoDelete="false" streaming="true" validateConnections="true" doc:name="File"/>
<vm:connector name="VM" validateConnections="true" doc:name="VM"/>
<flow name="SplitterExampleFlow1" >
<file:inbound-endpoint path="./src/main/resources/" connector-ref="File" pollingFrequency="15000" responseTimeout="10000" doc:name="File">
<file:filename-regex-filter pattern="vip.xml" caseSensitive="true"/>
</file:inbound-endpoint>
<splitter expression="#[xpath3('//*:actor/text()',payload,'NODESET')]" doc:name="Splitter"/>
<vm:outbound-endpoint exchange-pattern="one-way" path="step2" connector-ref="VM" doc:name="VM"/>
</flow>
<flow name="xpathFlow">
<vm:inbound-endpoint exchange-pattern="one-way" path="step2" connector-ref="VM" doc:name="VM"/>
<scripting:component doc:name="Groovy">
<scripting:script engine="Groovy">
<![CDATA[random = new Random()
randomInt = random.nextInt(10)*1000
Thread.sleep(randomInt)
return payload]]>
</scripting:script>
</scripting:component>
<logger message="#[payload]" level="INFO" doc:name="Logger"/>
<resequencer failOnTimeout="true" doc:name="Resequencer"/>
<collection-aggregator failOnTimeout="true" doc:name="Collection Aggregator"/>
<logger message="#[payload]" level="INFO" doc:name="Logger"/>
</flow>
</mule>xmlNested Splitters
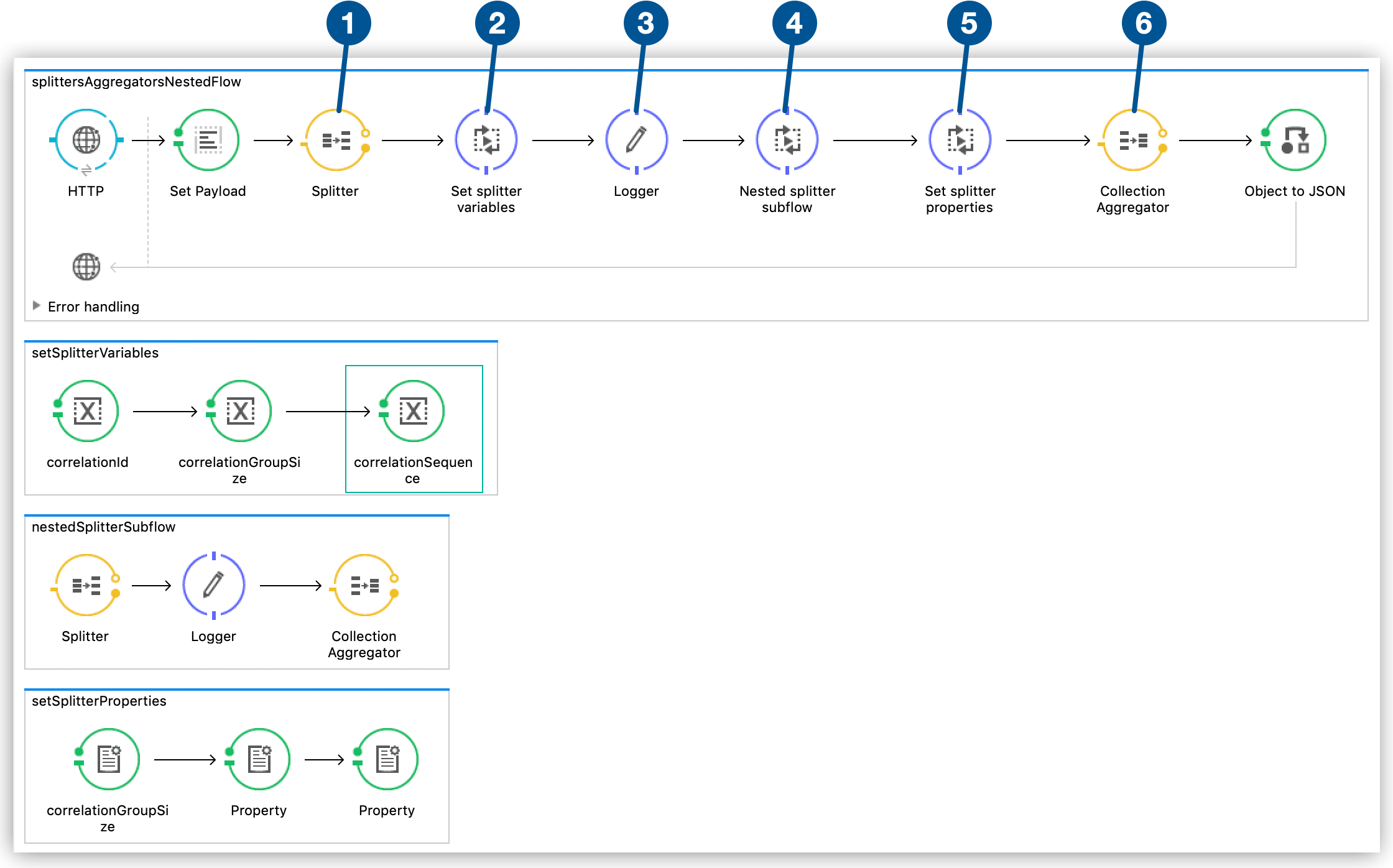
The following example project sets the payload to [[1,2,3,4], [5,6,7,8], [9,10,11,12]] and then uses nested splitters to process each element in that payload. The example also shows how to store message properties when using nested splitters so the original message can be assembled:
-
The splitter splits the payload into fragments.
-
This Flow Reference calls the
setSplitterVariablessubflow, which stores the values of thecorrelationId,correlationGroupSize, andcorrelationGroupSizeproperties into different variables. -
The logic for the first splitter is implemented: in this case, it outputs the content of the payload using a Logger component.
-
This Flow Reference calls
nestedSplitterSubflow, which executes a new splitter, a Logger component that outputs the content of the payload, and a collection aggregator that assembles the messages split in this subflow. -
This Flow Reference calls the
