ERP Docs With AWS
The ERP Docs with AWS enables you to use Amazon Textract to analyze invoices and receipts to extract relevant data.
Inbound Variables
-
Directory Path
-
File Name
-
Password
-
Read text from page
-
Read text to page
-
AWS Credentials
Or, if Use custom settings is activated in the wizard:
-
Client Id
-
Client Secret
-
Session Token
-
Use Session Token
-
Region Endpoint
-
-
Json Path
Outbound Variables
-
Raw Text
The extracted raw text of the document.
-
Normalized Json
The parsed result based on the normalized result and defined Json path.
-
Raw Json
The complete AWS response.
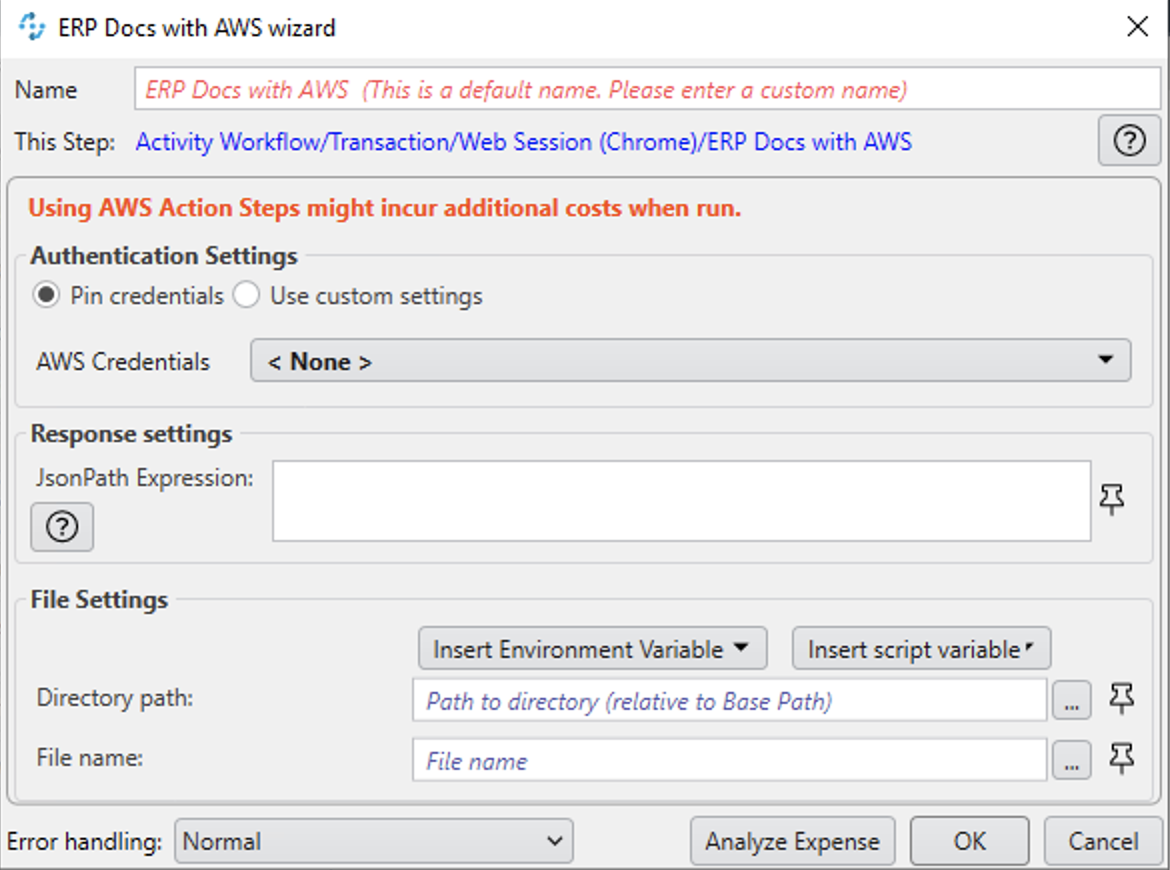
Wizard
-
Authentication Settings
The AWS credentials to use for authentication
-
Pin credentials
Use this option to reference an existing Credentials for AWS configuration.
-
Use custom settings
Use this option to specify an AWS Cliend ID, Client Secret, and Region Endpoint for this action step.
-
Session Token
The session token to use for authentication when Use session token to authenticate is selected.
-
-
Response settings
-
JsonPath Expression
The Json path to the property of the response object.
-
-
File Settings
-
Directory path
The path to the directory where the file is located.
-
File name
The name of the file to analyze. Supported file types: PDF, JPEG, and PNG.
-
-
PDF Settings
These settings show when the selected file is a PDF.
-
PDF file is password protected
Specifies if the selected PDF file is password protected. When selected, specify the password to open the file in the Password to open PDF file filed.
-
Read entire file
Instructs the OCR service to read the entire file.
-
Read page range
Instructs the OCR service to read the selected range of pages.
-
From page
Specify from which page the OCR service starts reading the file.
-
To page
Specifies until which page the OCR service reads the file.
-
Read to end of file
Instructs the OCR service to continue reading until the end of the file.
-
-