Runtime Manager の監視ダッシュボード
Anypoint Runtime Manager の監視ダッシュボードには、デプロイされたアプリケーションとデプロイ先のシステムの両方の使用状況メトリクスの詳細が表示されます。
Anypoint Platform Private Cloud Edition では、Anypoint の監視ダッシュボード機能はサポートされていません。
ダッシュボードを表示するには、Runtime Manager の「Read Application (アプリケーションの参照)」権限または Runtime Manager の「Read Servers (サーバーの参照)」権限が必要です。
Anypoint Runtime Manager には以下のダッシュボードがあります。
-
デプロイメント対象や状況など、アプリケーションに関する情報を表示します。
Runtime Manager は、組み込みとクラシックの 2 種類のアプリケーションダッシュボードインターフェースを提供しています。表示されるダイアログボックスは、選択したアプリケーションのバージョン、種別、デプロイメント方法によって異なります。
-
ヒープメモリと CPU のパーセンテージや、詳細なメモリ使用状況メトリクスなど、サーバーに関する高レベル情報を表示します。
-
グループまたはクラスター内で選択されたサーバーの集計メトリクスを表示します。
これらのダッシュボードから収集した情報を使用して、以下を行うことができます。
-
アプリケーションとサーバーのアラートを設定し、いずれかのメトリクスが長時間にわたって重大値を示すと自動的に通知されるようにします。
-
失敗の根本原因の分析、パフォーマンスのボトルネックの特定、会社の手続きに準拠しているかどうかのテストにインサイトを活用します。
アプリケーション監視ダッシュボード
![]()
![]()
![]()
![]()
アプリケーション監視ダッシュボードは、統合されたアプリケーションに関する次のような質問に答えるのに役立ちます。
-
使用量のピークが発生したのいつか?
-
高トラフィックのピークが応答時間に与える影響は?
-
アプリケーションの背後の処理能力はこれらの高トラフィックのピークに適切に対処できているか?
-
高トラフィックのピークがメッセージの失敗率に与える影響は?
-
同じサーバーで実行されている他のアプリケーションの高トラフィックのピークが、特定のアプリケーションのパフォーマンスに与える影響は?
ワーカーの再起動後は、CPU とメモリの情報はダッシュボードには表示されません。これらの情報を維持するには、dashboardStats API を使用してください。または、Anypoint Monitoring で Titanium サブスクリプションを使用することで、このデータを保存できます。
|
組み込み Anypoint Monitoring ダッシュボード
Anypoint Monitoring ダッシュボードは、クラシックアプリケーション監視ダッシュボードよりも多くの監視メトリクスを提供し、いろいろな種類のグラフを表示する複数のページがあります。
このダイアログボックスは、選択したアプリケーションが以下の場合に表示されます。
-
CloudHub または Runtime Fabric にデプロイされている
-