setSplitterPropertiessub-flow, which sets thecorrelationId,correlationGroupSize, andcorrelationGroupSizeproperties using the values from the variables created insetSplitterVariables. -
The collection aggregator assembles the original message using the message properties set in the
setSplitterPropertiessubflow.
When this project runs, the console shows the following output (logs shortened for readability):
SPLITTER 1: PROCESSING ITEM [1, 2, 3, 4] SPLITTER 2: PROCESSING ITEM 1 SPLITTER 2: PROCESSING ITEM 2 SPLITTER 2: PROCESSING ITEM 3 SPLITTER 2: PROCESSING ITEM 4 SPLITTER 1: PROCESSING ITEM [5, 6, 7, 8] SPLITTER 2: PROCESSING ITEM 5 SPLITTER 2: PROCESSING ITEM 6 SPLITTER 2: PROCESSING ITEM 7 SPLITTER 2: PROCESSING ITEM 8 SPLITTER 1: PROCESSING ITEM [9, 10, 11, 12] SPLITTER 2: PROCESSING ITEM 9 SPLITTER 2: PROCESSING ITEM 10 SPLITTER 2: PROCESSING ITEM 11 SPLITTER 2: PROCESSING ITEM 12
Full Example Code
<?xml version="1.0" encoding="UTF-8"?>
<mule xmlns:file="http://www.mulesoft.org/schema/mule/file" xmlns:dw="http://www.mulesoft.org/schema/mule/ee/dw" xmlns:json="http://www.mulesoft.org/schema/mule/json" xmlns:http="http://www.mulesoft.org/schema/mule/http" xmlns:mulexml="http://www.mulesoft.org/schema/mule/xml" xmlns="http://www.mulesoft.org/schema/mule/core" xmlns:doc="http://www.mulesoft.org/schema/mule/documentation"
xmlns:spring="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans-current.xsd
http://www.mulesoft.org/schema/mule/core http://www.mulesoft.org/schema/mule/core/current/mule.xsd
http://www.mulesoft.org/schema/mule/http http://www.mulesoft.org/schema/mule/http/current/mule-http.xsd
http://www.mulesoft.org/schema/mule/file http://www.mulesoft.org/schema/mule/file/current/mule-file.xsd
http://www.mulesoft.org/schema/mule/xml http://www.mulesoft.org/schema/mule/xml/current/mule-xml.xsd
http://www.mulesoft.org/schema/mule/ee/dw http://www.mulesoft.org/schema/mule/ee/dw/current/dw.xsd
http://www.mulesoft.org/schema/mule/json http://www.mulesoft.org/schema/mule/json/current/mule-json.xsd">
<http:listener-config name="HTTP_Listener_Configuration" host="0.0.0.0" port="8081" doc:name="HTTP Listener Configuration"/>
<flow name="splittersAggregatorsNestedFlow">
<http:listener config-ref="HTTP_Listener_Configuration" path="/splitters/nested" doc:name="HTTP"/>
