Excel Format
MIME type: application/xlsx
ID: excel
An Excel workbook is a sequence of sheets. In DataWeave, this is mapped to an object where each sheet is a key. Only one table is allowed per Excel sheet. A table is expressed as an array of rows. A row is an object where its keys are the columns and the values the cell content.
|
Only |
The DataWeave reader for Excel input supports the following parsing strategies:
-
In-Memory
-
Streaming
To understand the parsing strategies that DataWeave readers and writers can apply to this format, see DataWeave Parsing Strategies.
Excel Type Mapping
The following table shows how Excel types map to DataWeave types.
| Excel Type | DataWeave Type |
|---|---|
|
|
|
|
|
|
|
|
Examples
The following examples show uses of the Excel format.
Example: Represent Excel in the DataWeave (dw) Format
This example shows how DataWeave represents an Excel workbook.
Input
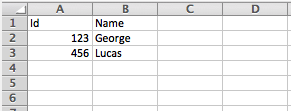
The Excel workbook (Sheet1) serves as an input payload for the DataWeave source.
. | A | B 1 | Id | Name 2 | 123 | George 3 | 456 | Lucas
Example: Output an Excel Table
The following DataWeave script outputs an Excel table with the header and fields.
The body of this DataWeave script is a DataWeave object that defines the content of the Excel sheet. The name of the sheet, Sheet1, is the key of this object. The value is an array of objects. Each object in the array contains a collection of key-value pairs. The keys in each pair are treated as header values for the
spreadsheet. The values in each pair are treated as data values for a row in the sheet.
The output directive indicates that the output is the Excel format and MIME type. The header=true setting indicates that the output includes the header values.
%dw 2.0
output application/xlsx header=true
---
{
Sheet1: [
{
Id: 123,
Name: George
},
{
Id: 456,
Name: Lucas
}
]
}For another example, see Look Up Data in an Excel (XLSX) File.
Example: Stream Excel Input
By default, the Excel reader stores input data from an entire file in-memory
if the file is 1.5MB or less. If the file is larger than 1.5 MB, the process
writes the data to disk. For very large files, you can improve the performance
of the reader by setting a streaming property to true.
The following Configuration XML for a Mule application streams an Excel file and transforms it to JSON.
<http:listener-config
name="HTTP_Listener_config"
doc:name="HTTP Listener config" >
<http:listener-connection host="0.0.0.0" port="8081" />
</http:listener-config>
<flow name="streaming_flow" >
<http:listener
doc:name="Listener"
config-ref="HTTP_Listener_config"
path="/"
outputMimeType="application/xlsx; streaming=true"/>
<ee:transform doc:name="Transform Message" >
<ee:message >
<ee:set-payload ><![CDATA[%dw 2.0
output application/json
---
payload."Sheet Name" map ((row) -> {
foo: row.a,
bar: row.b
})]]></ee:set-payload>
</ee:message>
</ee:transform>
</flow>The example:
-
Configures the HTTP listener to stream the XLSX input by setting
outputMimeType="application/xlsx; streaming=true". In the Studio UI, you can use the MIME Type on the listener toapplication/xlsxand the Parameters for the MIME Type to Keystreamingand Valuetrue. -
Uses a DataWeave script in the Transform Message component to iterate over each row in the XLSX payload (an XLSX sheet called
"Sheet Name") and select the values of each cell in the row (usingrow.a,row.b). It assumes columns namedaandband maps the values from each row in those columns intofooandbar, respectively.
Limitations
-
Macros are currently not supported.
-
Charts are ignored.
-
Pivot tables are not supported.
-
Formatting is currently not supported.
Configuration Properties
DataWeave supports the following configuration properties for this format.
Reader Properties
This format accepts properties that provide instructions for reading input data.
| Parameter | Type | Default | Description |
|---|---|---|---|
|
|
|
Indicates whether the first line of the output contains header field names. Valid values are |
|
|
|
Ignores an empty line by default. Valid values are |
|
|
|
Sets the maximum number of bytes a single entry in a ZIP file can have. |
|
|
|
Sets the ratio between de- and inflated bytes to detect zip bomb. For example, if you set the value to 1 percent (= 0.01d) when the compression is better than 1 percent for any given read package part, the parsing fails to indicate a zip bomb. |
|
|
|
Streams input when set to Valid values are |
|
|
|
Position of the last column in each row. Accepts a pattern |
|
|
|
Sets the position of the first cell. Accepts the pattern |
|
|
|
Turns off the zip bomb (decompression bomb) check when set to Valid values are |
Writer Properties
This format accepts properties that provide instructions for writing output data.
| Parameter | Type | Default | Description |
|---|---|---|---|
|
|
|
Size of the buffer writer, in bytes. The value must be greater than |
|
|
|
Generates the output as a data stream when set to Valid values are |
|
|
|
Indicates whether the first line of the output contains header field names. Valid values are |
|
|
|
Ignores an empty line by default. Valid values are |
|
|
|
Sets the maximum number of bytes a single entry in a ZIP file can have. |
|
|
|
Sets the ratio between de- and inflated bytes to detect zip bomb. For example, if you set the value to 1 percent (= 0.01d) when the compression is better than 1 percent for any given read package part, the parsing fails to indicate a zip bomb. |
|
|
|
Sets the position of the first cell. Accepts the pattern |
|
|
|
Turns off the zip bomb (decompression bomb) check when set to Valid values are |