Mule 3.8.7-AM または 3.9.0 以降で実行されている
-
Anypoint Monitoring が有効になっている
詳細については、Anypoint Monitoring ドキュメントの「組み込みアプリケーションダッシュボード」を参照してください。
クラシックアプリケーション監視ダッシュボード
クラシックアプリケーション監視ダッシュボードは、Mule メッセージ、CPU、およびメモリのメトリクスを表示します。
このダイアログボックスは、選択したアプリケーションが以下の場合に表示されます。
-
CloudHub にデプロイされている
-
3.8.7 より前の Mule バージョンで実行されている
-
オンプレミスでデプロイされている (ハイブリッド)
ハイブリッドアプリケーションでは、監視が有効で、過去 24 時間に渡って監視された CPU メトリクスが存在する場合にダッシュボードが表示されます。
-
監視が有効化されていない
アプリケーション監視ダッシュボードにアクセスする
アプリケーションの監視ダッシュボードにアクセスしたときに表示されるダイアログボックスは、選択したアプリケーションのバージョン、種別、デプロイメント方法によって異なります。
アプリケーション監視ダッシュボードにアクセスするには、次の手順を実行します。
-
Runtime Manager で [Applications (アプリケーション)] をクリックします。
-
監視するアプリケーションの名前を選択します。
アプリケーション監視ダッシュボードの操作
表示しているダッシュボードの右上隅にある目的の期間を選択することで、異なる時間範囲でグラフを表示できます。
-
組み込み Anypoint Monitoring ダッシュボード:

-
クラシックアプリケーション監視ダッシュボード

選択された各時間範囲の時間単位を下表に示します。
グラフに表示される平均、最小、最大: 選択された時間範囲
Mule メッセージ数
エラー数
応答時間 (ミリ秒)
3 時間
毎分
毎分
毎分
24 時間
8 分ごと
8 分ごと
8 分ごと
7 日間
毎時
毎時
毎時
2 週間
2 時間ごと
2 時間ごと
2 時間ごと
アプリケーションが同時に複数のワーカーで実行される場合は、異なる色で区別した曲線として、同じグラフ上に表示されます。
アプリケーションがサーバーグループまたはクラスターで実行されている場合は、グループまたはクラスターに含まれるサーバーの集計メトリクスが 1 本の折れ線として各グラフに表示されます。メトリクスを個々のサーバーレベルで表示するには、個々のサーバーのダッシュボードを参照してください。サーバーで複数のアプリケーションが実行中の場合、表示されるのはサーバーの総合的なパフォーマンスで、実行中のアプリケーションごとに区別されません。
サーバー監視ダッシュボード
![]()
![]()
サーバー監視ダッシュボードは、ヒープメモリと CPU のパーセンテージや、詳細なメモリ使用状況メトリクスなど、サーバーに関する高レベル情報を表示します。
アプリケーション監視ダッシュボードにアクセスする
サーバー監視ダッシュボードにアクセスするには、次の手順を実行します。
-
Runtime Manager で [Servers (サーバー)] をクリックします。
-
監視するサーバーの名前を選択します。
サーバーのダッシュボードが表示されます。