<set-payload value="#[ [[1,2,3,4], [5,6,7,8], [9,10,11,12]] ]" doc:name="Set Payload"/>
<splitter expression="#[payload]" doc:name="Splitter" />
<flow-ref name="setSplitterVariables" doc:name="Set splitter variables"/>
<logger message="SPLITTER 1: PROCESSING ITEM #[payload]" level="INFO" doc:name="Logger"/>
<flow-ref name="nestedSplitterSubflow" doc:name="Nested splitter subflow"/>
<flow-ref name="setSplitterProperties" doc:name="Set splitter properties"/>
<collection-aggregator failOnTimeout="true" doc:name="Collection Aggregator">
<expression-message-info-mapping messageIdExpression="#[message.id]" correlationIdExpression="#[flowVars.correlationId]"/>
</collection-aggregator>
<json:object-to-json-transformer mimeType="application/json" doc:name="Object to JSON"/>
</flow>
<sub-flow name="setSplitterVariables">
<set-variable variableName="correlationId" value="#[message.correlationId]" doc:name="correlationId"/>
<set-variable variableName="correlationGroupSize" value="#[message.correlationGroupSize]" doc:name="correlationGroupSize"/>
<set-variable variableName="correlationSequence" value="#[message.correlationSequence]" doc:name="correlationSequence"/>
</sub-flow>
<sub-flow name="nestedSplitterSubflow">
<splitter expression="#[payload]" doc:name="Splitter" enableCorrelation="ALWAYS">
<expression-message-info-mapping messageIdExpression="#[message.id]" correlationIdExpression="#[message.correlationId + message.correlationSequence]"/>
</splitter>
<logger message="SPLITTER 2: PROCESSING ITEM #[payload]" level="INFO" doc:name="Logger"/>
<collection-aggregator failOnTimeout="false" doc:name="Collection Aggregator">
<expression-message-info-mapping messageIdExpression="#[message.id]" correlationIdExpression="#[message.correlationId]"/>
</collection-aggregator>
</sub-flow>
<sub-flow name="setSplitterProperties">
<set-property propertyName="#['MULE_CORRELATION_GROUP_SIZE']" value="#[flowVars.correlationGroupSize]" doc:name="correlationGroupSize"/>
<set-property propertyName="#['MULE_CORRELATION_SEQUENCE']" value="#[flowVars.correlationSequence]" doc:name="Property"/>
<set-property propertyName="#['MULE_CORRELATION_ID']" value="#[flowVars.correlationId]" doc:name="Property"/>
</sub-flow>
</mule>xml