Continuous Deployment
You can use the Runtime Manager REST API for continuous deployment to your own on-premises servers, or to other cloud servers (outside of CloudHub). The Runtime Manager REST API enables you to programmatically access much of the functionality provided by Runtime Manager. If you want to implement continuous deployment to CloudHub, see CloudHub REST API.
You can implement the process described here as a task in the continuous deployment pipeline in the following ways:
-
As a shell (for example, Microsoft PowerShell, Bash, and so on)
-
As a script
-
As a Jenkins/Maven Plugin written in Java
For a more complete reference of all the operations, resources, methods, required properties, and expected responses that are supported through the API, see Standalone Runtime Manager API Reference or Runtime Fabric API Reference
A Mule Maven plugin that provides the same capabilities is also available. Therefore, use the process described here as an alternative if you cannot, or do not want, to use the Mule Maven Plugin.
It is advisable to create a dedicated Anypoint Platform account used exclusively for deployment and CI related activities.
Workflow for On-Premises Servers
The workflow explained below can be carried out by various means, depending on your preference, but the steps remain the same. The high-level steps are as follows:
-
The user is signed into Anypoint Platform.
-
Information about the servers, server groups, and clusters that are registered on that account is obtained.
-
An application is deployed to it.
-
The application interfaces with the APIs for access management and Runtime Manager.
The workflow must receive the following input parameters:
-
Username - The Anypoint Platform account username
-
Password - Password for the Anypoint Platform username
-
Environment - The deployment environment (for example, Dev, Test, Prod)
-
Target Name - The name of the target to which to deploy the application
-
Target Type - The type of target (Server, Cluster, ServerGroup, Runtime Fabric)
-
Artifact Name - Name of the Mule application to deploy
-
File - The binary file of the Mule application to deploy
The workflow executes the following API calls in sequence:
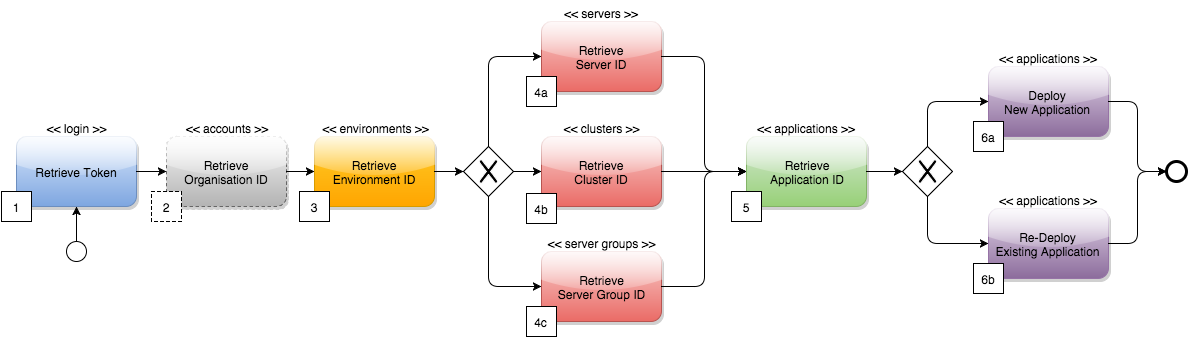
To use the Anypoint Platform Access Management API:
-
Call
/loginon the Access Management API with a valid Anypoint Platform user name and password to obtain theaccess_tokenandtoken_typeto use in all the subsequent calls.If using Jenkins, the Username and Password must be configured in the task. The task has to concatenate the token_typeandaccess_tokenand save them for the duration of the entire workflow process. The fields must be concatenated as follows:token = token_type + " " + access_token, for example:"bearer 895d1a05-ba24-44f2-a9df-3675c1bde97b".
The token in its concatenated form must be passed as a header in every subsequent API call. -
Call
/accountson the Access Management API to retrieve the organizationid.The task must then extract the organization identifier from the location 'user.organisation.id' and save it for later use. This step is not mandatory, as the organization identifier can be passed as a local parameter to the task due to its static nature. -
Call
/environmentson the Access Management API, passing the organizationidretrieved in the previous step and choosing the correct environmentidbased on the relevant environment name (for example,Dev,Test,Production, and so on).The organization idretrieved in Step 2 must be passed as part of the API URI. The environmentidmust be extracted from the path 'data[i].id', where 'data[i].name == inputEnvironment' (it can take values like 'Dev', 'Test', 'Production' or any valid environment name that is set up in your Anypoint Platform).