サーバーの監視ダッシュボードには、サーバーが含まれるサーバーグループダッシュボードまたはクラスターダッシュボードから移動することもできます。
サーバー監視ダッシュボードの操作
サーバー監視ダッシュボードでは、メトリクスを 2 つのタブで表示します。
-
サーバーのメモリと CPU の使用量を概要レベルで表示します。
-
サーバーメモリの各部を別々に追跡する詳細なメトリクスを表示します。
表示しているダッシュボードの右上隅にある目的の期間を選択することで、異なる時間範囲でグラフを表示できます。
グラフ上にマウスポインターを置くことで、その時点で発生したアクティビティに関する数値の詳細がフロート表示されます。
サーバーで複数のアプリケーションが実行されている場合は、アプリケーションのチェックボックスをオンにすることで右側にデータの詳細ペインを表示して、別々のグラフセットで各アプリケーションのパフォーマンスを確認できます。
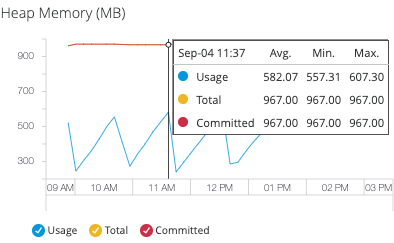
ダッシュボードのメモリ使用量のグラフは以下の値を追跡します。
-
使用量
現在使用中のメモリの量 (MB 単位)。
Java VM が使用メモリを増量してコミット済みメモリよりも大きくしようとすると、使用量が合計未満であっても、メモリの割り当てが失敗します。
-
Total (合計)
サーバーが使用できるメモリの最大量 (MB 単位)。最大量は変動するか、または未定義の場合があります。
-
Committed (コミット済み)
Java VM で使用できるメモリの量 (MB 単位)。この量は時間と共に変動します。コミット済みメモリの量は、常に使用メモリの量以上になります。
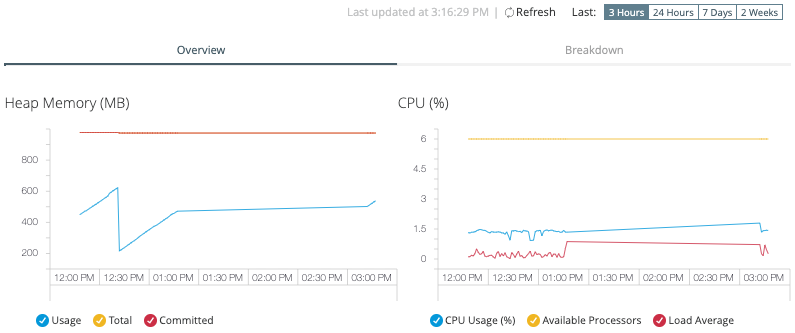
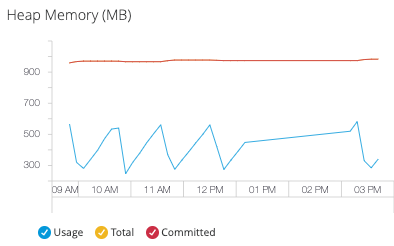
Overview (概要) タブ
[Overview (概要)] タブのグラフには、メモリと CPU の使用量に高レベルのメトリクスが表示されます。
- ヒープメモリ
-
合計ヒープメモリ使用量 (MB 単位)。
-
ヒープメモリの使用量
-
メモリ合計
-
コミット済みヒープメモリ
ヒープメモリの各コンポーネントの詳細は、Breakdown (詳細分析) タブを参照してください。
-
- CPU
-
Windows ではこのメトリクスは使用できません。
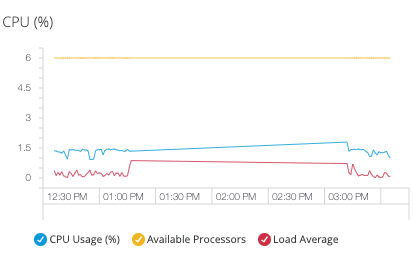
サーバーの合計 CPU 使用量:
-
CPU 使用量
-
Available Processors (使用可能なプロセッサー)
-
Load Average (負荷平均)
-
[CPU Usage (CPU 使用量)] は、サーバーの使用済み処理容量を示すパーセンテージ値です。 [Available Processors (使用可能なプロセッサー)] は、サーバーで使用可能なプロセッサー数を示す整数値です。 CPU 負荷とは、サーバーの CPU によって実行されている、または実行を待機しているタスクの数です。 [Load Average (負荷平均)] は、指定された期間の実行中、または CPU 時間の割り当てを待機中のプロセスの平均数を示す整数値です。
Breakdown (詳細分析) タブ
[Breakdown (詳細分析)] タブのグラフは、サーバーメモリの各部を別々に追跡する詳細なメトリクスを表示します。
-
ヒープメモリメトリクスは、JVM ヒープを構成するサーバーメモリ部分に関連します。
-
非ヒープメモリメトリクスは、JVM ヒープの外側に存在するメモリを指します。
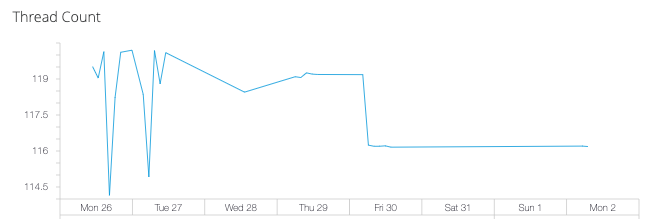
- Thread Count (スレッド数)
-
個々の Java スレッド数の推移。
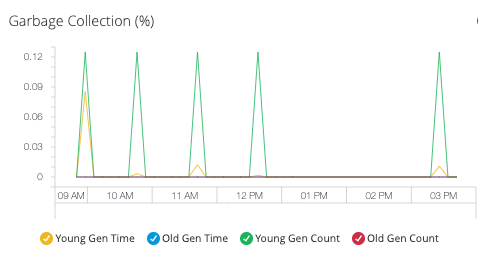
- ガベージコレクション
-
ヒープの以下の領域のメトリクス:
-
Young Generation (新世代)、すべての新しいオブジェクトが割り当てられます。
-
Old Generation (旧世代)、存続しているオブジェクトが格納されます。
-
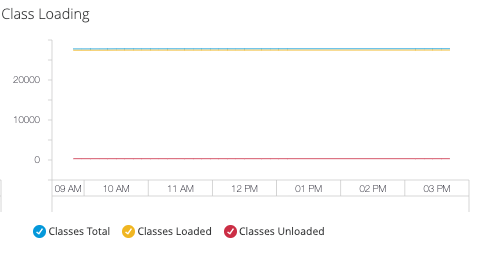
- Class Loading (クラスローディング)
-
JVM にあるすべてのアプリケーションを合計した、現在ロード済みまたはロード中のクラスの量:
- Eden
-
ほとんどのオブジェクトに最初に割り当てられるメモリが含まれているヒープ領域内のプール。
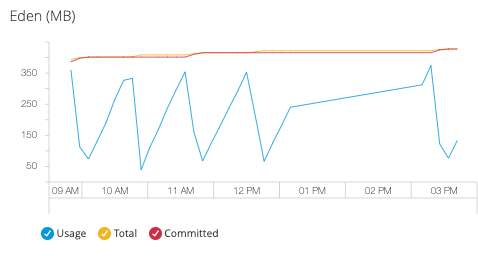
- Survivor
-
Eden 領域のガベージコレクションを耐え抜いたオブジェクトが含まれているヒープ内のプール。
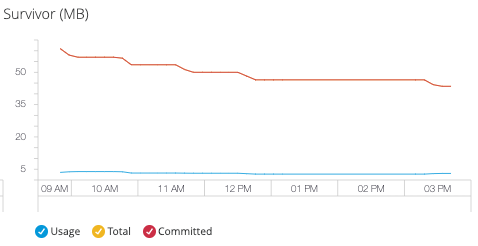
- Old Gen (旧世代)
-
Survivor 領域内にしばらく存在したオブジェクトが含まれているヒープ内のプール。
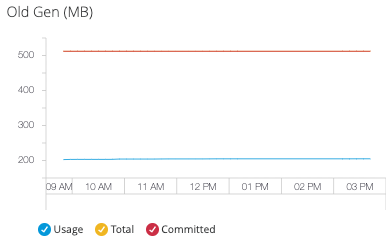
- Code Cache (コードキャッシュ)
-
ネイティブコードのコンパイルと保存に使用されるメモリが含まれる領域。
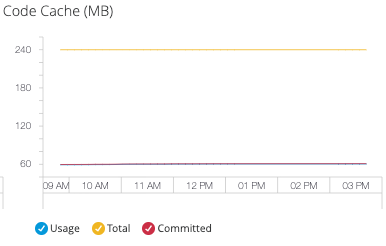
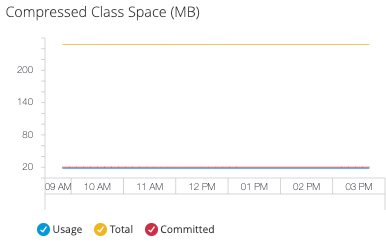
- Compressed Class Space (圧縮クラス領域)
-
このメトリクスは、JDK 8+ を使用する場合にのみ使用できます。
- Metaspace (メタ領域)
-
クラスのメタデータの表現にネイティブメモリが使用される JVM のメモリ領域。
このメトリクスは、JDK 8+ を使用する場合にのみ使用できます。
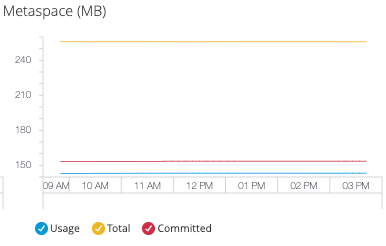
現時点のメタ領域の上限は 256 MB です。
サーバーグループまたはクラスター監視ダッシュボード
![]()
![]()
サーバーグループまたはクラスター監視ダッシュボードを使用すると、グループまたはクラスター内のサーバーの集計メトリクスを表示できます。
サーバーグループまたはクラスター監視ダッシュボードには、以下の集計メトリクスが表示されます。
-
CPU usage (CPU 使用量) (最大量に対する割合)
-
Memory usage (メモリ使用量) (MB 単位)
-
Heap total (ヒープ合計) (MB 単位)
選択されたサーバーの集計メトリクスは、1 本の折れ線として各グラフに表示されます。