To use the Standalone Runtime Manager API:
-
Call either
/servers,/clusters, or/serverGroupson the Runtime Manager API, passing the server, cluster, or server group name, as well as the retrieved organizationidand environmentid. This call returns all of the data about this server, cluster, or server group, including thetargetId.This step retrieves the target id, which is then used as a target for the deployment. The task needs to pick up the right server, server group, or cluster identifier based on the target name you set as an input at the beginning of the workflow. The serveridmust be extracted fromdata[i].id, wheredata[i].name == inputTargetName. -
Call
/applicationson the Runtime Manager API, passing the organization’sidand the environment’sid, to retrieve the application’sidand the rest of its data.This step retrieves the application idto determine whether the following step is a new deployment (6a) or a re-deployment (6b). The applicationidmust be extracted from 'data[i].id' where 'data[i].artifact.name == inputArtifactName' and 'data[i].target.id == serverId' / 'clusterId' / 'serverGroupId'. -
Post
/applicationson the Runtime Manager API, passing the organization’sid, the environment’sid, 'artifactName',targetId(retrieved in Step 1 of this section), the Mule application .zip file to deploy and, optionally, the applicationid.
| This step deploys the actual Mule application artifact for the first time to a target environment and server / cluster / server group. Use POST requests if no application identifier was retrieved in Step 2. Use PATCH if an application identifier was retrieved in Step 2, to re-deploy the actual Mule application artifact to a target environment and server / cluster / server group. |
Workflow for On-Premises Runtime Fabric
The workflow explained below can be carried out by various means depending on your preference, but the steps remain the same. The high-level steps are as follows:
-
It first logs your user into the Anypoint Platform
-
Information about the Runtime Fabrics that are registered on that account is obtained
-
An application is deployed to it
-
The application interfaces with the APIs for the MuleSoft Anypoint Platform Access Management and Runtime Manager.
The workflow must receive the following input parameters:
-
Username - The Anypoint Platform account username
-
Password - Password for the Anypoint Platform username
-
Environment - The deployment environment (Dev, Test, Prod, etc.)
-
Target Settings - The type (ie: MC), name of the target to which to deploy the application, and settings
-
Exchange Reference - Reference of the Mule application to deploy in Exchange
-
Application Configuration - The application configurations for the deployment
The workflow executes the following API calls in sequence.
Using the Maven Tool
-
Publish the artifact to the Exchange Assets Manager using Maven.
This step is required to ensure high availability when failure occurs in the target and the Control Plane needs to re-deploy artifacts for recovery.
To use the Anypoint Platform Access Management API:
-
Call
/loginon the Access Management API with a valid Anypoint Platform user name and password to obtain theaccess_tokenandtoken_typeto use in all the subsequent calls.If using Jenkins, the Username and Password must be configured in the task. The task has to concatenate the token_typeandaccess_tokenand save them for the duration of the entire workflow process. The fields must be concatenated as follows:token = token_type + " " + access_tokenfor example:"bearer 895d1a05-ba24-44f2-a9df-3675c1bde97b".
The token, in its concatenated form, must be passed as a header in every subsequent API call.
-
Call
/accountson the Access Management API to retrieve the organizationid.The task must then extract the organization identifier from the location 'user.organisation.id' and save it for later use. This step is not mandatory, as the organization identifier can be passed as a local parameter to the task due to its static nature. -
Call
/environmentson the Access Management API, passing the organizationidretrieved in the previous step and choosing the correct environmentidbased on the relevant environment name (for example,Dev,Test,Production).The organization idretrieved in Step 2 must be passed as part of the API URI. The environmentidmust be extracted from the path 'data[i].id', where 'data[i].name == inputEnvironment' (it can take values like 'Dev', 'Test', 'Production', or any valid environment name that is set up in your Anypoint Platform).-
Using the Application Manager API:
-
-
Call deployments on the Application Manager API, passing the organization’s
idand the environment’sid, to retrieve the application’sidand the rest of its data.This step retrieves the application idto determine whether the following step is a new deployment (6a) or a re-deployment (6b). The applicationidmust be extracted fromdata[i].id, wheredata[i].artifact.name == inputArtifactName' and `data[i].target.targetId == `targetId`. -
Post
/deploymentson the Application Manager API, passing the organization’sid, the environment’sid,applicationName,labels,targetdeployment settings (including the target id retrieved in Step 1 of this section), the Exchange reference of the published Mule application 'application' to deploy, the applicationconfiguration, and optionally the applicationid.
This step deploys the actual Mule application artifact for the first time to a target environment and Runtime Fabric. Use POST requests if no application identifier was retrieved in step 2. Use PATCH if an application identifier was retrieved in step 2 to re-deploy.
|